Bayesian Optimization
Bayesian Optimization fits a Gaussian Process (GP) surrogate model to all observed (position, score) pairs, producing both a mean prediction and a calibrated uncertainty estimate at every point in the search space. An acquisition function, Expected Improvement (EI), combines these two quantities to score candidate positions: points with high predicted value or high uncertainty receive high acquisition scores. The optimizer selects the candidate with the highest acquisition score, evaluates the true objective there, and retrains the GP on the expanded dataset.
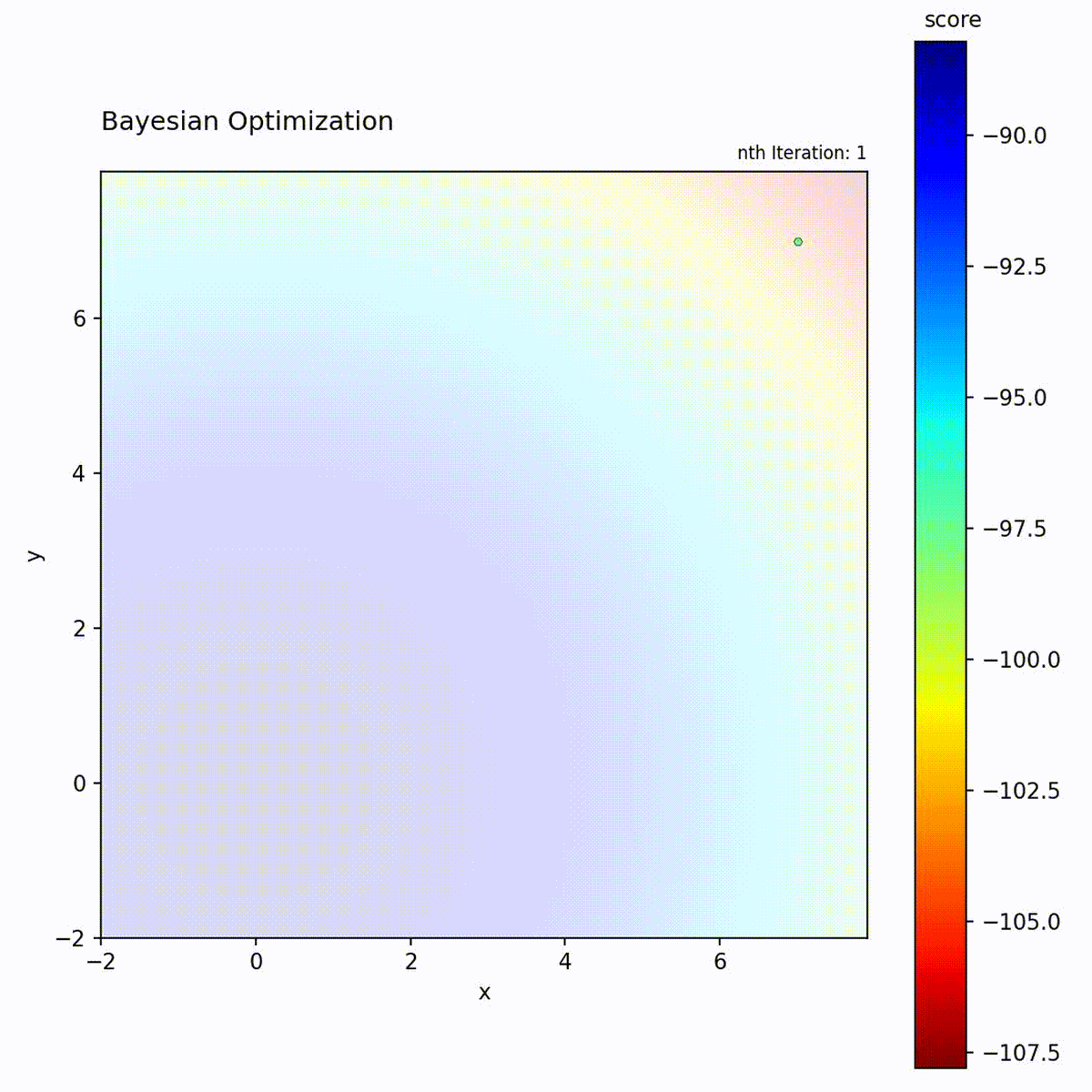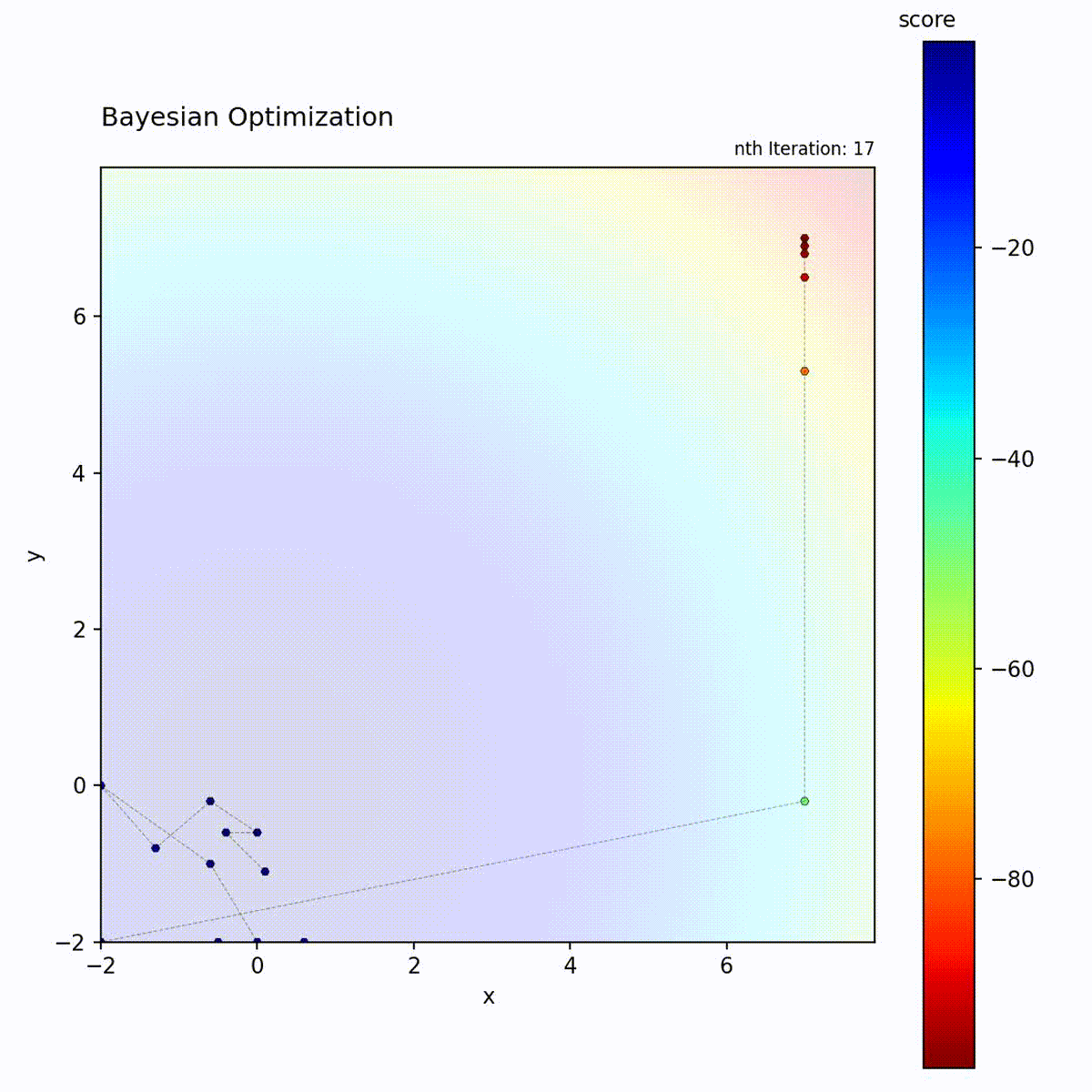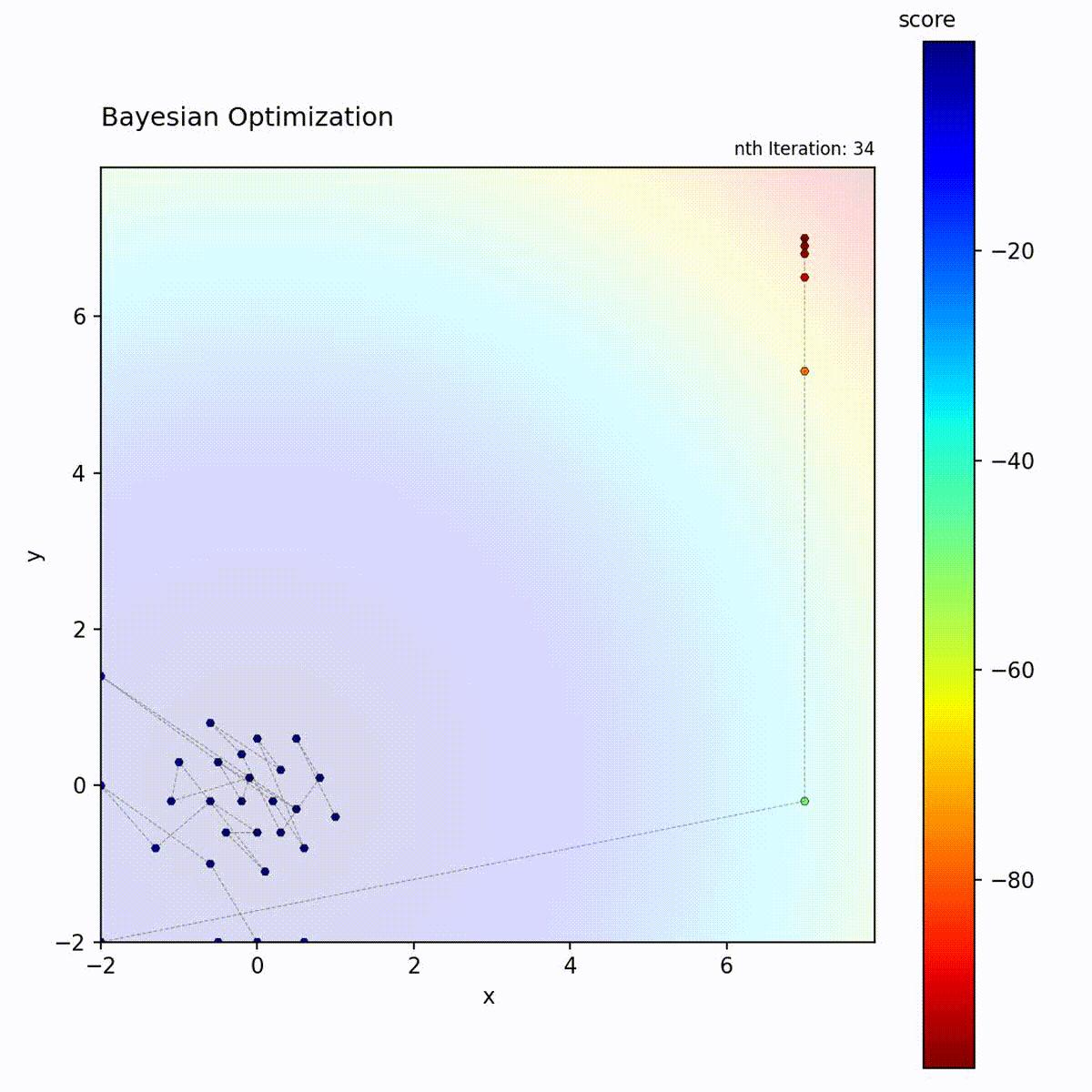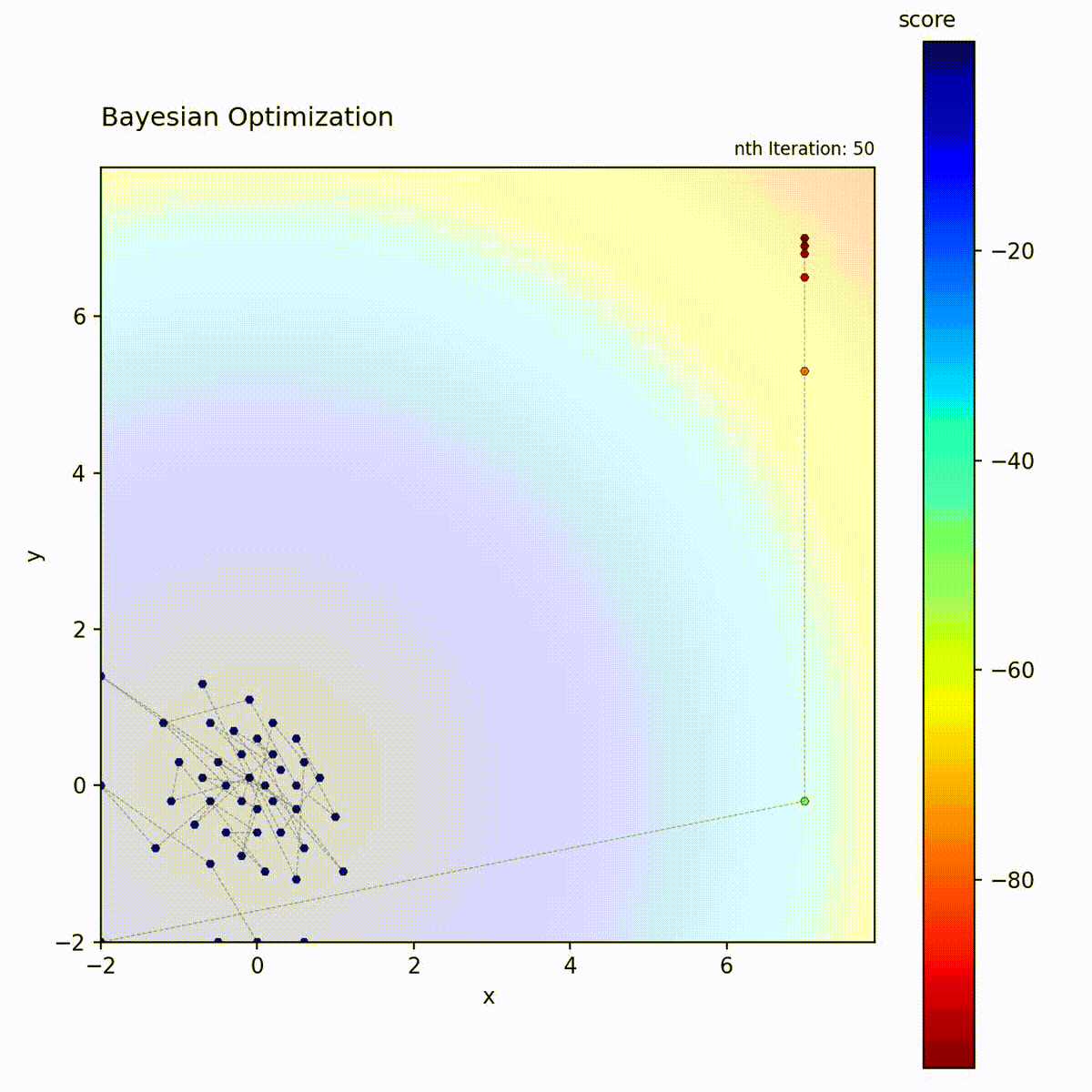
Convex function: Efficiently narrows down to the optimum.
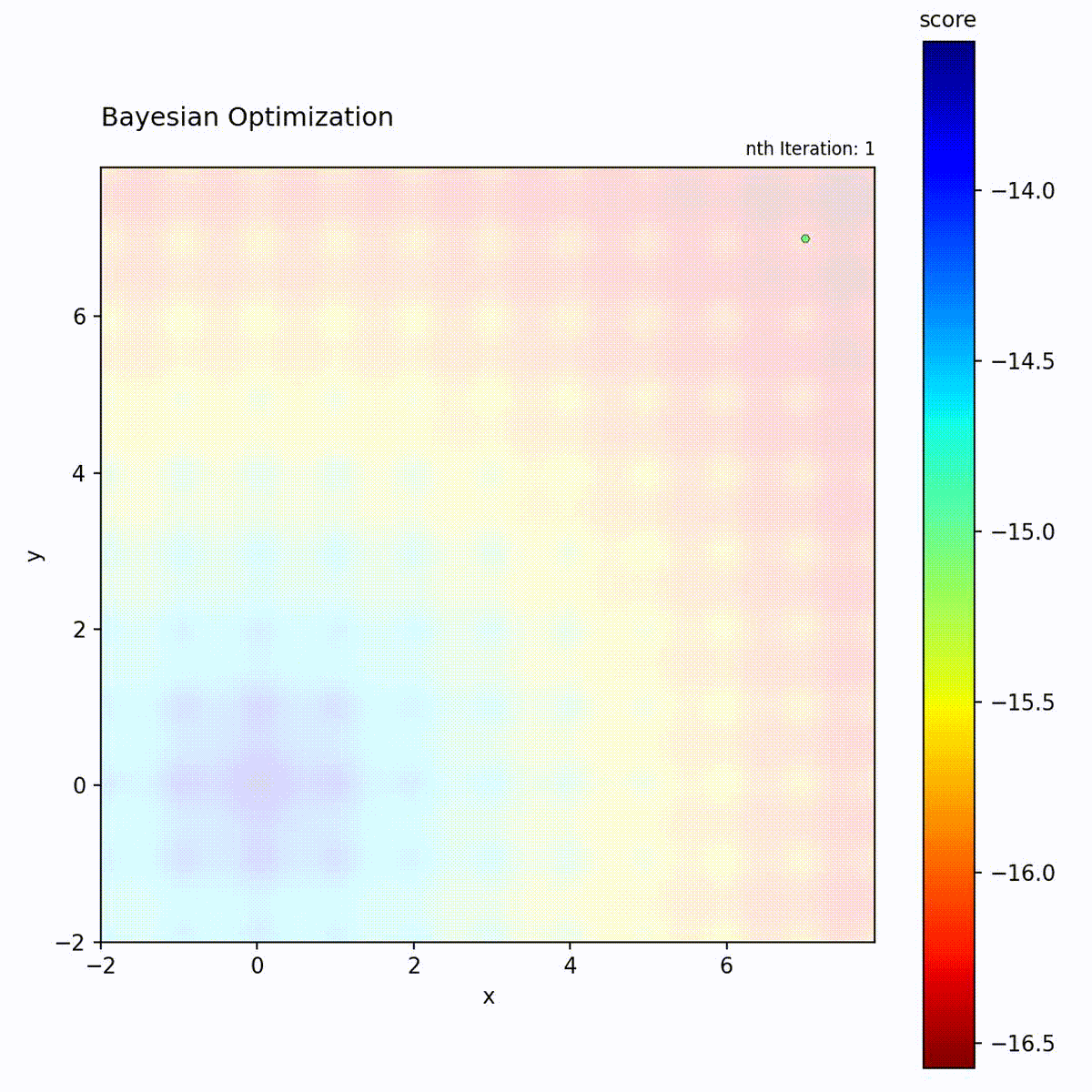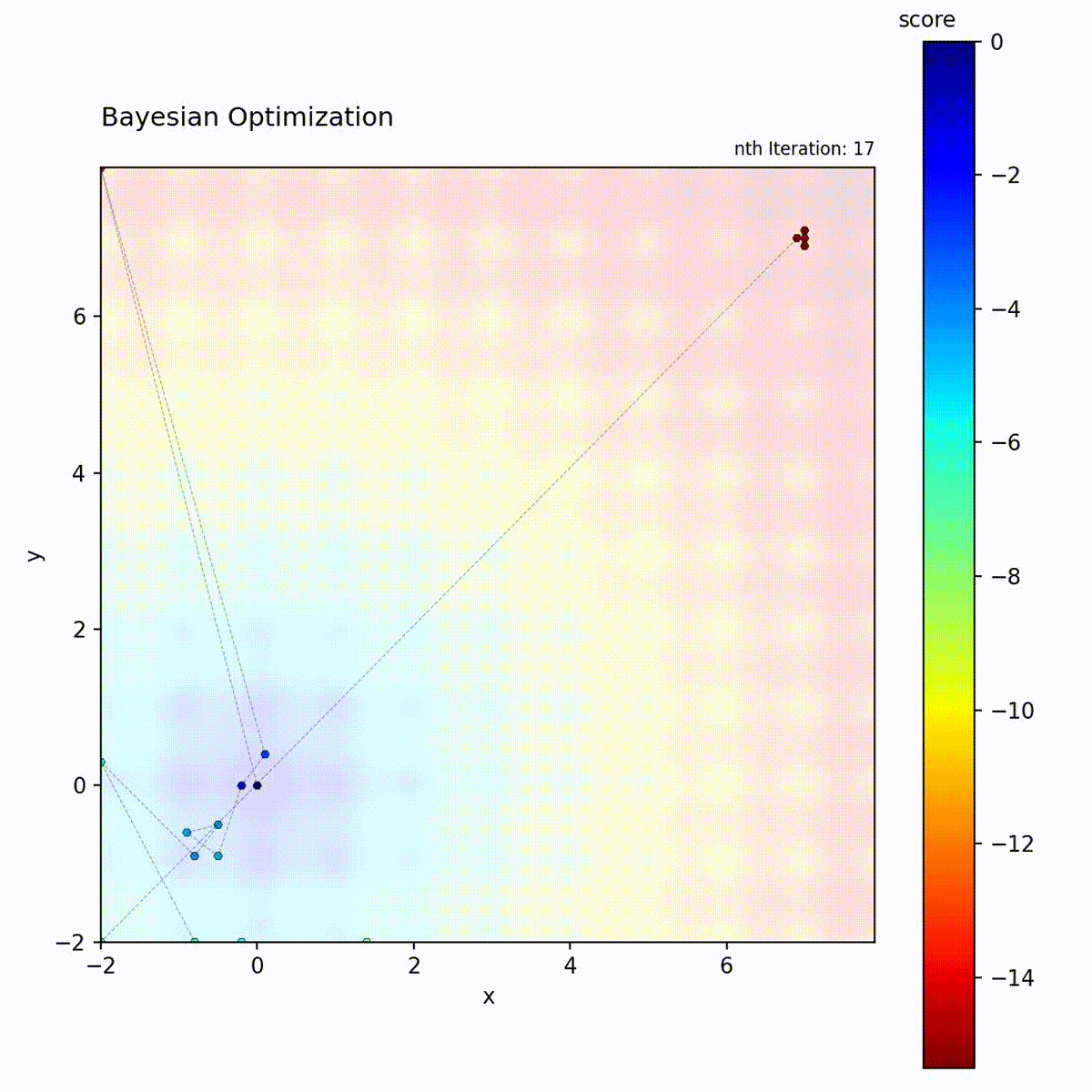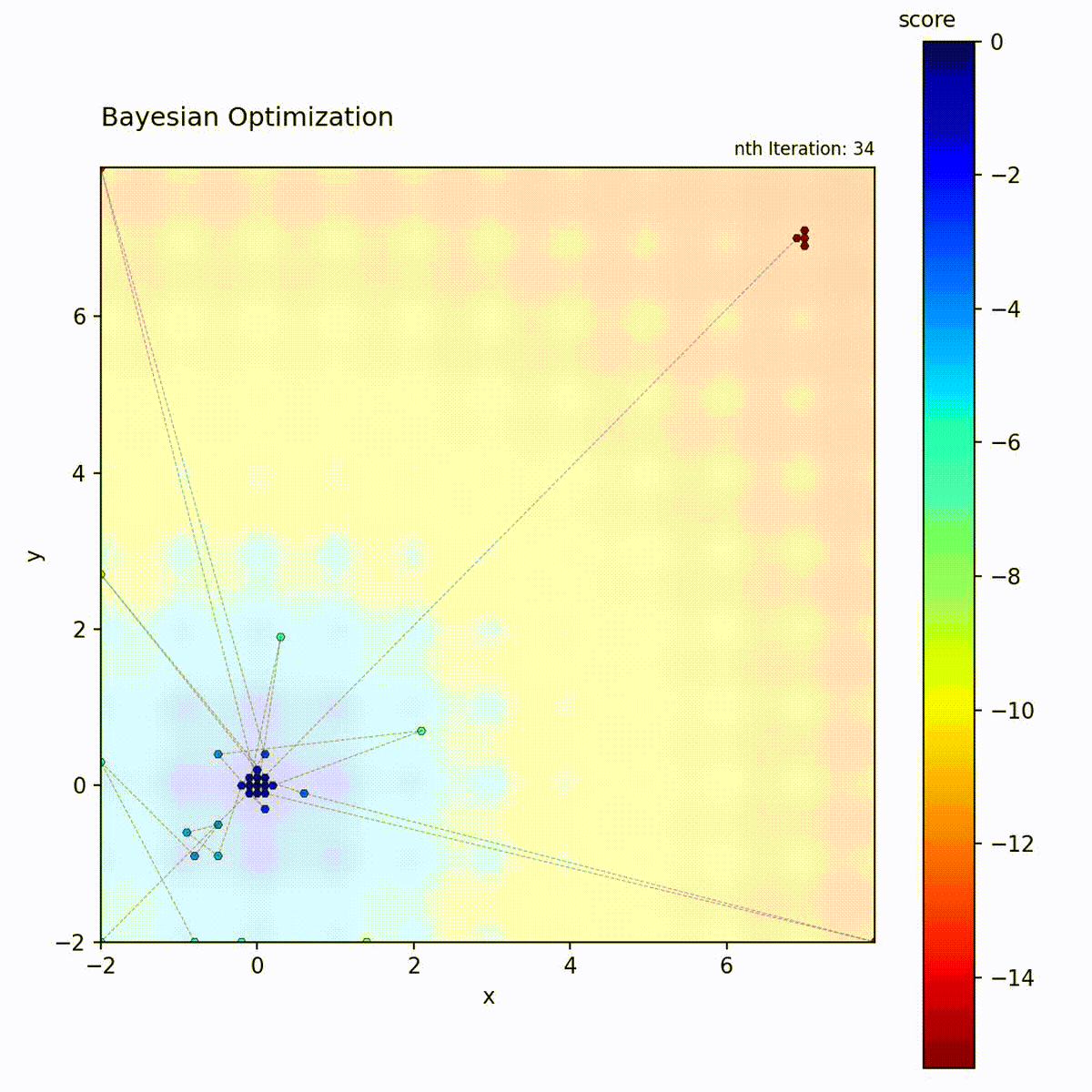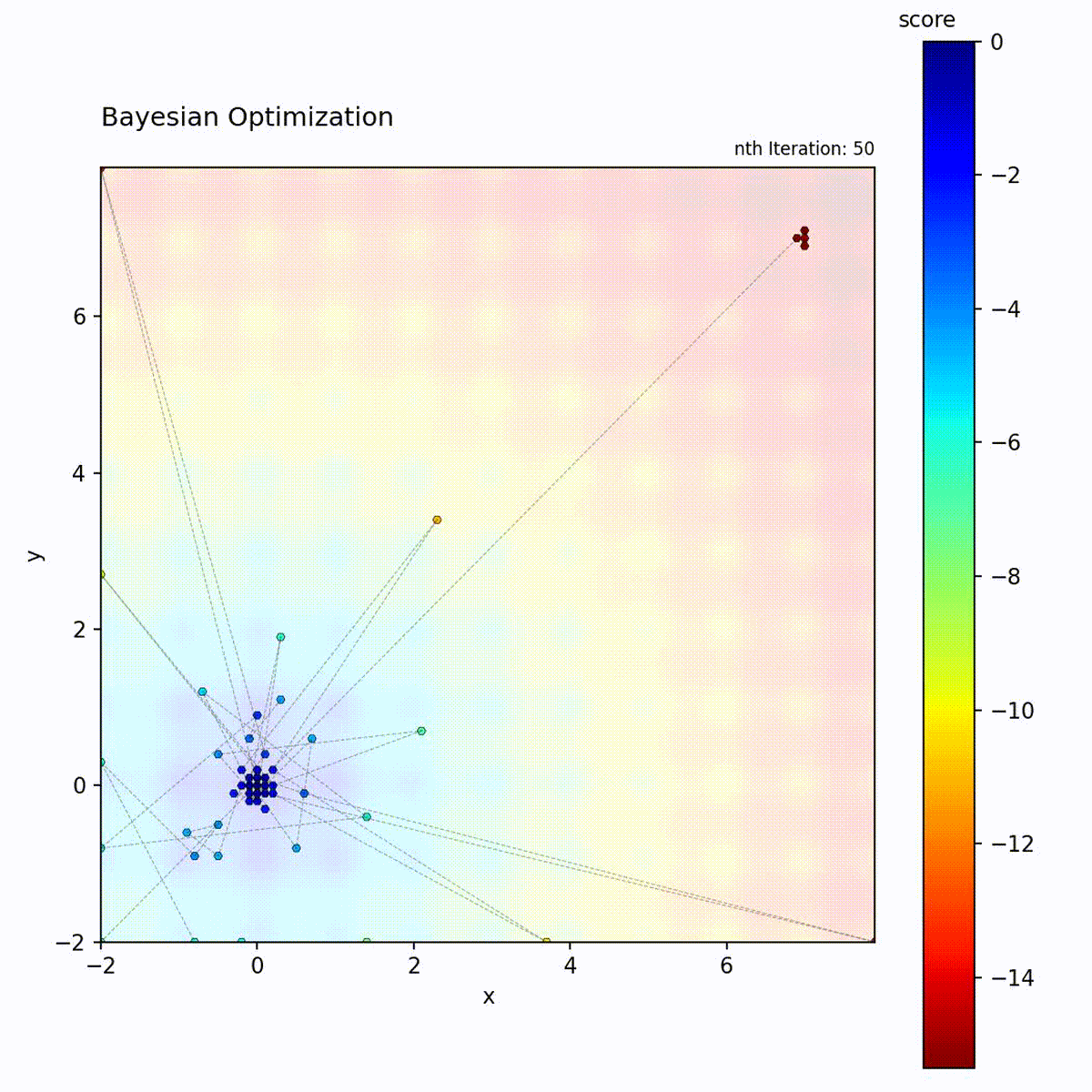
Multi-modal function: Balances exploration and exploitation.
Among the SMBO optimizers in this library, Bayesian Optimization provides the highest-fidelity uncertainty estimates because the GP produces a full posterior distribution rather than a point estimate. This comes at the cost of O(n^3) scaling in the number of observations, which makes it practical for evaluation budgets up to a few hundred iterations. For larger budgets or search spaces with many discrete/categorical parameters, Forest Optimizer and Tree-structured Parzen Estimators (TPE) are more suitable alternatives.
Algorithm
At each iteration:
Fit surrogate model: Train GP on all (position, score) observations
Predict: For candidate positions, predict mean and uncertainty
Acquisition function: Compute Expected Improvement (EI)
EI(x) = E[max(0, f(x) - f(x_best))]
EI is high when: predicted value is good OR uncertainty is high
Select: Choose position with highest acquisition value
Evaluate: Run actual objective function
Update: Add new observation, repeat
Note
Bayesian Optimization is fundamentally about making decisions under uncertainty. The GP surrogate provides not just a prediction but a full probability distribution at every point. The Expected Improvement acquisition function then naturally balances exploration (high uncertainty) and exploitation (high predicted value) in a single, principled formula. This is why BO can find good solutions in remarkably few evaluations compared to methods that lack an uncertainty model.

The BO loop: fit GP, compute Expected Improvement, select the point with highest acquisition value, evaluate, and update the dataset.
The Gaussian Process
A GP provides:
Mean prediction: Expected function value at each point
Uncertainty: How confident we are (from covariance)
This uncertainty is crucial: it allows the algorithm to explore uncertain regions that might contain the optimum.
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
float |
0.03 |
Exploration-exploitation trade-off |
|
object |
gaussian_process[“gp_nonlinear”] |
Gaussian Process regressor configuration |
The xi Parameter
xi controls the exploration-exploitation balance:
Lower xi (0.01): Focus on regions with high predicted scores
Higher xi (0.1): Explore uncertain regions more
# Exploitation-focused
opt = BayesianOptimizer(search_space, xi=0.01)
# Exploration-focused
opt = BayesianOptimizer(search_space, xi=0.1)
Example
import numpy as np
from gradient_free_optimizers import BayesianOptimizer
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_breast_cancer
X, y = load_breast_cancer(return_X_y=True)
def objective(para):
clf = GradientBoostingClassifier(
n_estimators=para["n_estimators"],
max_depth=para["max_depth"],
learning_rate=para["learning_rate"],
random_state=42,
)
return cross_val_score(clf, X, y, cv=3).mean()
search_space = {
"n_estimators": np.arange(50, 200, 10),
"max_depth": np.arange(2, 10),
"learning_rate": np.linspace(0.01, 0.3, 20),
}
opt = BayesianOptimizer(search_space)
opt.search(objective, n_iter=30)
print(f"Best accuracy: {opt.best_score:.4f}")
print(f"Best params: {opt.best_para}")
When to Use
Good for:
Expensive objective functions (ML training, simulations)
Low-dimensional continuous spaces (< 20 dimensions)
When you have limited evaluation budget
Problems where each evaluation takes seconds to hours
Not ideal for:
Very cheap functions (GP overhead dominates)
Very high dimensions (GP scales poorly)
Purely discrete/categorical spaces (consider TPE)
Computational Cost
GP training is O(n^3) where n is the number of observations:
10 observations: negligible
100 observations: noticeable
1000 observations: significant
For many evaluations, consider Forest Optimizer or Tree-structured Parzen Estimators (TPE).
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import BayesianOptimizer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_digits
X, y = load_digits(return_X_y=True)
def objective(para):
clf = KNeighborsClassifier(
n_neighbors=para["n_neighbors"],
weights=para["weights"],
p=para["p"],
leaf_size=para["leaf_size"],
)
return cross_val_score(clf, X, y, cv=3).mean()
search_space = {
"n_neighbors": np.arange(1, 30),
"weights": np.array(["uniform", "distance"]),
"p": np.array([1, 2]),
"leaf_size": np.arange(10, 60, 5),
}
opt = BayesianOptimizer(search_space, xi=0.05)
opt.search(objective, n_iter=40)
print(f"Best accuracy: {opt.best_score:.4f}")
print(f"Best params: {opt.best_para}")
Trade-offs
Exploration vs. exploitation: Controlled by
xi. The GP’s uncertainty naturally decays in well-sampled regions, so exploration shifts automatically toward unexplored areas.Computational overhead: GP training is O(n^3) in observations. This makes BO best suited for problems where the objective function is far more expensive than the surrogate model fitting.
Parameter sensitivity: The default
xi=0.03works well for most problems. The choice of GP kernel (viagpr) can matter more thanxifor complex landscapes.