Tree-structured Parzen Estimators (TPE)
Tree-structured Parzen Estimators (TPE) model the search space by splitting observed configurations into two groups based on a quantile threshold: those with scores above the threshold (“good”) and those below (“bad”). It then fits a separate kernel density estimator (KDE) to each group and scores candidate positions by the ratio l(x)/g(x), where l is the density under the good model and g the density under the bad model. Because the KDEs operate on each parameter dimension independently, TPE handles categorical and discrete parameters without requiring any special encoding.
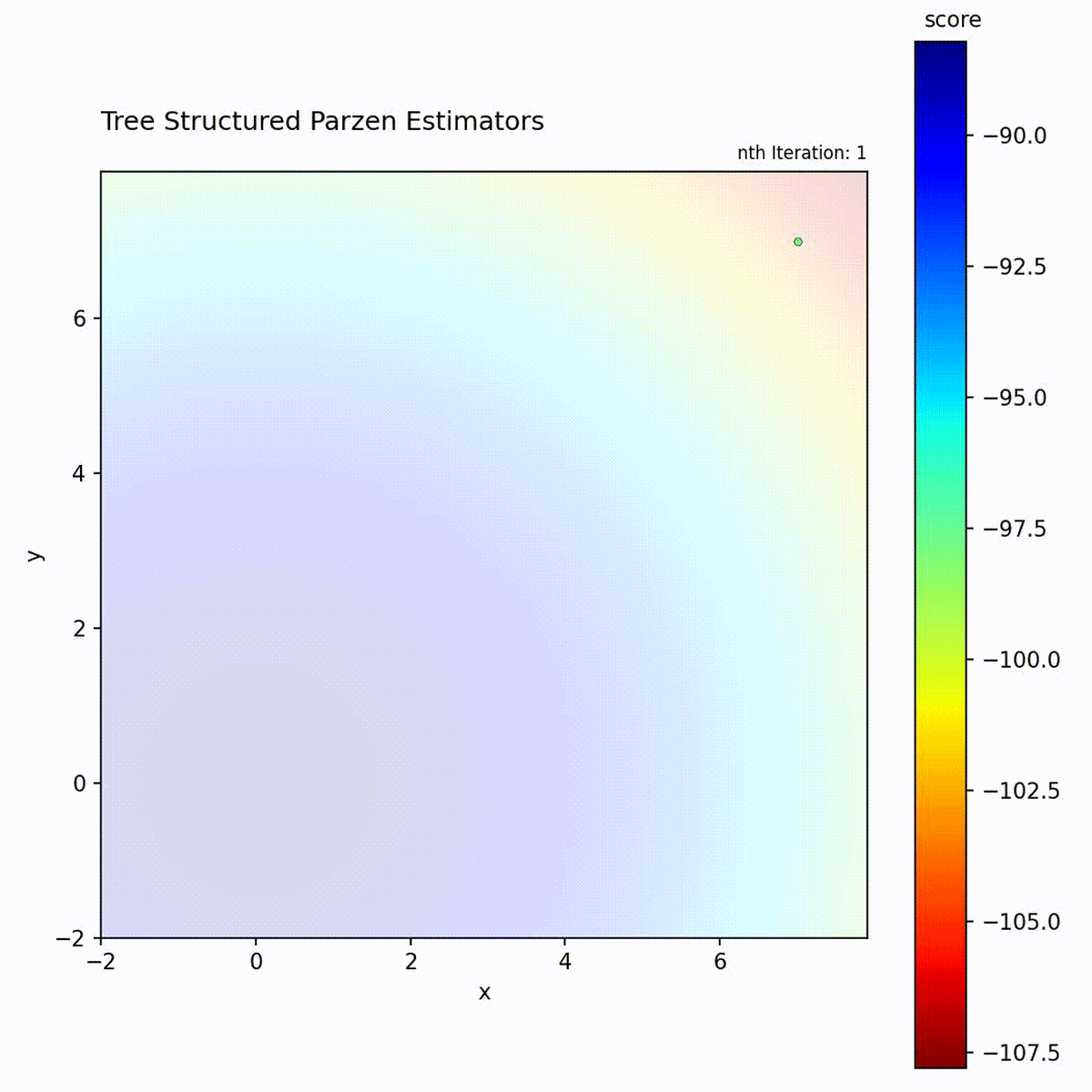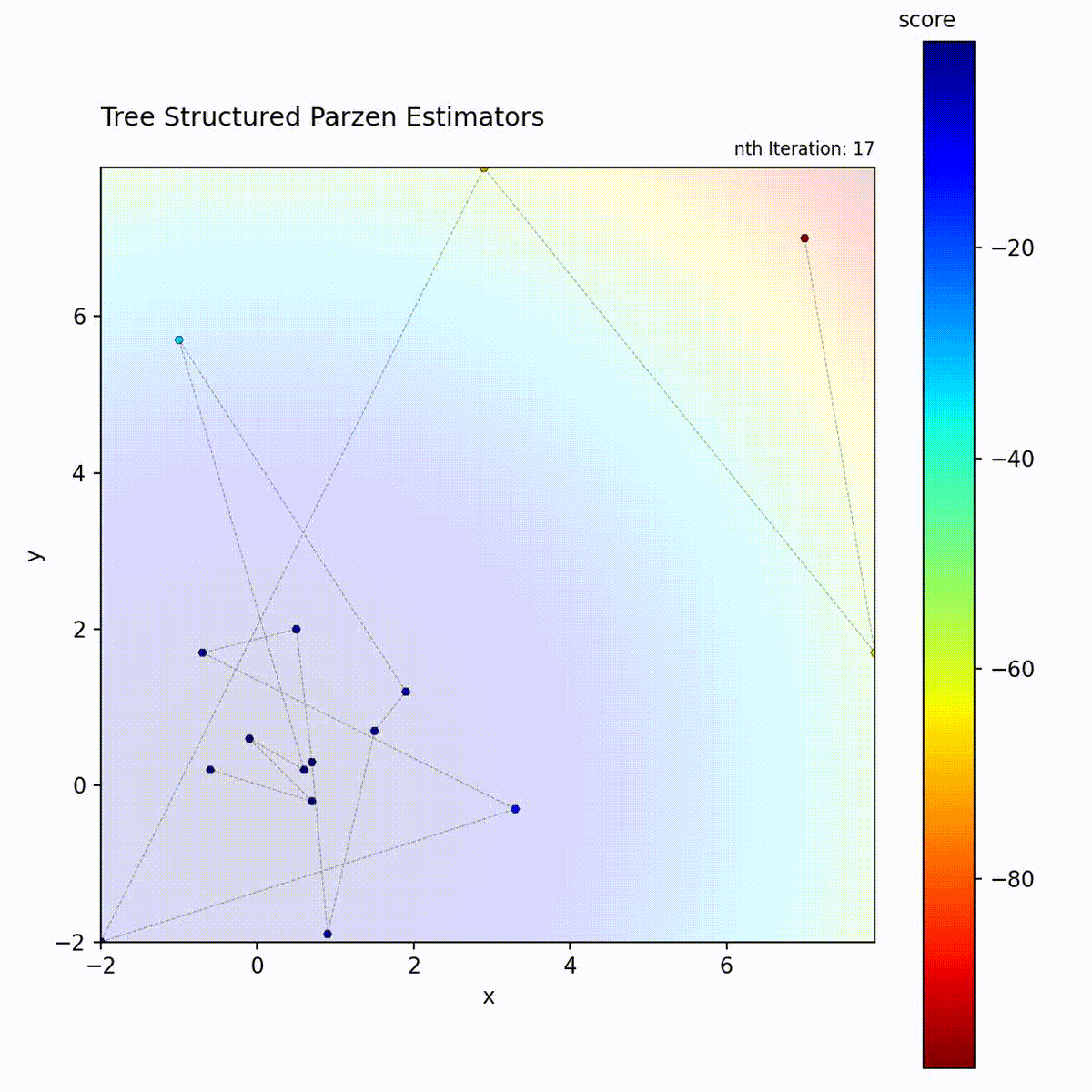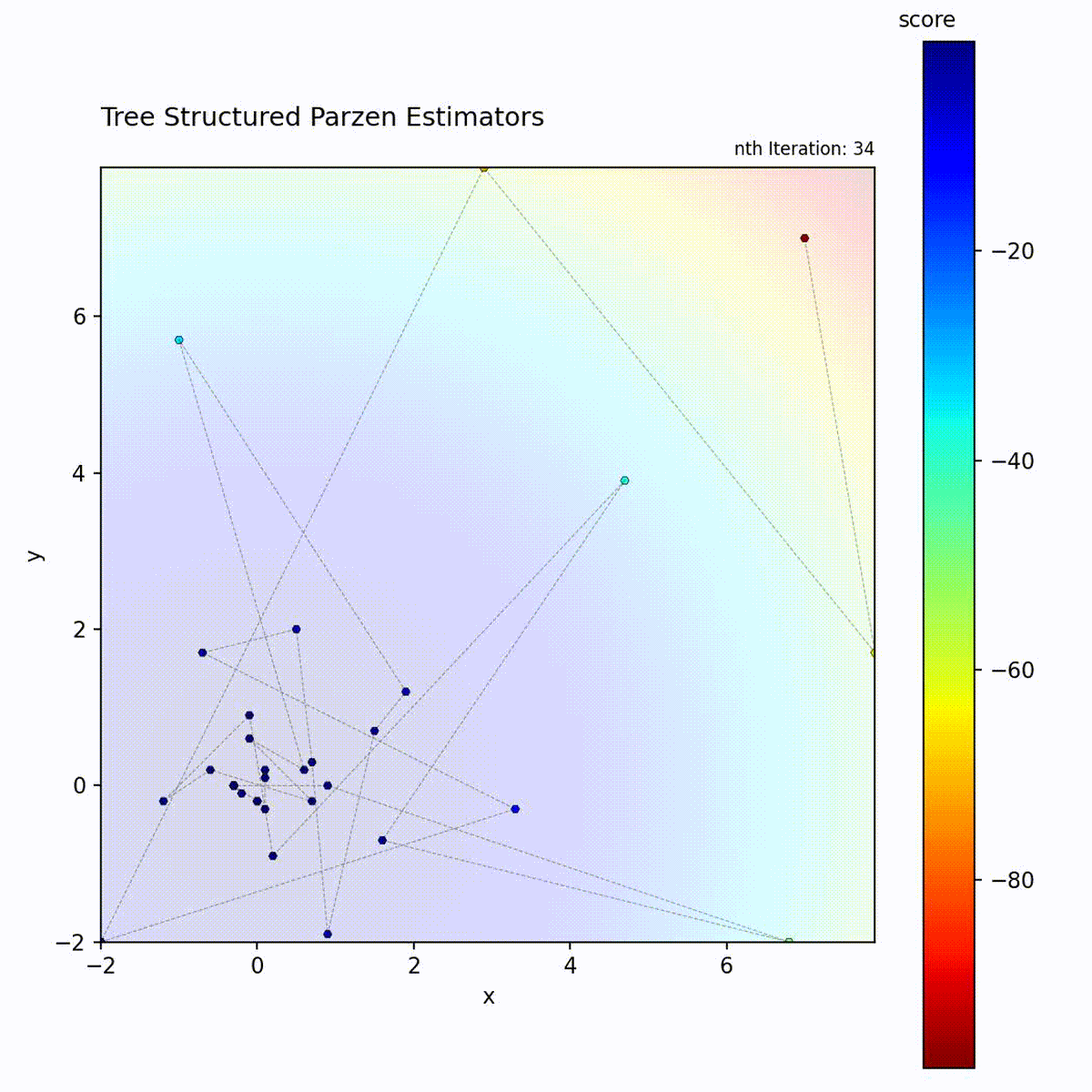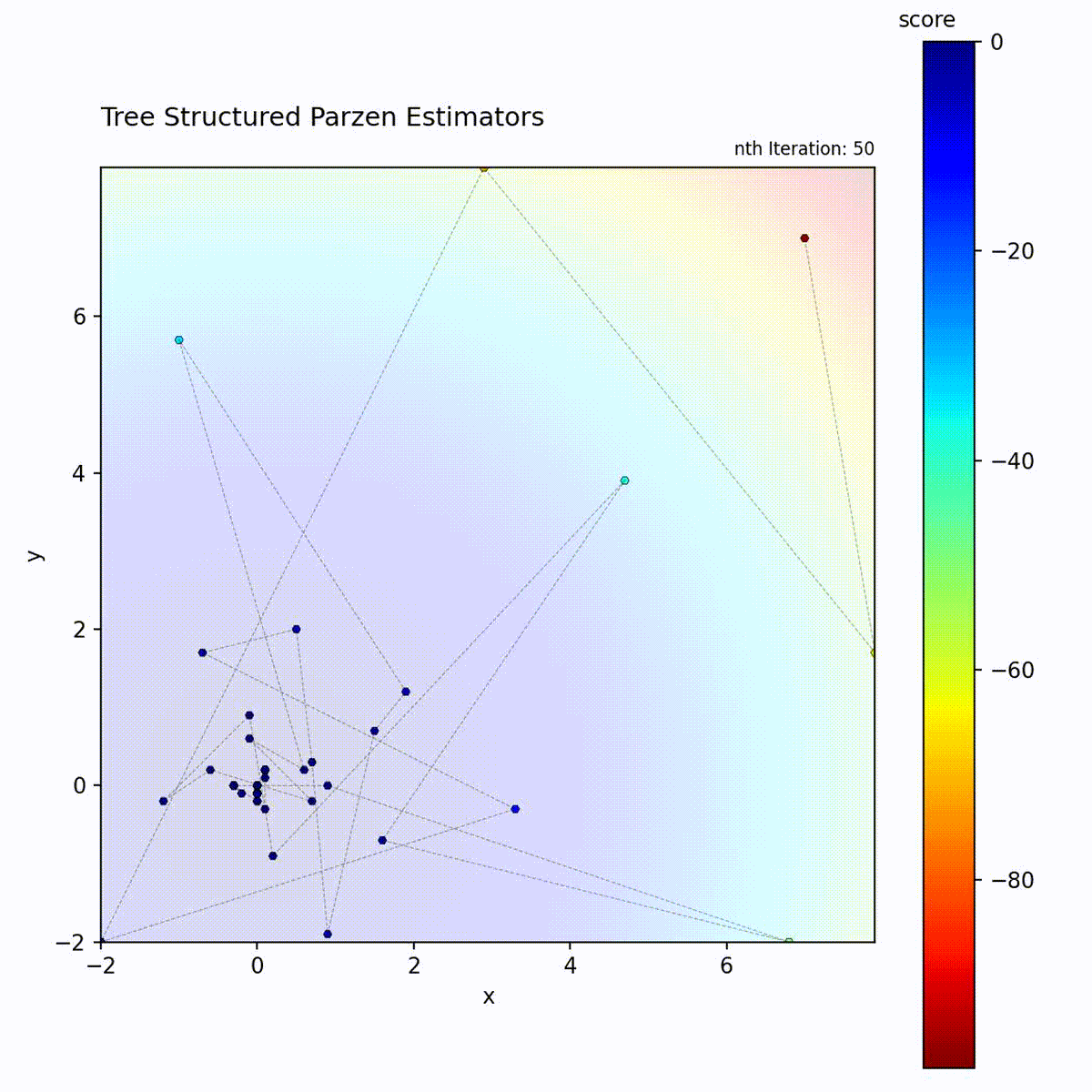
Convex function: Density model quickly focuses on the optimum region.
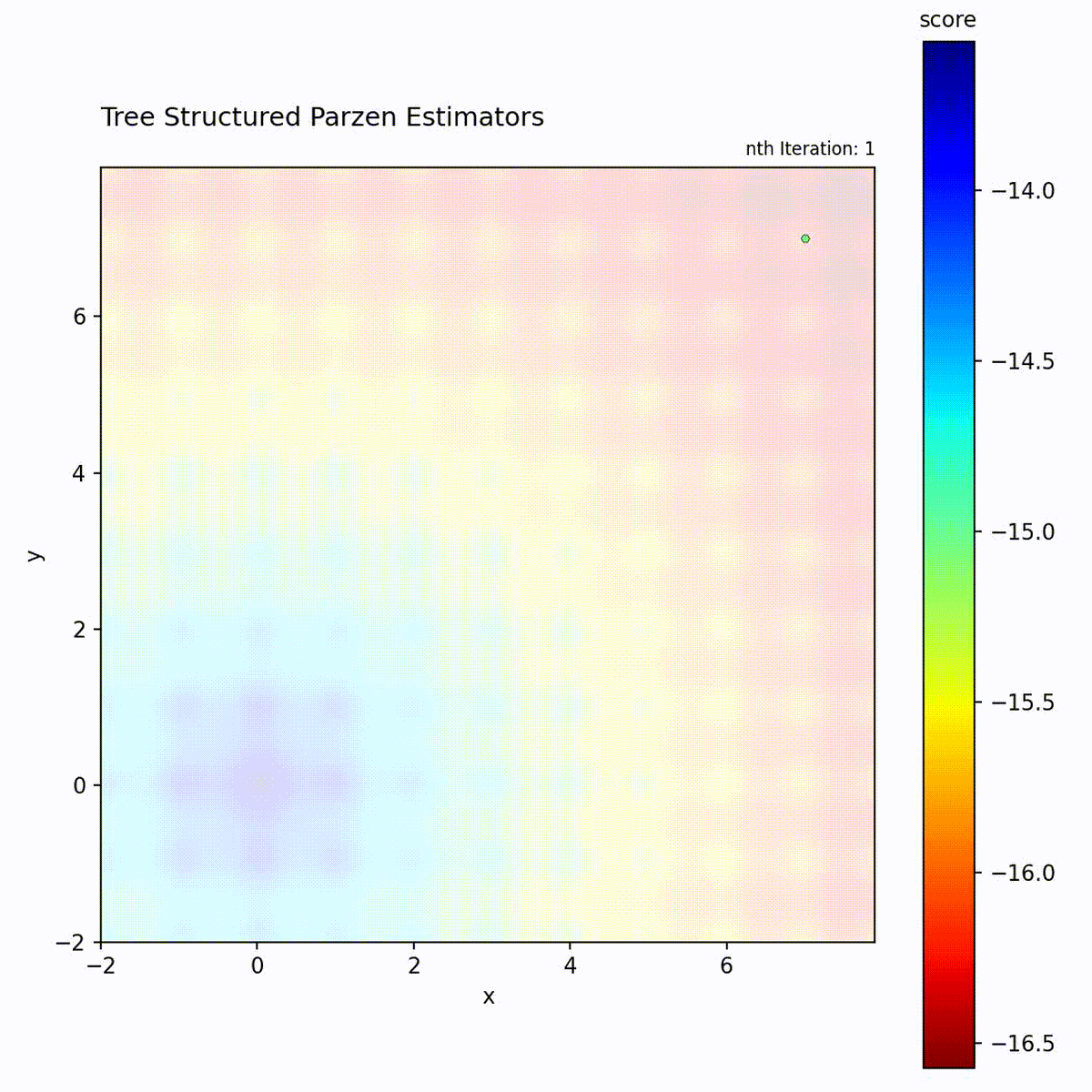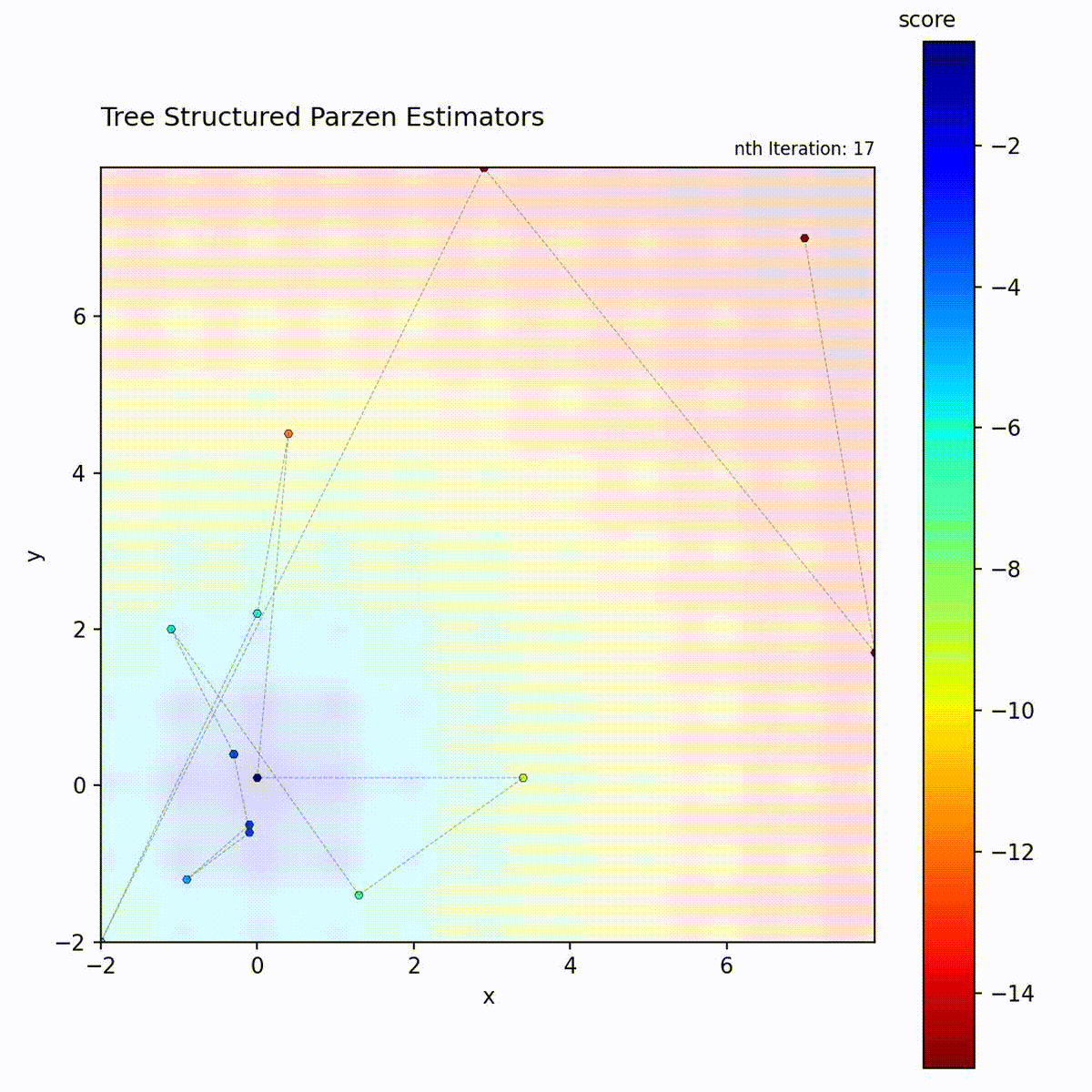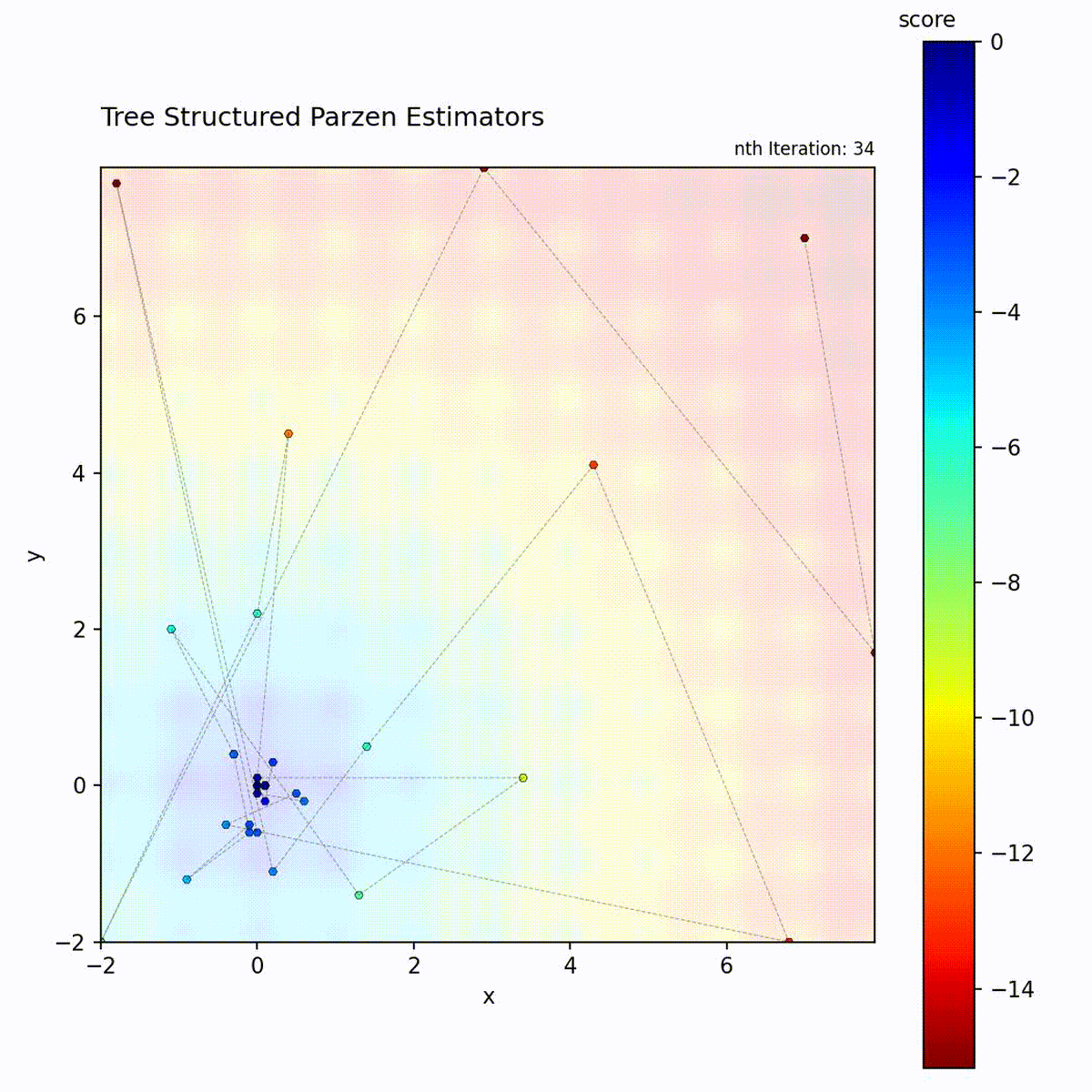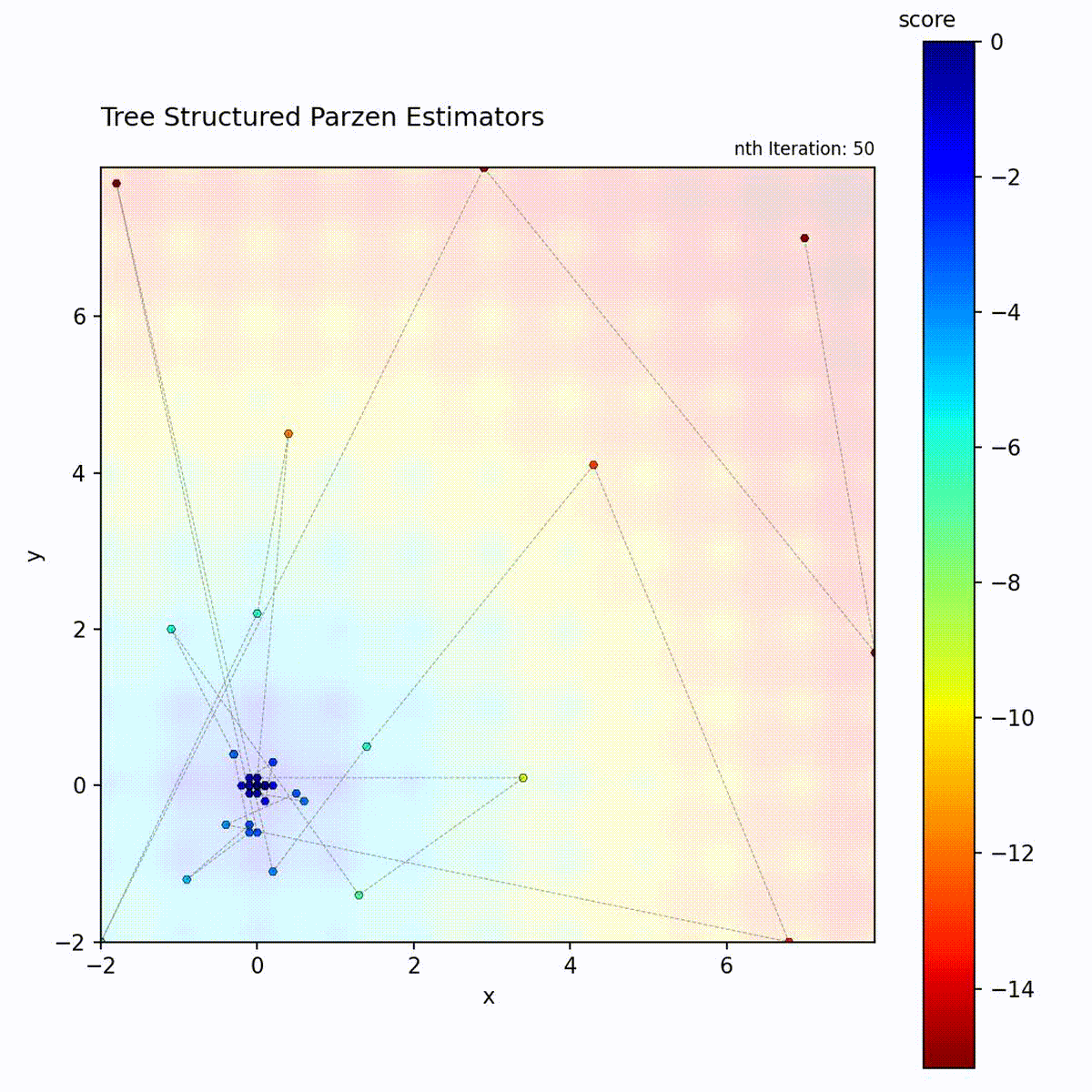
Multi-modal function: Good/bad density separation handles multiple basins.
Compared to Bayesian Optimization, TPE scales linearly in the number of observations rather than cubically, making it practical for larger evaluation budgets. Its per-dimension density modeling is a natural fit for search spaces that mix continuous, discrete, and categorical parameters. Forest Optimizer offers similar scaling properties but uses a direct function model rather than density separation; the choice between the two depends on whether per-dimension independence (TPE) or inter-parameter interaction modeling (Forest) is more important for the problem at hand.
Algorithm
Unlike Bayesian Optimization which models f(x) directly, TPE models:
l(x): Density of parameters where f(x) < threshold (good)
g(x): Density of parameters where f(x) >= threshold (bad)
The acquisition function is:
EI(x) ~ l(x) / g(x)
Points are selected where the ratio is high (likely good, unlikely bad).
Note
TPE inverts the modeling problem. Instead of modeling
P(score | parameters) like a GP, it models P(parameters | good) and
P(parameters | bad). This inversion is what makes TPE naturally handle
categorical and conditional parameters: kernel density estimation works on
each parameter independently, so discrete choices are just multinomial
distributions rather than requiring special encoding.
The threshold (gamma_tpe) that separates “good” from “bad” observations
controls how selective the model is. This approach:
Works naturally with categorical parameters
Handles conditional dependencies
Scales better than GP to many observations
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
float |
0.2 |
Fraction of observations considered “good” |
|
float |
0.03 |
Exploration-exploitation trade-off |
The gamma_tpe Parameter
Lower gamma (0.1): Only top 10% are “good”, more selective
Higher gamma (0.3): Top 30% are “good”, more permissive
# Very selective (only best 10%)
opt = TreeStructuredParzenEstimators(search_space, gamma_tpe=0.1)
# More permissive (best 30%)
opt = TreeStructuredParzenEstimators(search_space, gamma_tpe=0.3)
Example
import numpy as np
from gradient_free_optimizers import TreeStructuredParzenEstimators
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
def objective(para):
clf = RandomForestClassifier(
n_estimators=para["n_estimators"],
max_depth=para["max_depth"],
criterion=para["criterion"],
random_state=42,
)
return cross_val_score(clf, X, y, cv=5).mean()
search_space = {
"n_estimators": np.arange(10, 200, 10),
"max_depth": np.arange(2, 20),
"criterion": np.array(["gini", "entropy"]), # Categorical!
}
opt = TreeStructuredParzenEstimators(search_space)
opt.search(objective, n_iter=50)
print(f"Best accuracy: {opt.best_score:.4f}")
print(f"Best params: {opt.best_para}")
When to Use
Good for:
Mixed continuous, discrete, and categorical spaces
Hyperparameter optimization with many categoricals
When you have conditional parameters
Larger evaluation budgets (scales better than GP)
Compared to Bayesian Optimization:
TPE: Better for categoricals, faster for many observations
BO: Better uncertainty quantification, often better for pure continuous
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import TreeStructuredParzenEstimators
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_wine
X, y = load_wine(return_X_y=True)
def objective(para):
clf = GradientBoostingClassifier(
n_estimators=para["n_estimators"],
max_depth=para["max_depth"],
learning_rate=para["learning_rate"],
subsample=para["subsample"],
random_state=42,
)
return cross_val_score(clf, X, y, cv=3).mean()
search_space = {
"n_estimators": np.arange(50, 300, 10),
"max_depth": np.arange(2, 12),
"learning_rate": np.linspace(0.01, 0.3, 30),
"subsample": np.linspace(0.5, 1.0, 10),
}
opt = TreeStructuredParzenEstimators(
search_space,
gamma_tpe=0.15,
)
opt.search(objective, n_iter=60)
print(f"Best accuracy: {opt.best_score:.4f}")
print(f"Best params: {opt.best_para}")
Trade-offs
Exploration vs. exploitation: Controlled by
gamma_tpe. Lower values make the “good” density more selective, focusing on exploitation. Higher values include more observations in the “good” group, broadening exploration.Computational overhead: O(n) per iteration for density estimation, much lighter than GP’s O(n^3). This makes TPE practical for hundreds of evaluations.
Parameter sensitivity:
gamma_tpe=0.2is a well-tested default. The algorithm is relatively robust to this choice.xiprovides additional fine-tuning of exploration pressure.