Grid Search
Grid Search evaluates positions on a regular lattice spanning the search space,
advancing through grid points in a fixed traversal order. The spacing between
points is controlled by a step_size parameter, and two traversal patterns are
available: diagonal and orthogonal. Given sufficient iterations, Grid Search
visits every grid point and therefore guarantees finding the optimum among those
points. The total number of evaluations scales as the product of grid points
across all dimensions.
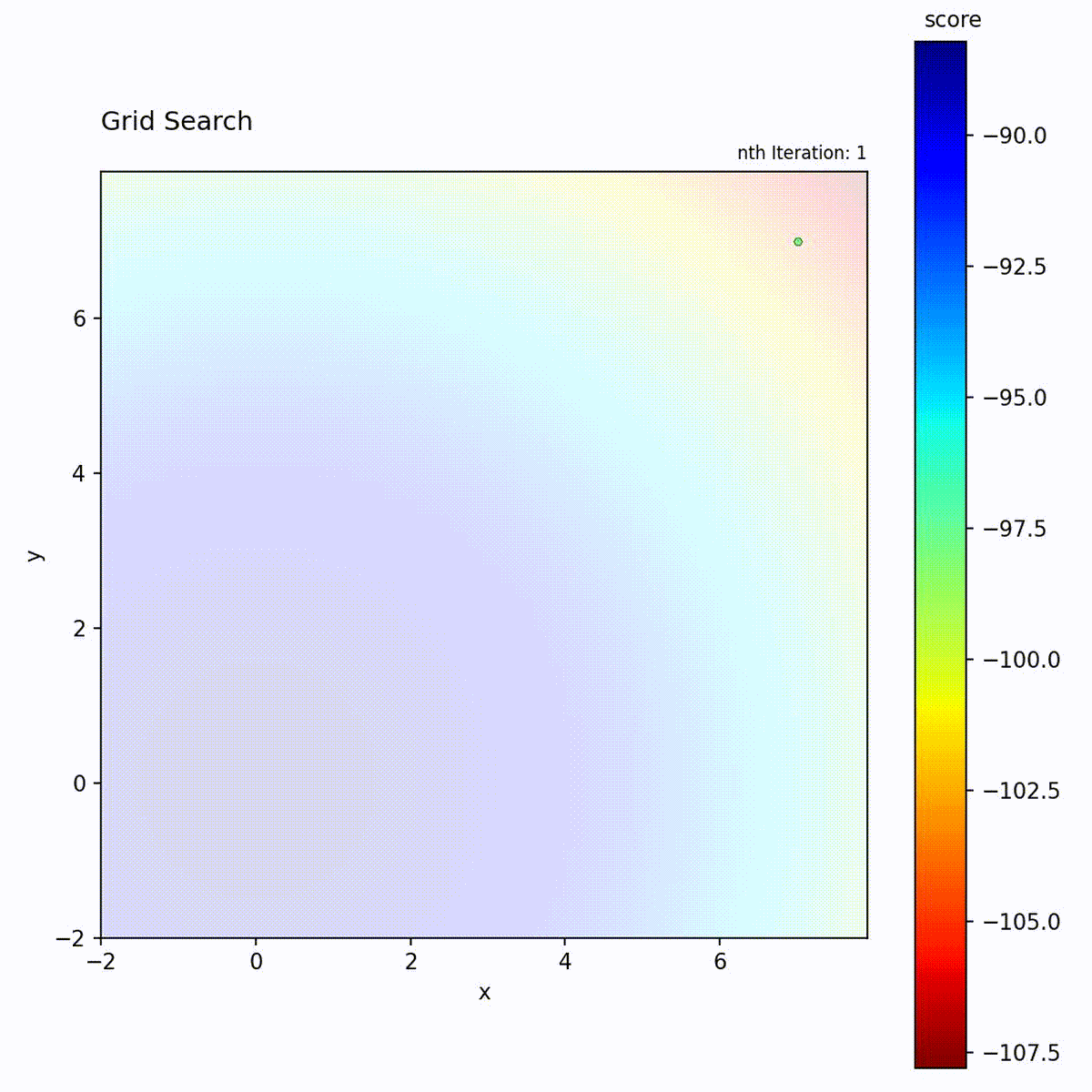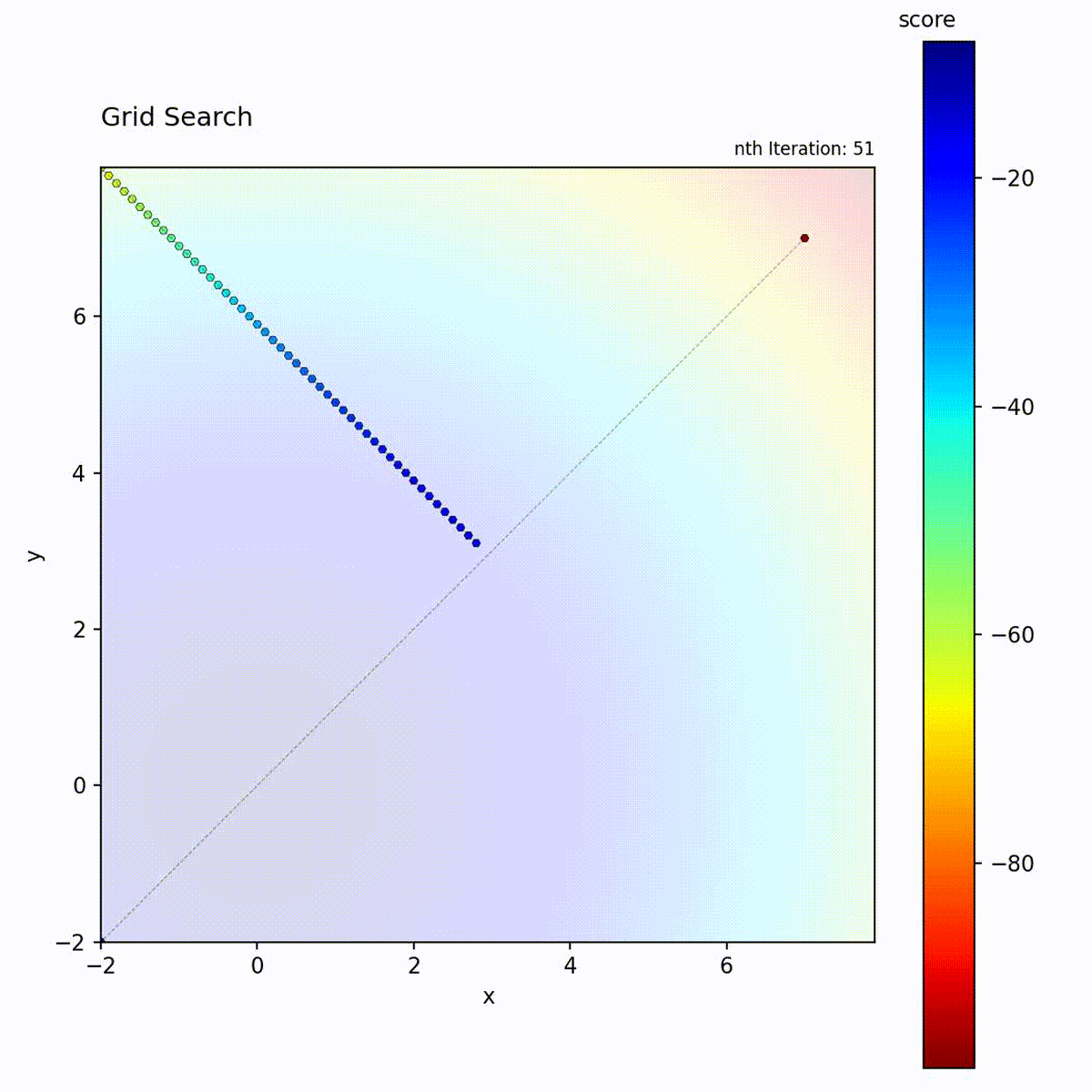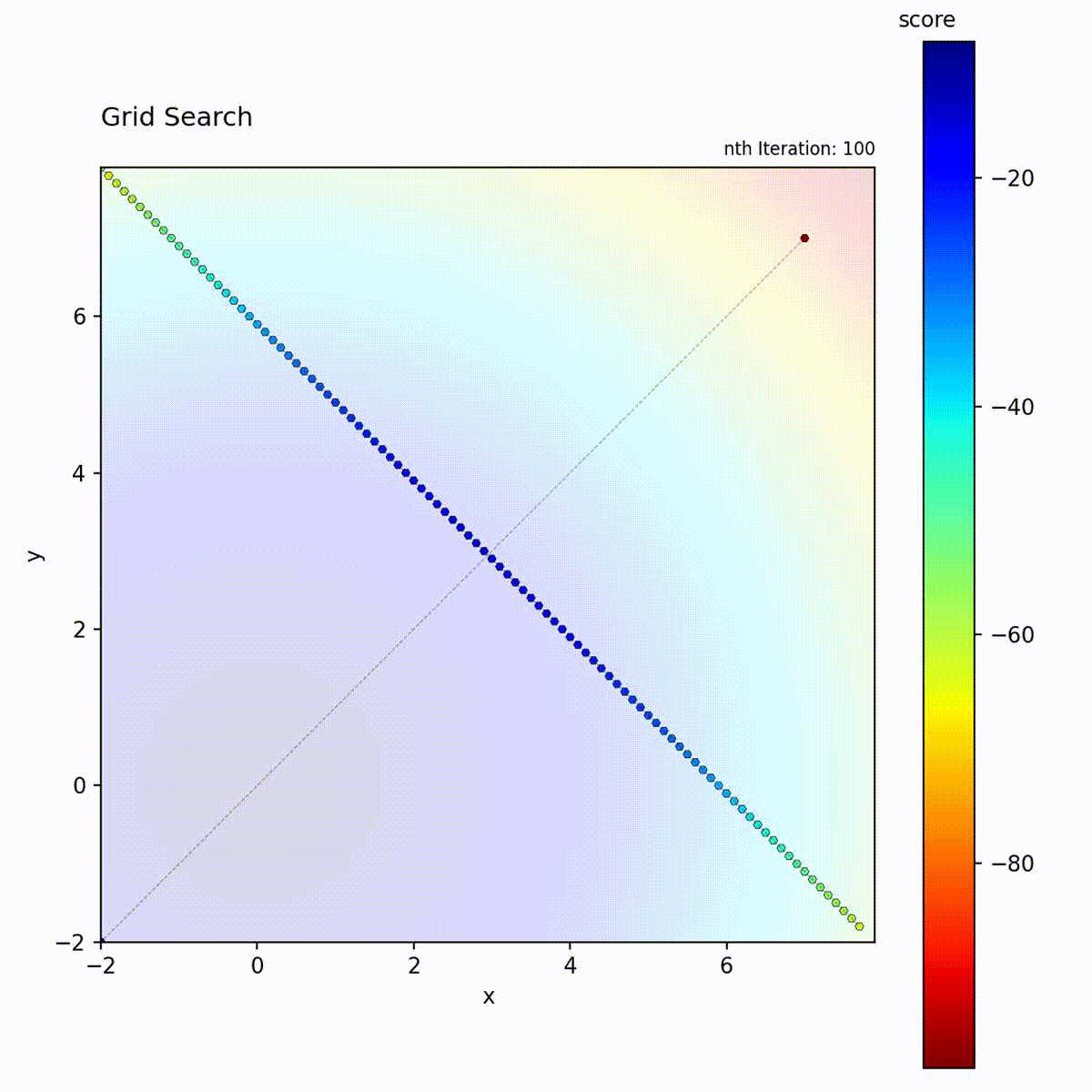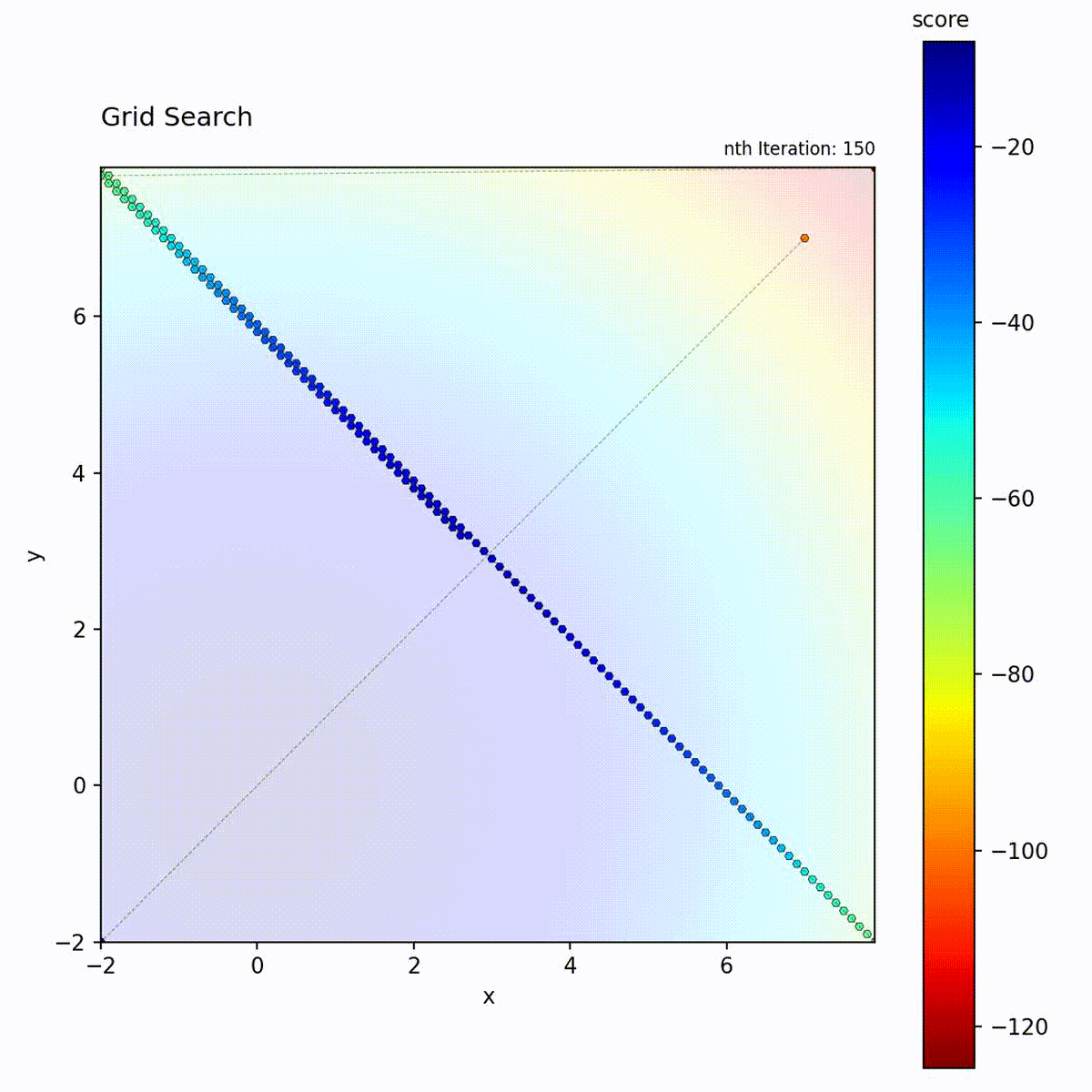
Convex function: Systematic traversal of the grid.
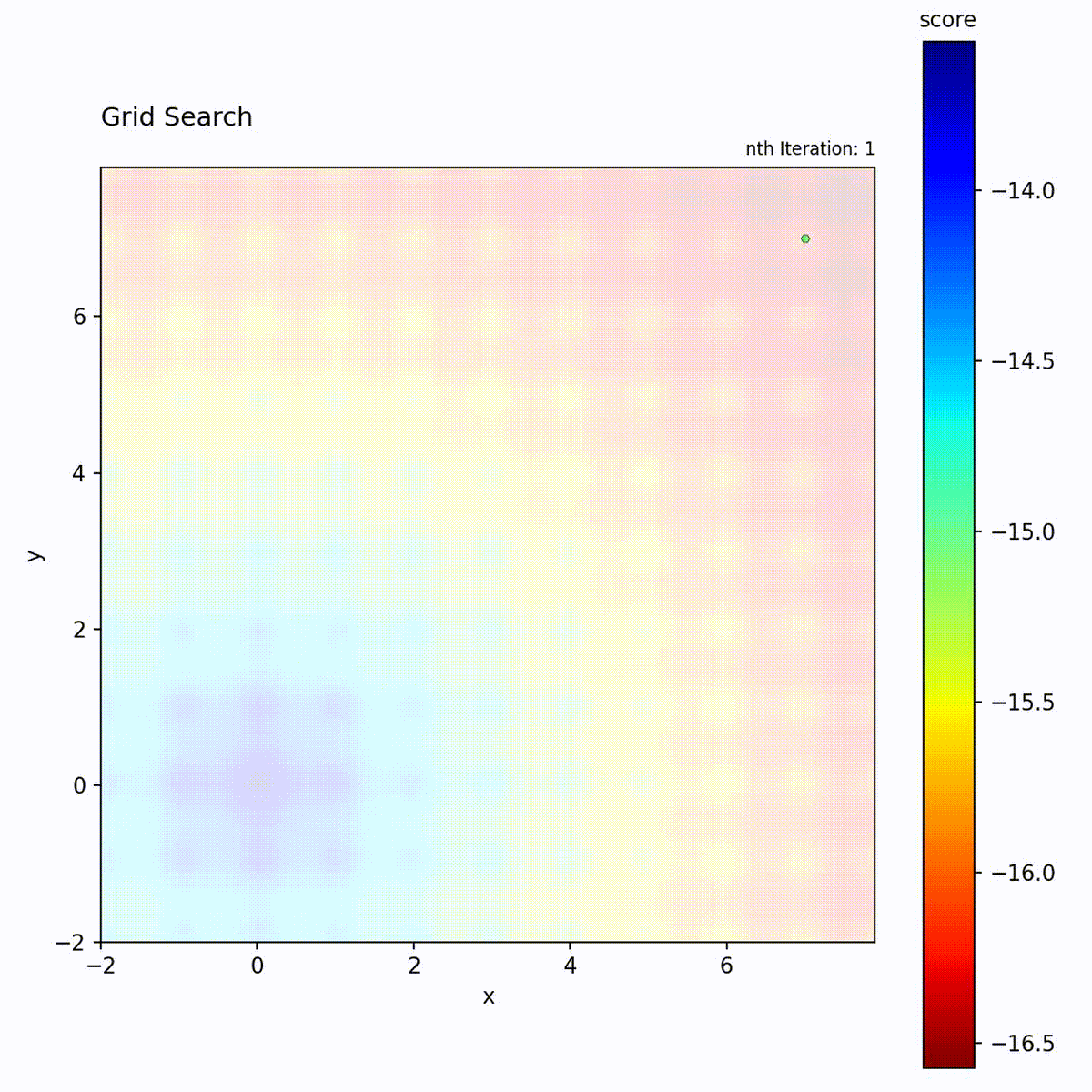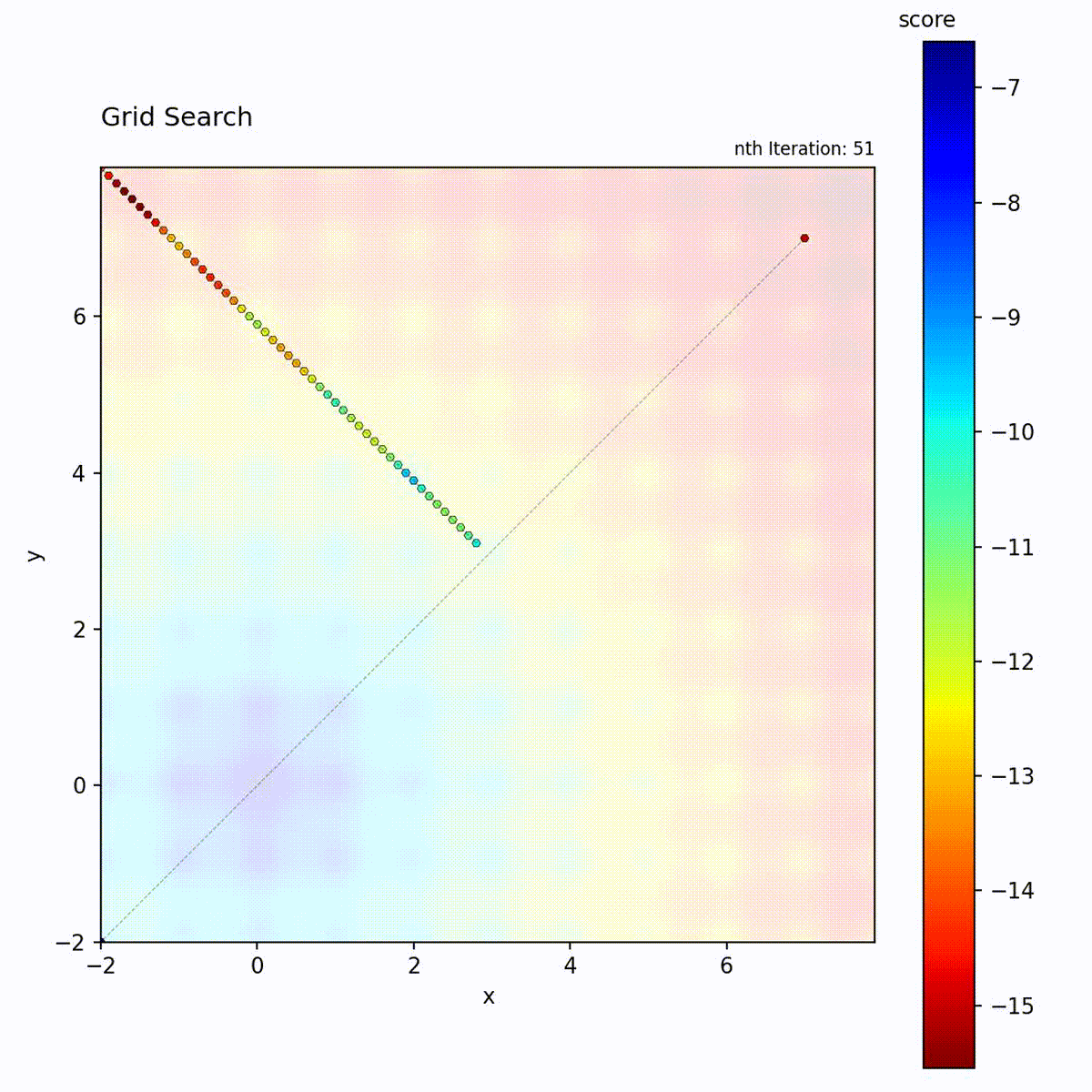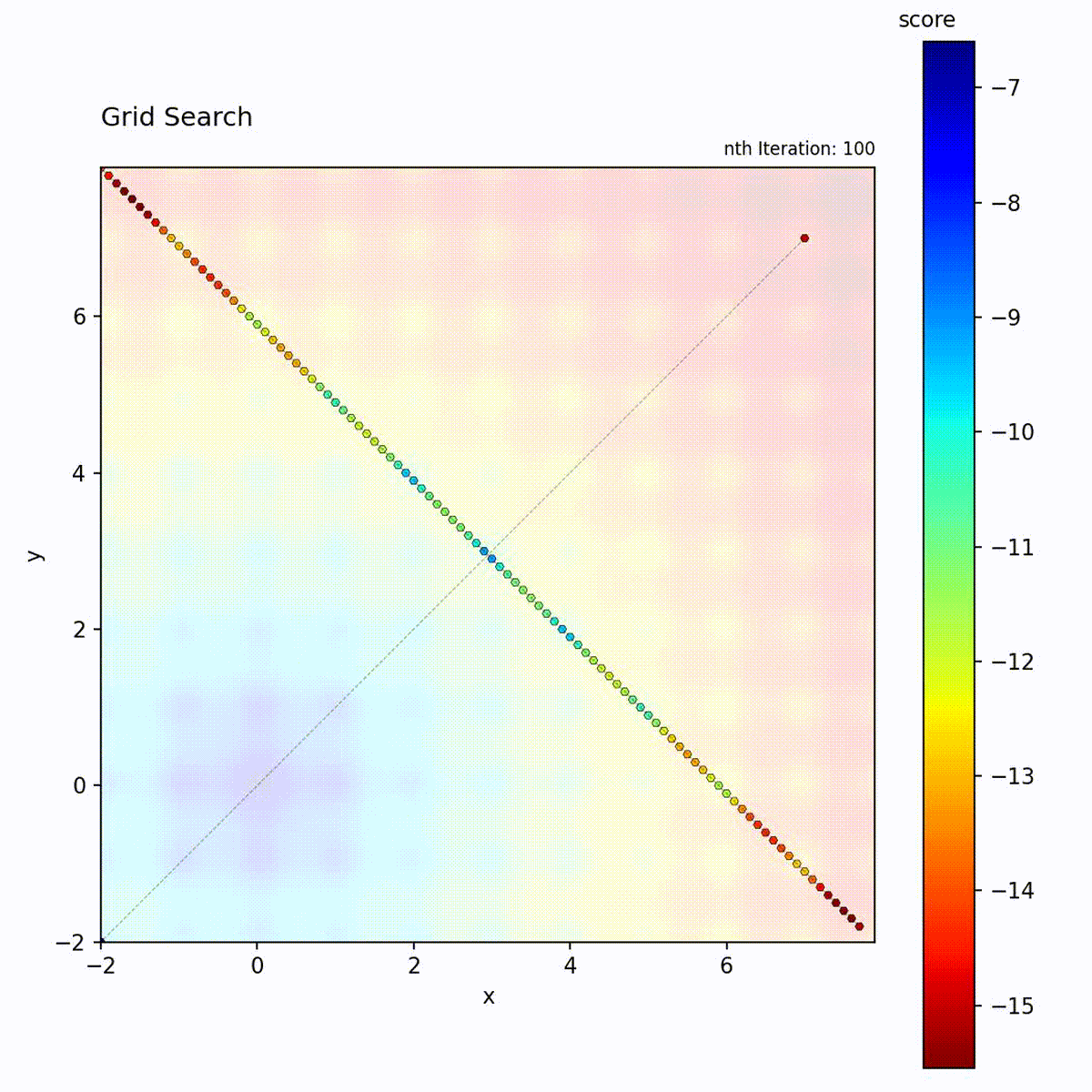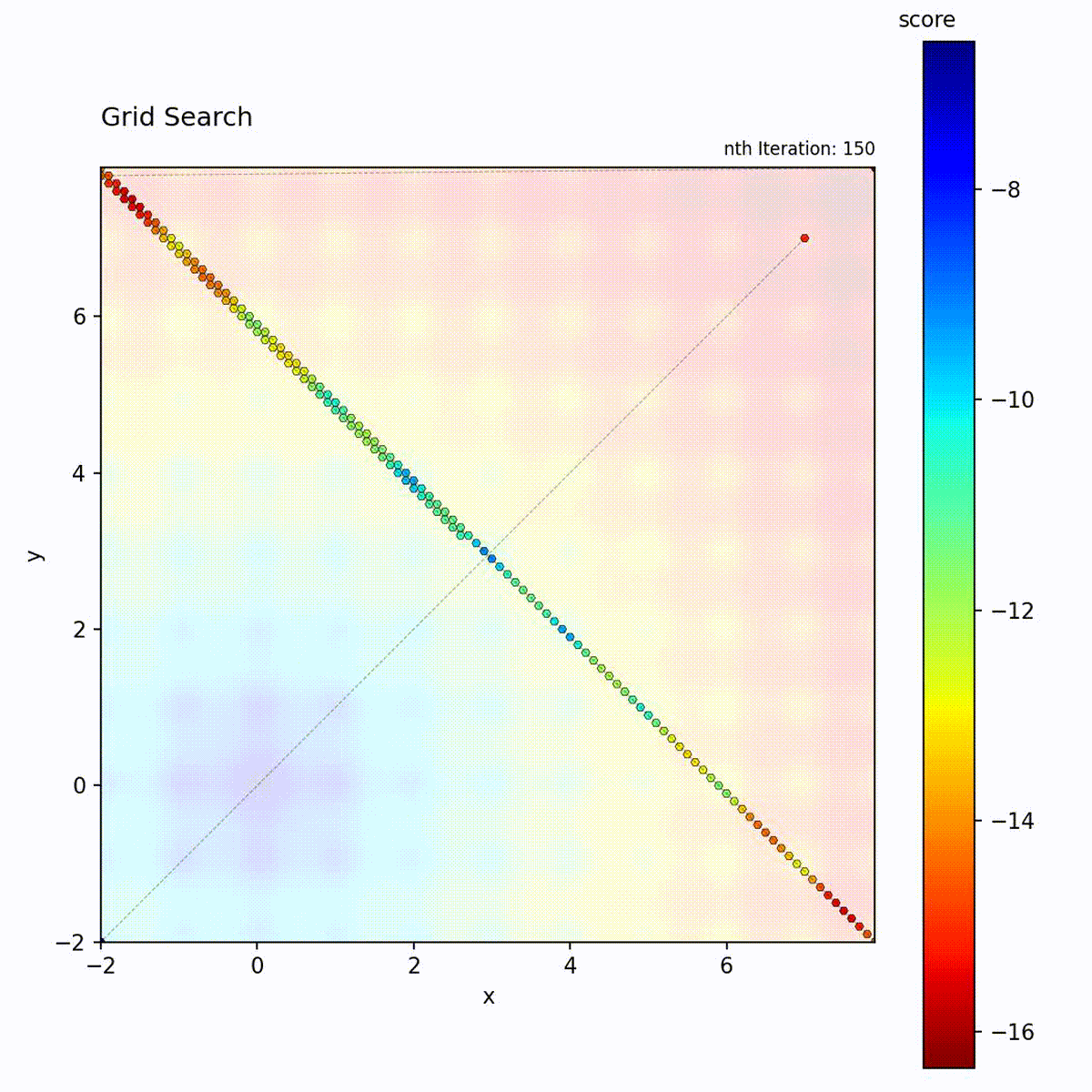
Multi-modal function: Guaranteed to find the global optimum if it’s on the grid.
Grid Search is deterministic and fully reproducible, which distinguishes it from stochastic methods like Random Search. However, it allocates equal resolution to every dimension regardless of that dimension’s influence on the objective, which makes it inefficient when only a subset of parameters matters. The exponential growth in evaluations with dimensionality limits it to low-dimensional problems (typically fewer than 5 dimensions with coarse grids). Choose Grid Search over Random Search when complete, systematic coverage of a small discrete space is required and reproducibility without a random seed is a priority.
Algorithm
Grid Search traverses positions in a structured pattern:
Start at a corner of the search space
Move to adjacent grid positions following the specified direction
Evaluate each position
Track the best found
for each position on grid (step_size spacing):
score = objective(position)
if score > best_score:
best_score, best_pos = score, position
GFO supports two traversal patterns:
Diagonal: Moves diagonally across the grid (default)
Orthogonal: Moves along axes, one dimension at a time
Note
Grid Search is the only algorithm that guarantees finding the global optimum (if it lies on a grid point) given enough iterations. However, it projects poorly to important dimensions: in a 5D space where only 2 dimensions matter, grid search wastes most evaluations on irrelevant combinations.
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
int |
1 |
Grid spacing (1 = every point, 2 = every other point, etc.) |
|
str |
“diagonal” |
Traversal pattern: “diagonal” or “orthogonal” |
Step Size
The step_size controls how many grid points to skip:
# Dense grid - evaluate every point
opt = GridSearchOptimizer(search_space, step_size=1)
# Sparse grid - skip every other point
opt = GridSearchOptimizer(search_space, step_size=2)
Warning
Total evaluations = product of (dimension_size / step_size) for all dimensions. For a 3D space with 100 points each and step_size=1, that’s 1,000,000 evaluations!
Example
import numpy as np
from gradient_free_optimizers import GridSearchOptimizer
def objective(para):
return -(para["x"]**2 + para["y"]**2)
# Small search space for grid search
search_space = {
"x": np.linspace(-5, 5, 20), # 20 points
"y": np.linspace(-5, 5, 20), # 20 points
}
# Total: 400 evaluations needed for complete coverage
opt = GridSearchOptimizer(search_space, step_size=1)
opt.search(objective, n_iter=400)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
When to Use
Good for:
Small, low-dimensional search spaces
When you need guaranteed coverage
Discrete parameter spaces with few options
When reproducibility is critical
Not ideal for:
High-dimensional spaces (exponential growth)
Large continuous spaces
Expensive function evaluations
The Curse of Dimensionality
Grid Search doesn’t scale well with dimensions:
Dimensions |
Points per dim |
Total evaluations |
|---|---|---|
2 |
10 |
100 |
3 |
10 |
1,000 |
5 |
10 |
100,000 |
10 |
10 |
10,000,000,000 |
For high-dimensional problems, consider Random Search or SMBO algorithms.
Comparison with Random Search
Aspect |
Grid Search |
Random Search |
|---|---|---|
Coverage |
Complete (if enough iterations) |
Probabilistic |
High dimensions |
Curse of dimensionality |
Scales linearly |
Parameter importance |
Same resolution everywhere |
Adapts through projection |
Early stopping |
May miss optimum |
Probabilistically fair |
Sparse Grid Example
import numpy as np
from gradient_free_optimizers import GridSearchOptimizer
def objective(para):
return -(para["x"]**2 + para["y"]**2 + para["z"]**2)
# Coarse grid to manage 3D space
search_space = {
"x": np.linspace(-5, 5, 10),
"y": np.linspace(-5, 5, 10),
"z": np.linspace(-5, 5, 10),
}
opt = GridSearchOptimizer(search_space, step_size=2)
opt.search(objective, n_iter=200)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Pure exploration with complete coverage but no adaptation to promising regions.
Computational overhead: Effectively zero per step, but total cost grows exponentially with dimensions.
Parameter sensitivity:
step_sizetrades resolution for speed. Larger steps risk missing the optimum between grid points.