Particle Swarm Optimization
Particle Swarm Optimization (PSO) maintains a population of particles that move through the search space using velocity vectors. Each particle’s velocity is updated at every iteration as a weighted sum of three components: its current momentum (inertia), the direction toward its own personal best position (cognitive term), and the direction toward the global best position found by any particle (social term). The resulting trajectory balances individual memory with collective information sharing, producing coordinated movement across the search space.
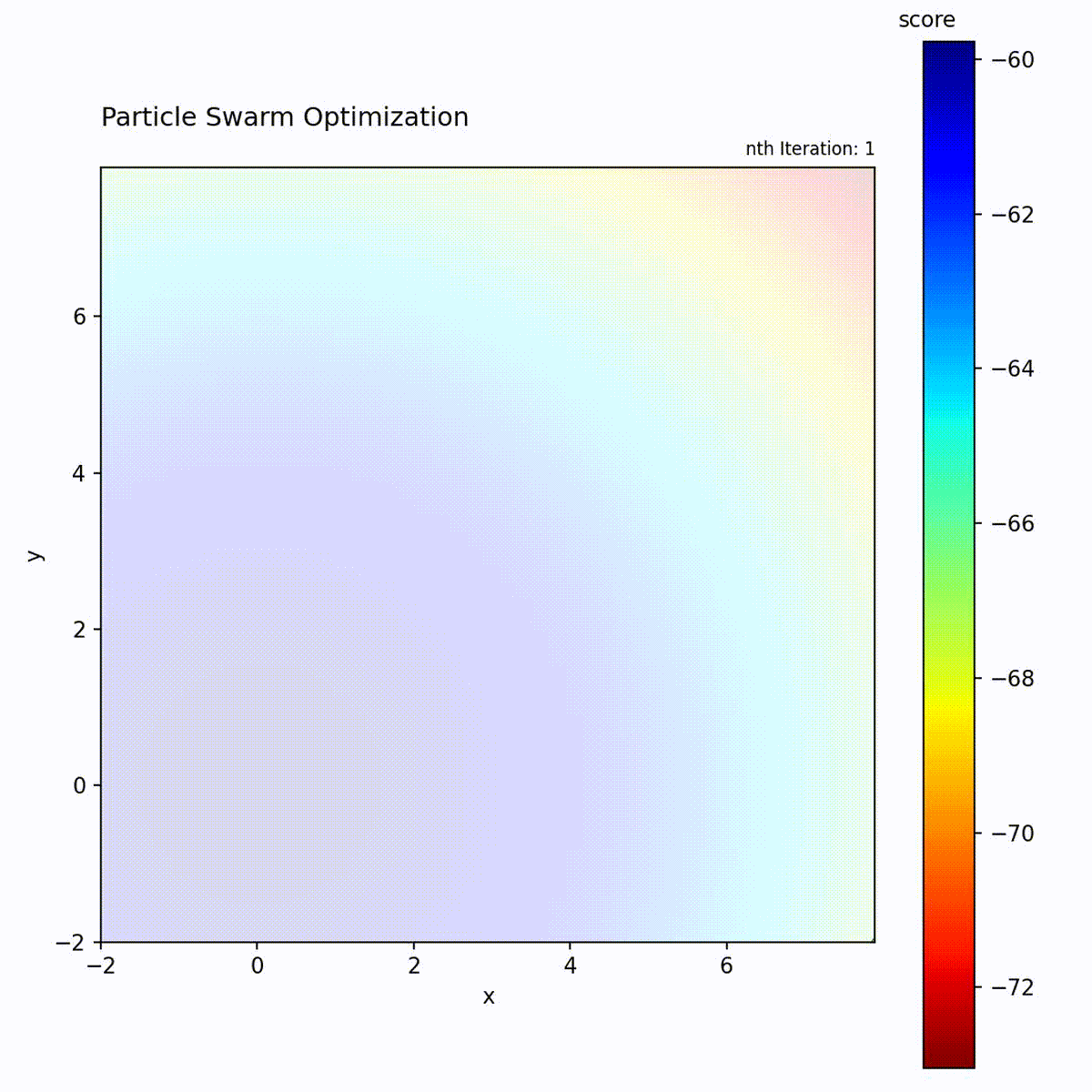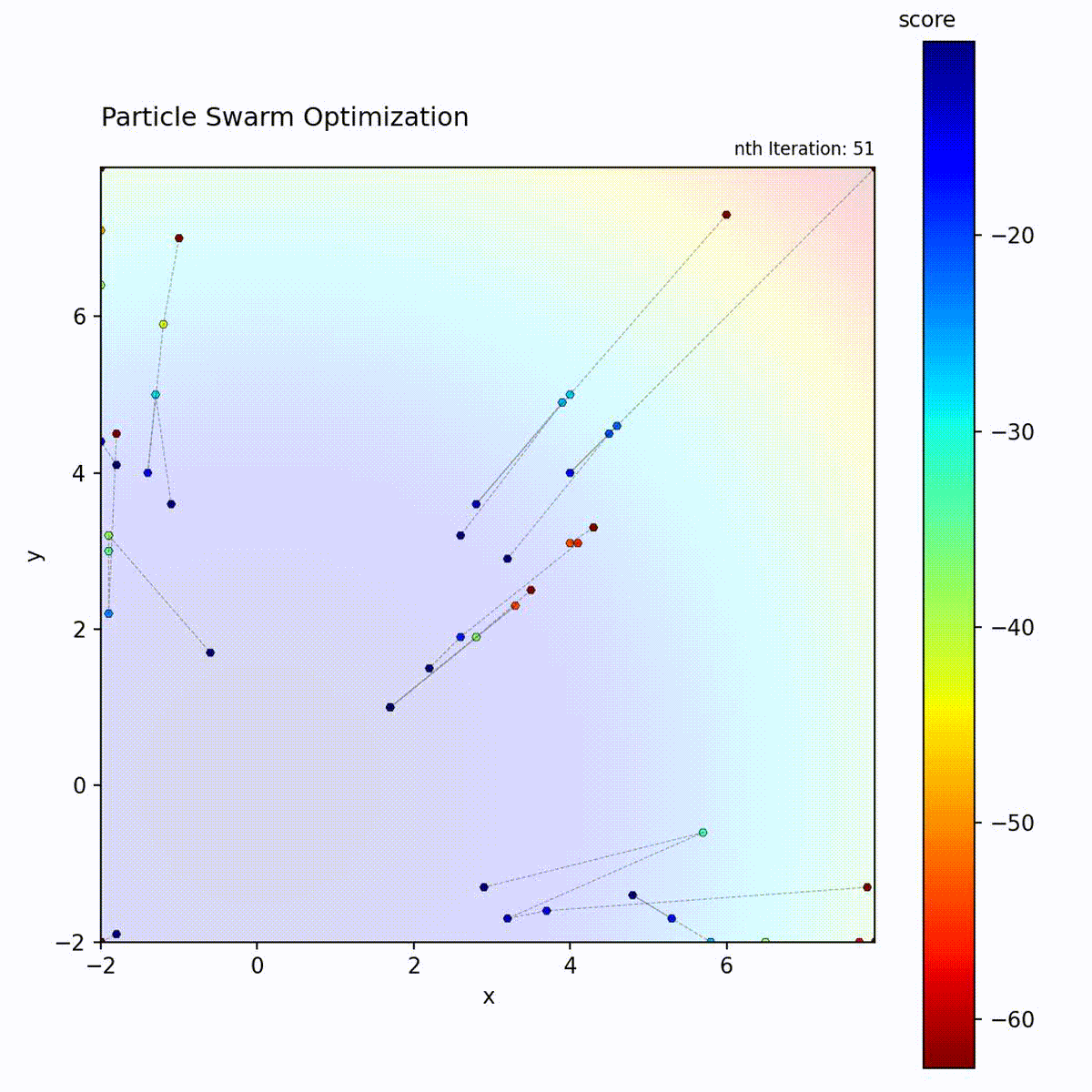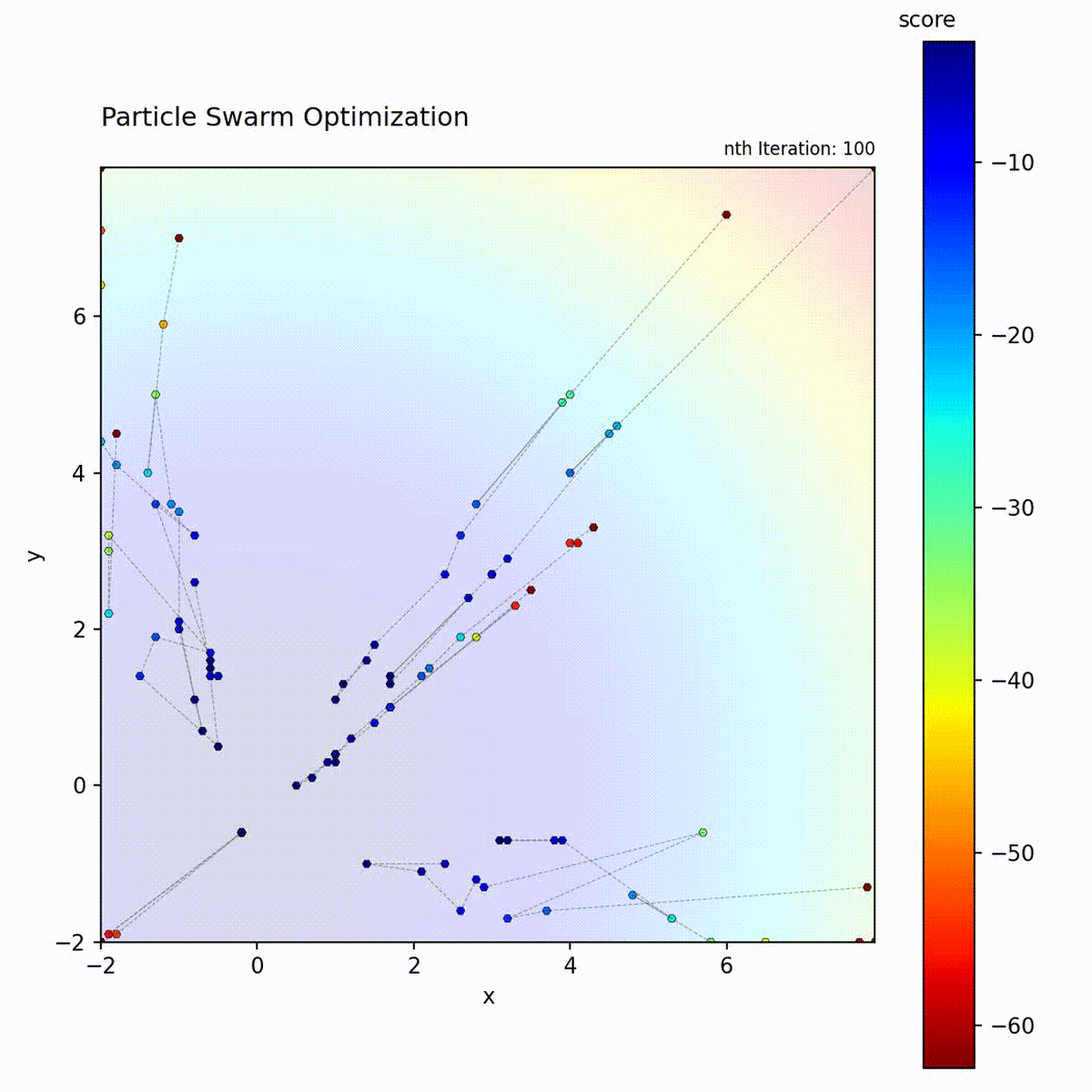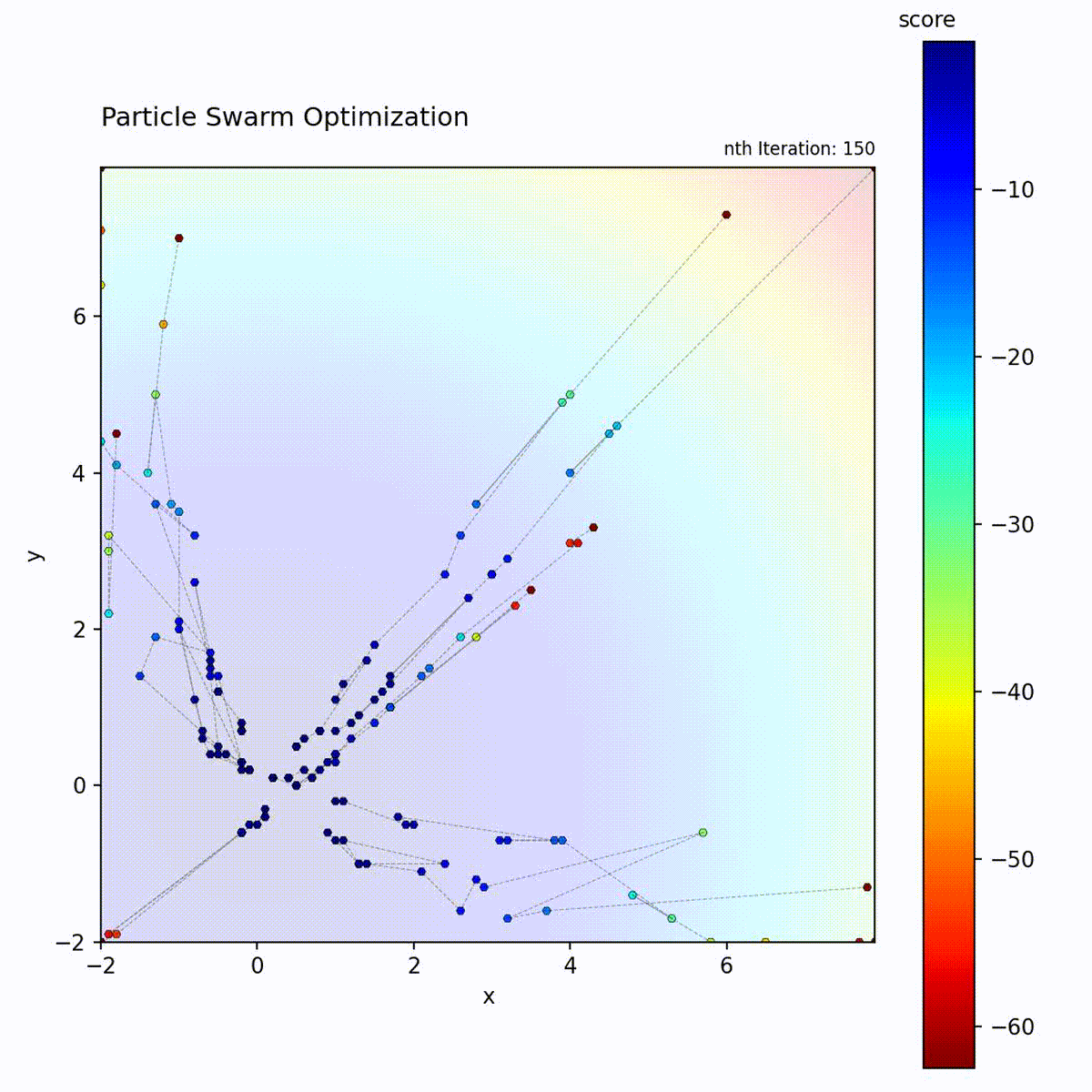
Convex function: Particles quickly converge toward the optimum.
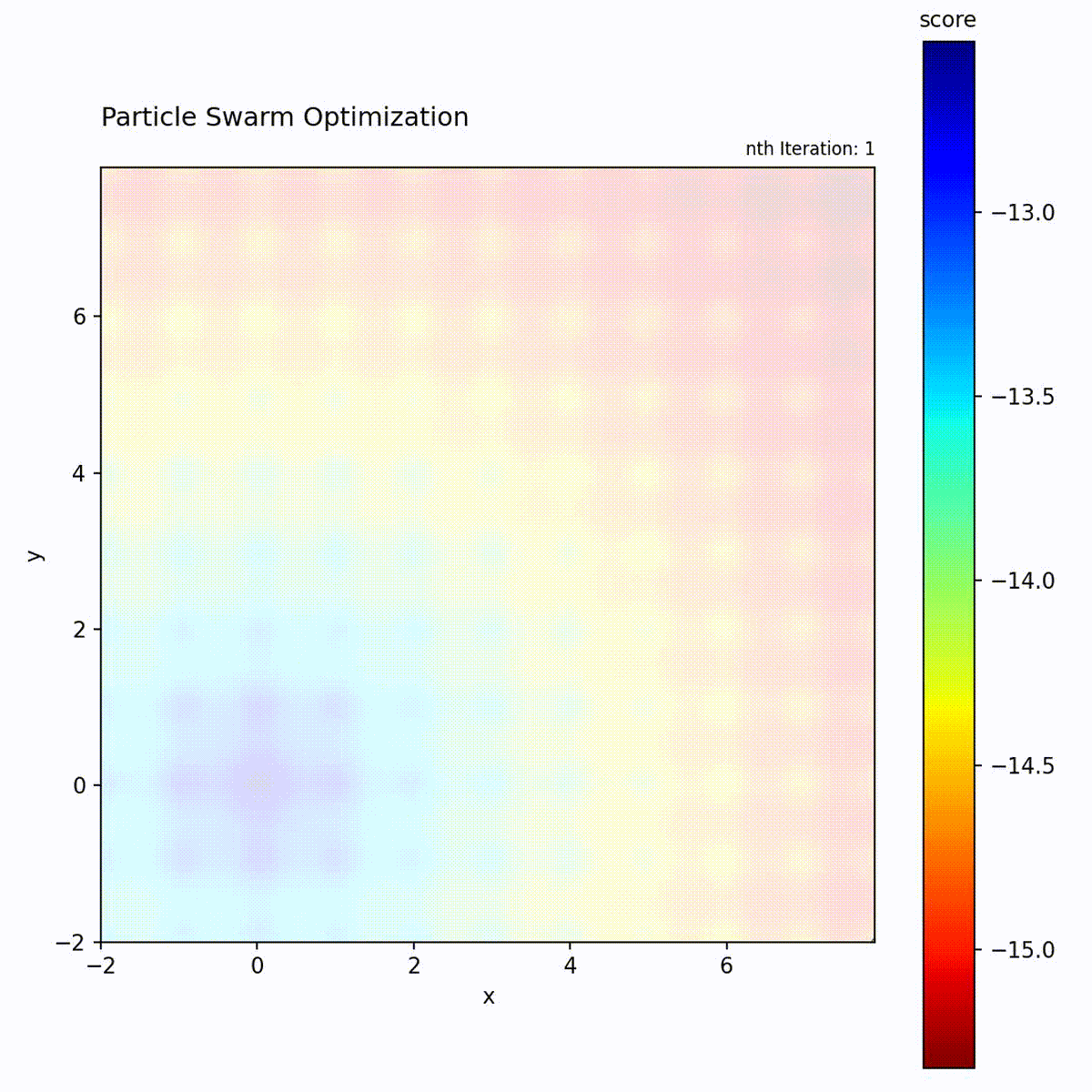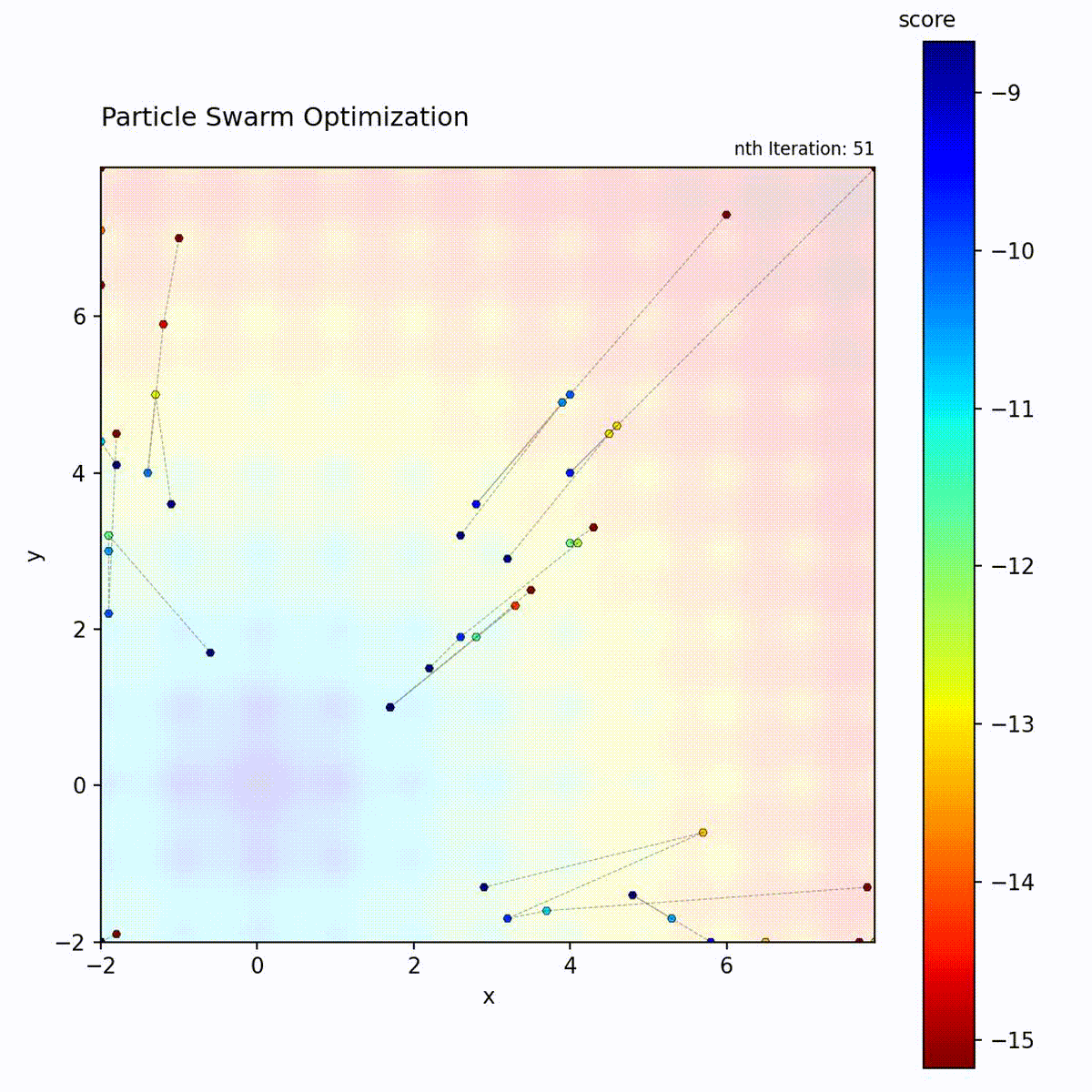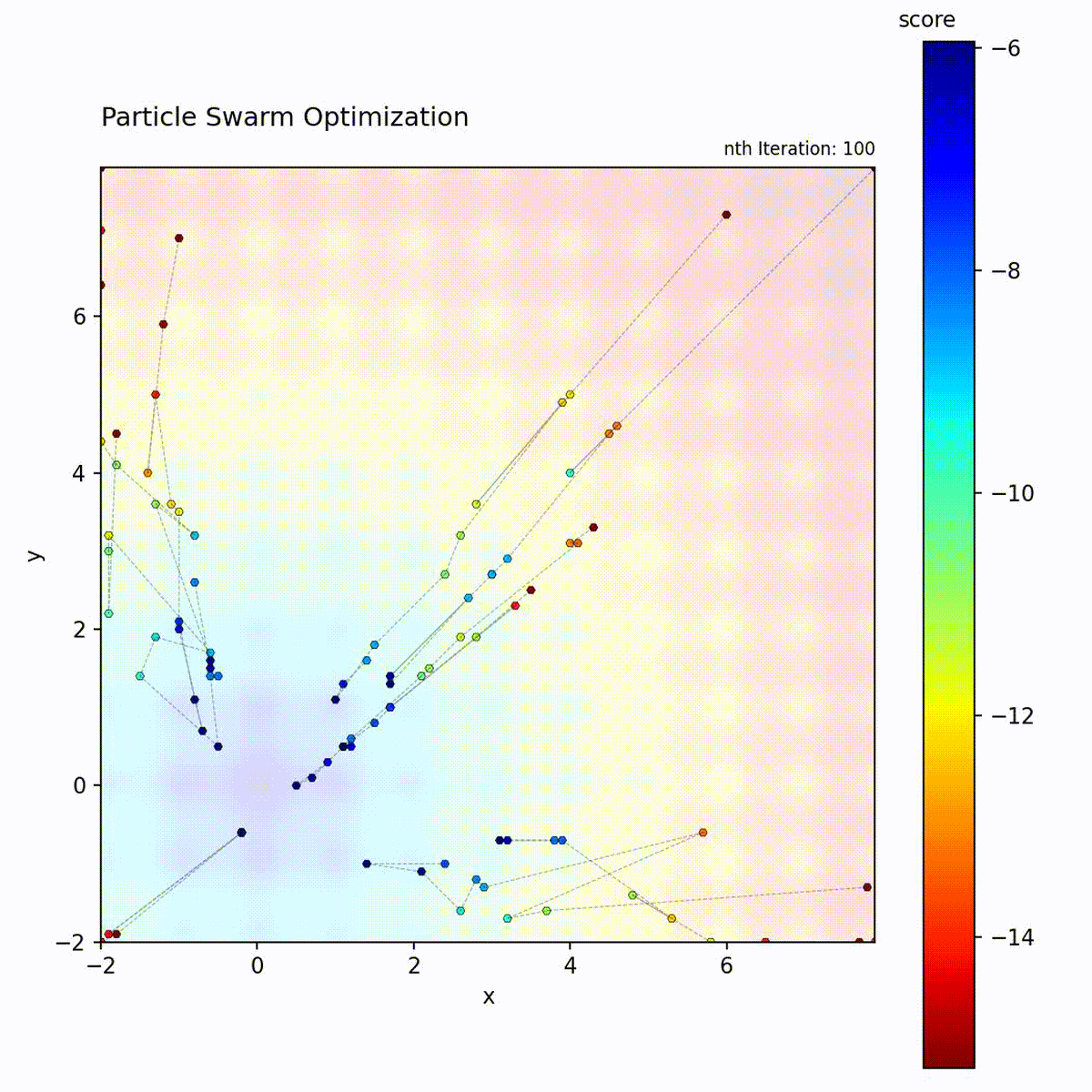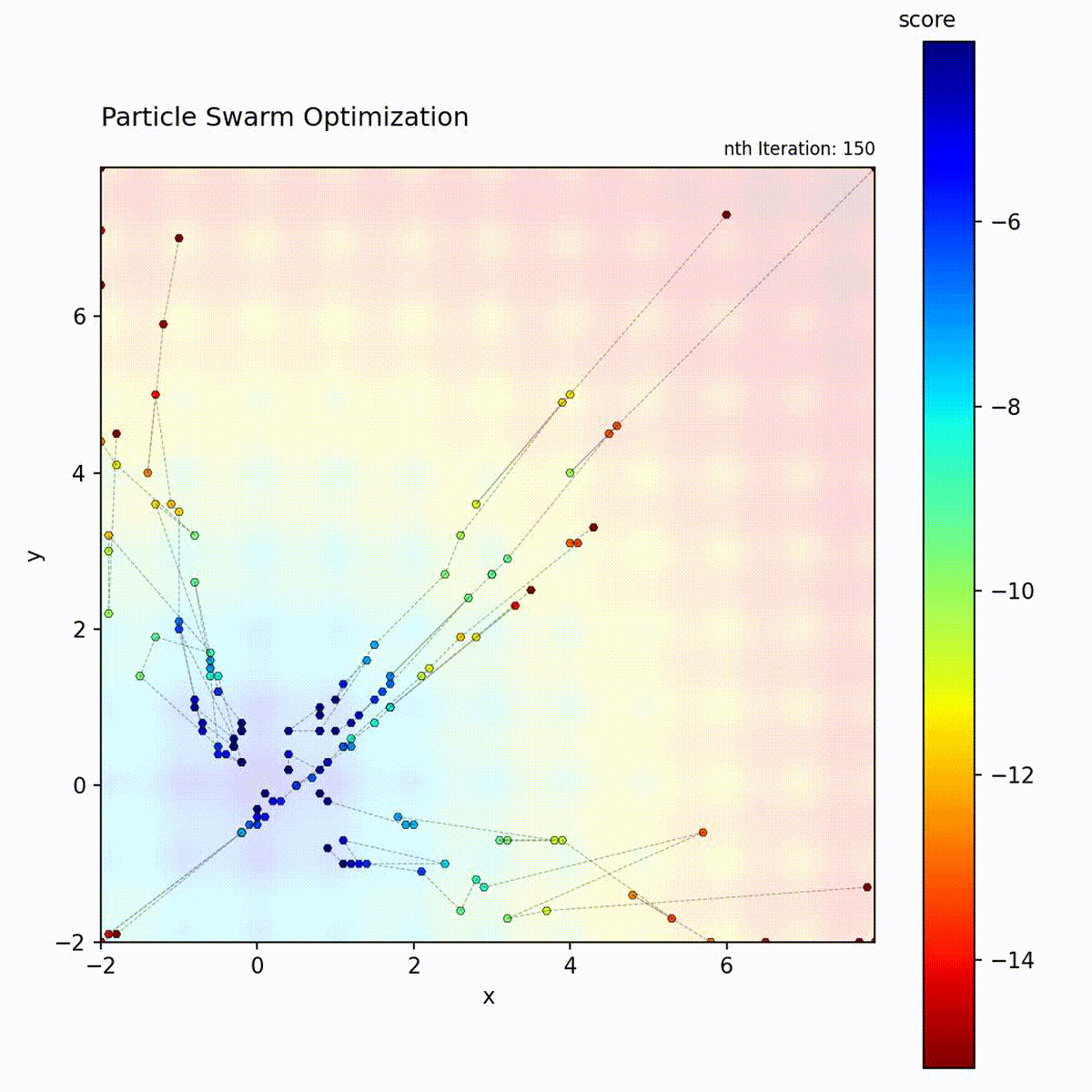
Multi-modal function: Swarm explores multiple regions before converging.
Unlike the evolutionary algorithms in this library (Genetic Algorithm, Evolution Strategy, Differential Evolution), PSO does not use crossover, mutation, or selection operators. Its search is driven entirely by velocity updates, which makes it a good default choice for continuous optimization problems where the landscape is smooth or moderately multi-modal. PSO converges faster than evolutionary methods on unimodal and low-dimensional problems, but its reliance on a single global attractor can cause premature convergence on highly deceptive landscapes. For discrete or categorical search spaces, Genetic Algorithm is generally more appropriate.
Algorithm
Each particle maintains:
Position: Current location in search space
Velocity: Direction and speed of movement
Personal best: Best position this particle has found
Global best: Best position any particle has found (shared)
At each iteration, velocity is updated:
velocity = inertia * velocity
+ cognitive_weight * random * (personal_best - position)
+ social_weight * random * (global_best - position)
Then position is updated:
position = position + velocity
Note
The three velocity components create a balance: inertia preserves the current trajectory (momentum), cognitive weight pulls toward each particle’s own discovery (independence), and social weight pulls toward the swarm’s best (cooperation). The ratio between cognitive and social weights determines whether the swarm behaves more like independent explorers or a coordinated team.

The PSO loop: update velocity from three components, move particle, evaluate, and update personal and global bests.
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
int |
10 |
Number of particles in the swarm |
|
float |
0.5 |
Momentum term (0-1), preserves current direction |
|
float |
0.5 |
Attraction to personal best |
|
float |
0.5 |
Attraction to global best |
|
float |
0.2 |
Random exploration weight |
Tuning the Weights
The balance between weights controls swarm behavior:
High inertia: Particles maintain momentum, slower to change direction
High cognitive: Particles prefer their own discoveries
High social: Particles quickly converge to global best
# Exploration-focused (diverse search)
opt = ParticleSwarmOptimizer(
search_space,
inertia=0.9,
cognitive_weight=0.8,
social_weight=0.2,
)
# Exploitation-focused (quick convergence)
opt = ParticleSwarmOptimizer(
search_space,
inertia=0.4,
cognitive_weight=0.3,
social_weight=0.8,
)
Example
import numpy as np
from gradient_free_optimizers import ParticleSwarmOptimizer
def rastrigin(para):
x, y = para["x"], para["y"]
A = 10
return -(A * 2 + (x**2 - A * np.cos(2 * np.pi * x))
+ (y**2 - A * np.cos(2 * np.pi * y)))
search_space = {
"x": np.linspace(-5.12, 5.12, 100),
"y": np.linspace(-5.12, 5.12, 100),
}
opt = ParticleSwarmOptimizer(
search_space,
population=20,
inertia=0.7,
cognitive_weight=0.5,
social_weight=0.5,
)
opt.search(rastrigin, n_iter=200)
print(f"Best: {opt.best_para}, Score: {opt.best_score}")
When to Use
Good for:
Continuous optimization problems
Multi-modal landscapes (swarm covers multiple basins)
When you can evaluate multiple particles in parallel
Problems benefiting from momentum-based search
Not ideal for:
Pure discrete/categorical optimization
Very tight computational budgets
Single-threaded environments with expensive functions
Population Size Guidelines
Dimensions |
Recommended Population |
|---|---|
2-5 |
10-20 |
5-10 |
20-40 |
10-20 |
40-100 |
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import ParticleSwarmOptimizer
def griewank_4d(para):
vals = [para[f"x{i}"] for i in range(4)]
sum_sq = sum(v**2 for v in vals) / 4000
prod_cos = 1
for i, v in enumerate(vals):
prod_cos *= np.cos(v / np.sqrt(i + 1))
return -(sum_sq - prod_cos + 1)
search_space = {
f"x{i}": np.linspace(-10, 10, 200)
for i in range(4)
}
opt = ParticleSwarmOptimizer(
search_space,
population=30,
inertia=0.6,
cognitive_weight=0.4,
social_weight=0.6,
)
opt.search(griewank_4d, n_iter=500)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Controlled by the weight parameters. High inertia + high cognitive = more exploration. High social = faster convergence but risk of premature convergence.
Computational overhead: Low per particle. Total cost scales linearly with population size.
Parameter sensitivity: The three weights (inertia, cognitive, social) interact with each other. The default balanced values (0.5, 0.5, 0.5) work well for most problems.