Simulated Annealing
Simulated Annealing accepts worse solutions with a probability that decreases
over time according to a temperature schedule. The acceptance probability for a
candidate with score degradation delta is exp(delta / temperature), where
the temperature starts at start_temp and decays by a factor of
annealing_rate each iteration. At high temperatures, the algorithm accepts
nearly all moves, including substantially worse ones. As the temperature
approaches zero, acceptance of worse solutions becomes negligible and the
algorithm converges to greedy Hill Climbing behavior.
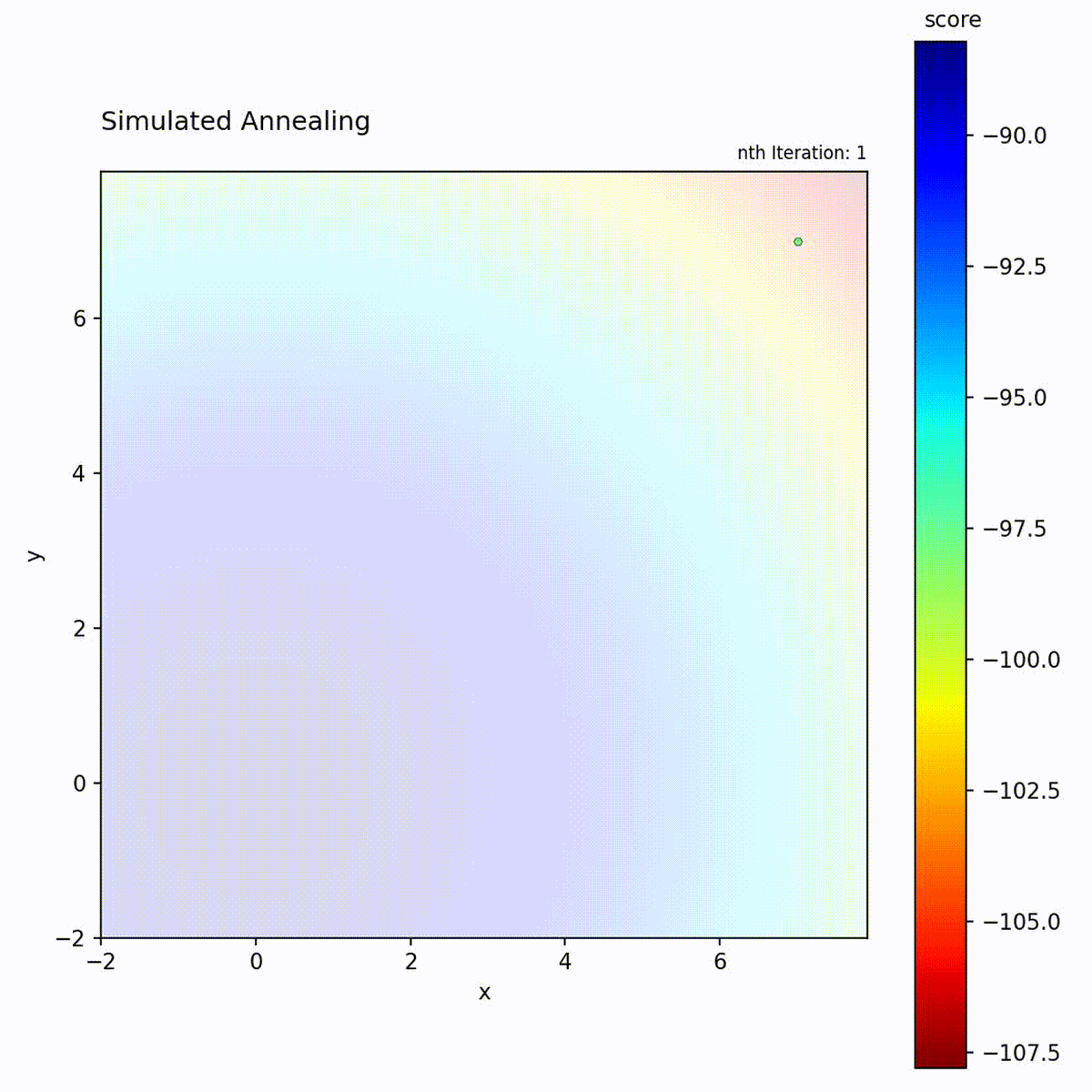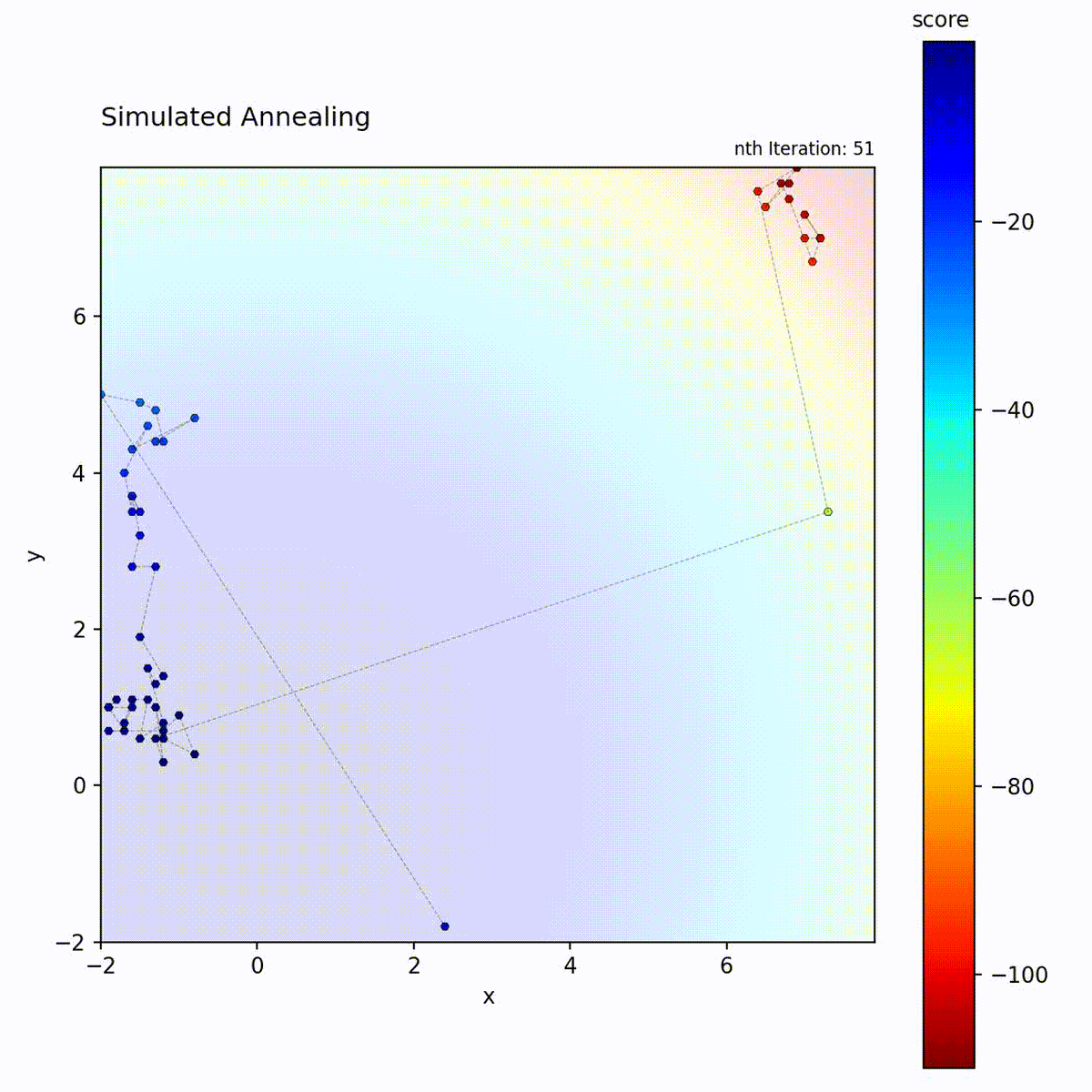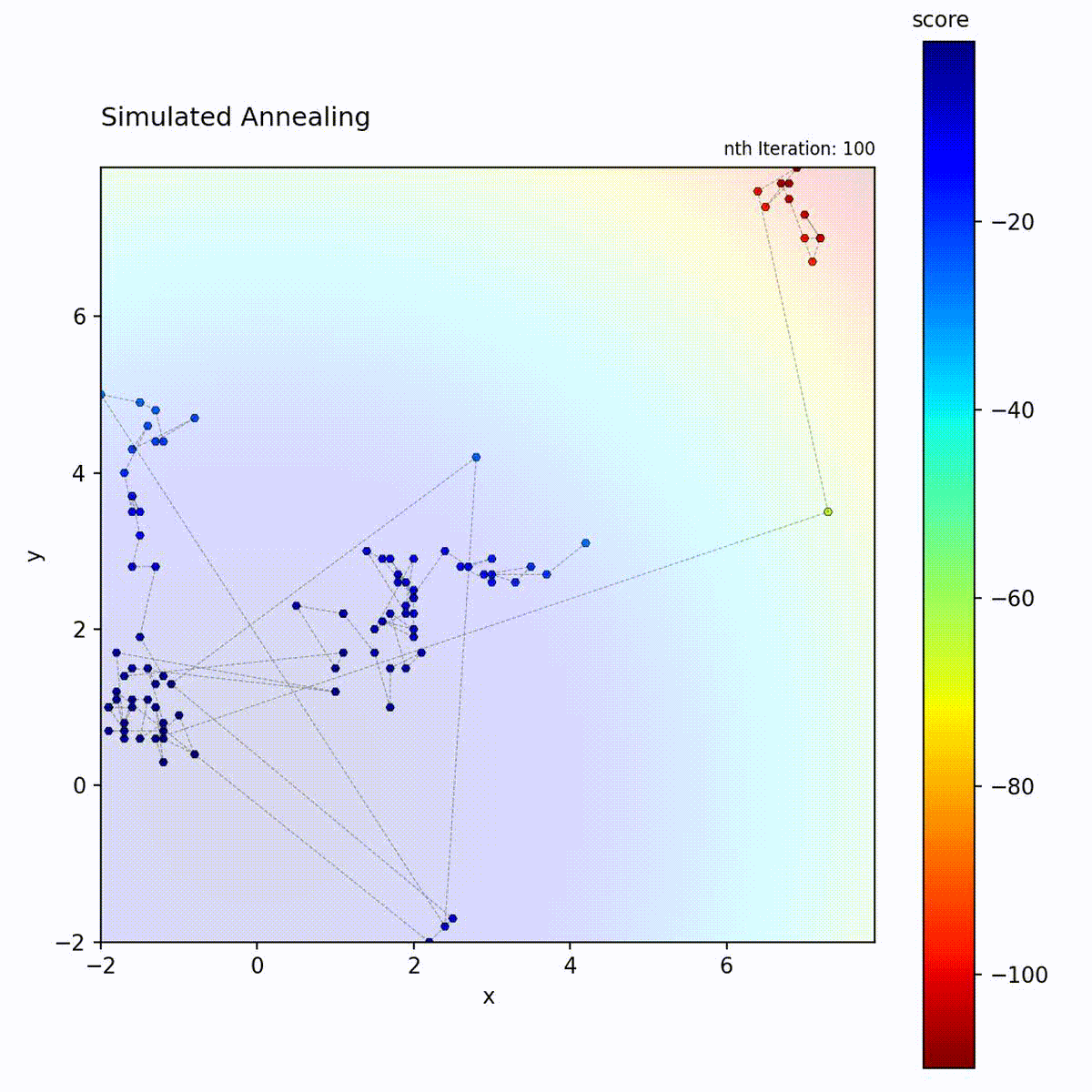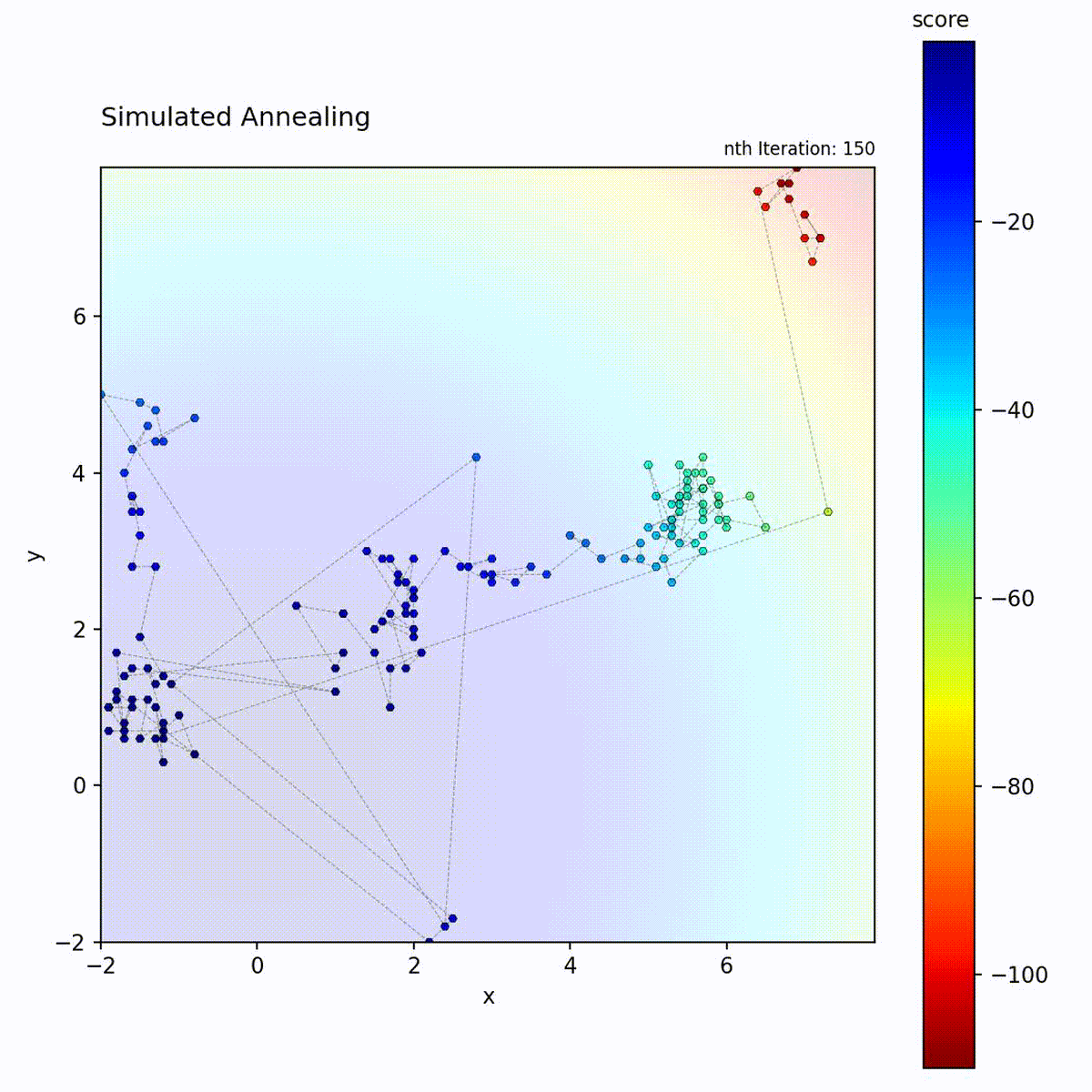
Convex function: Explores broadly at first, then converges to the optimum.
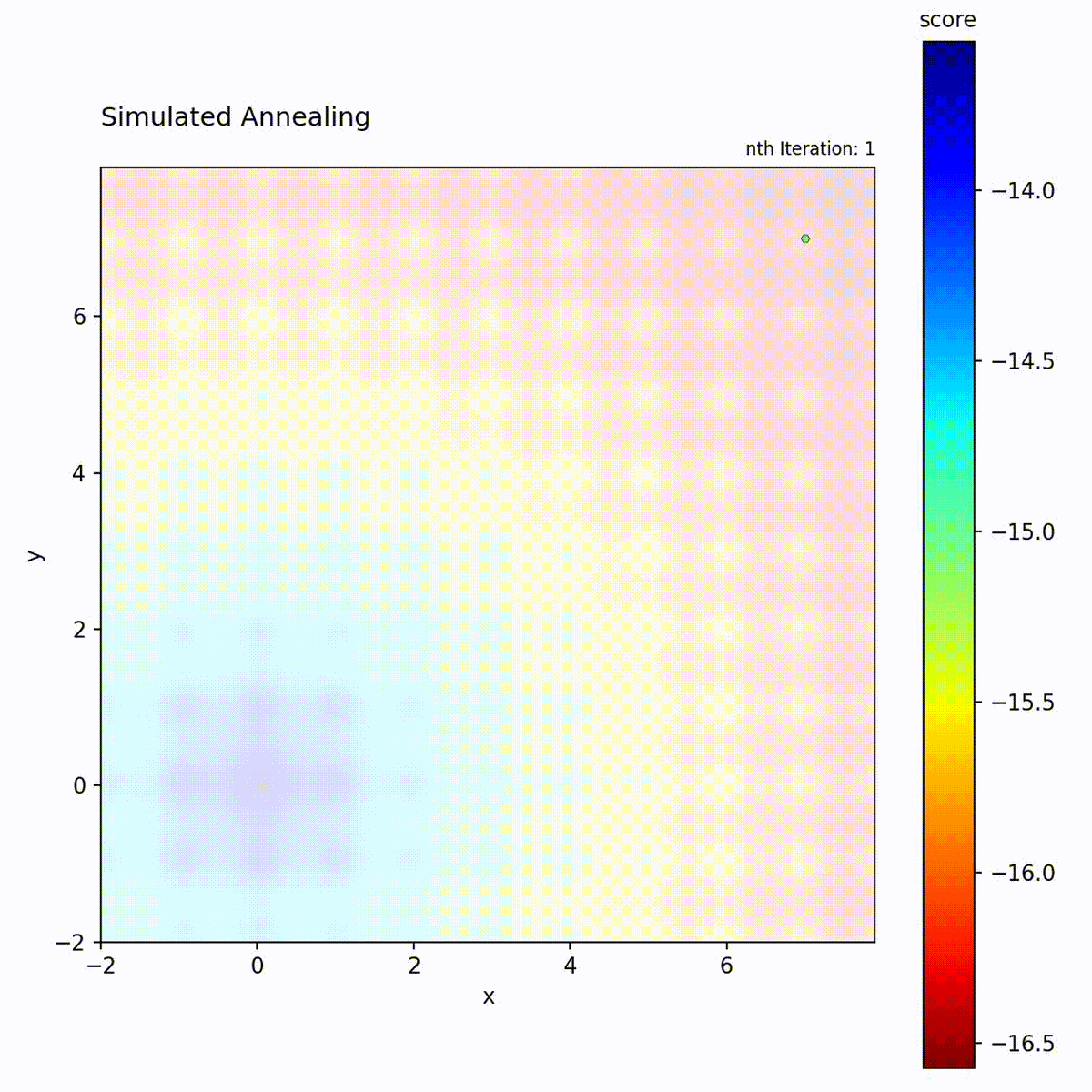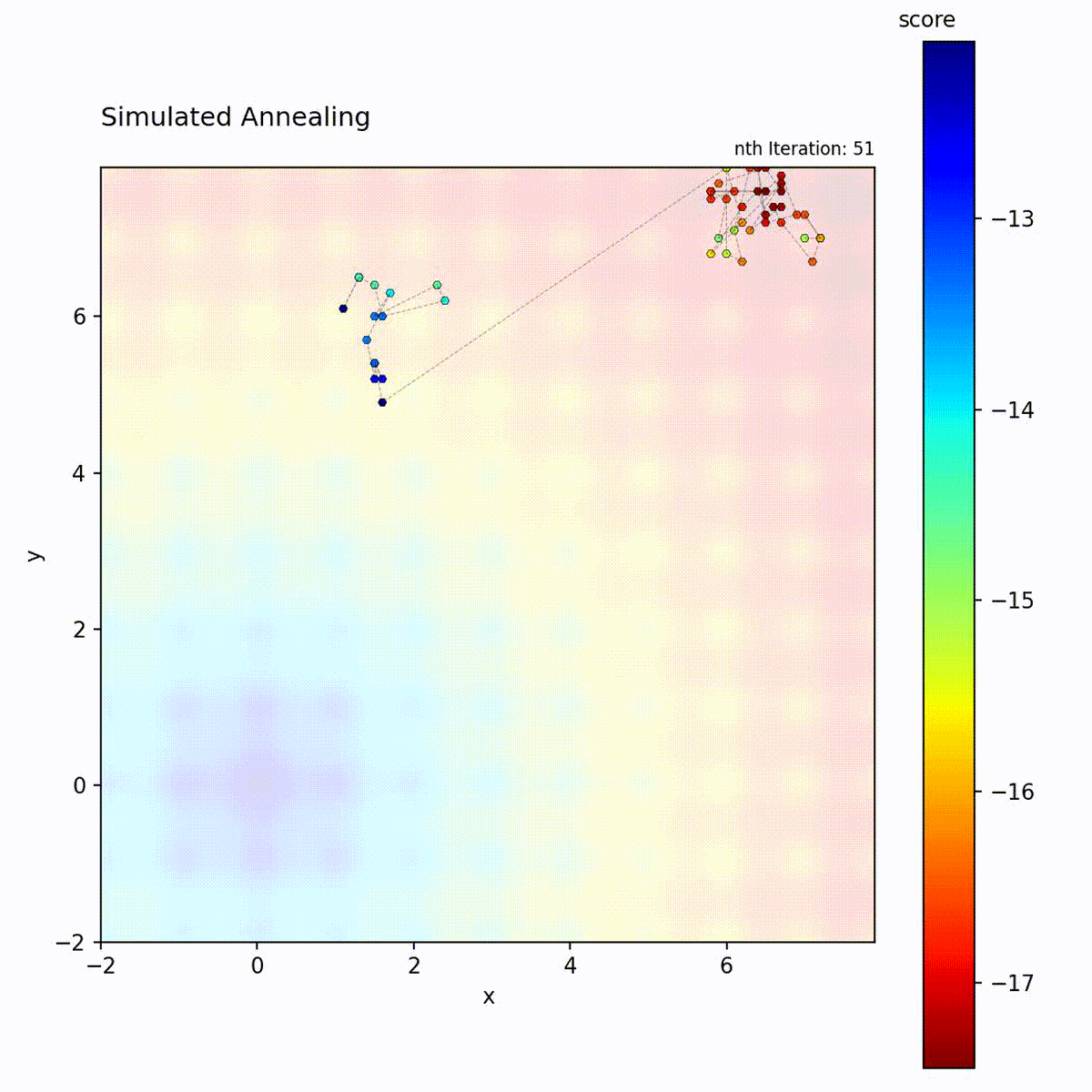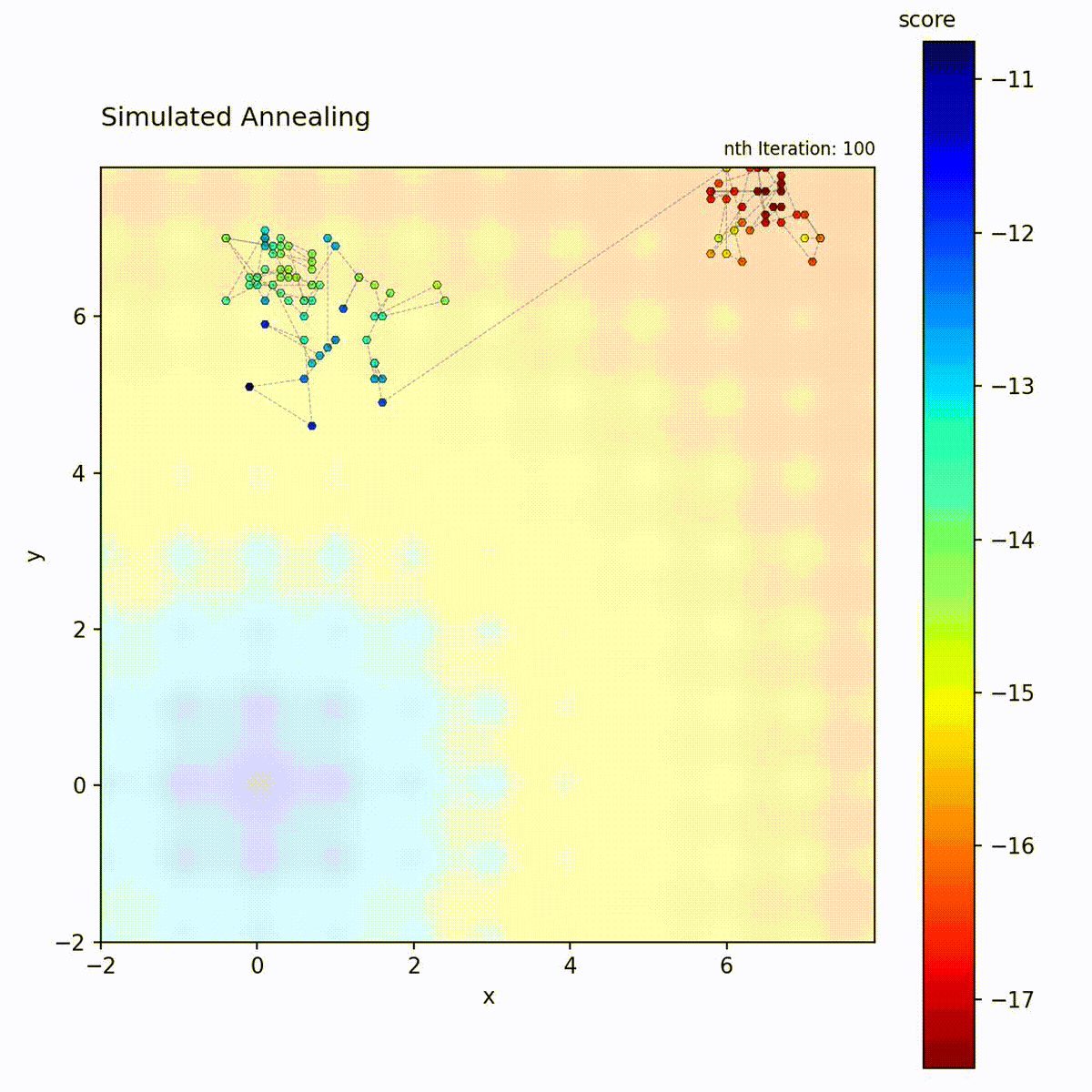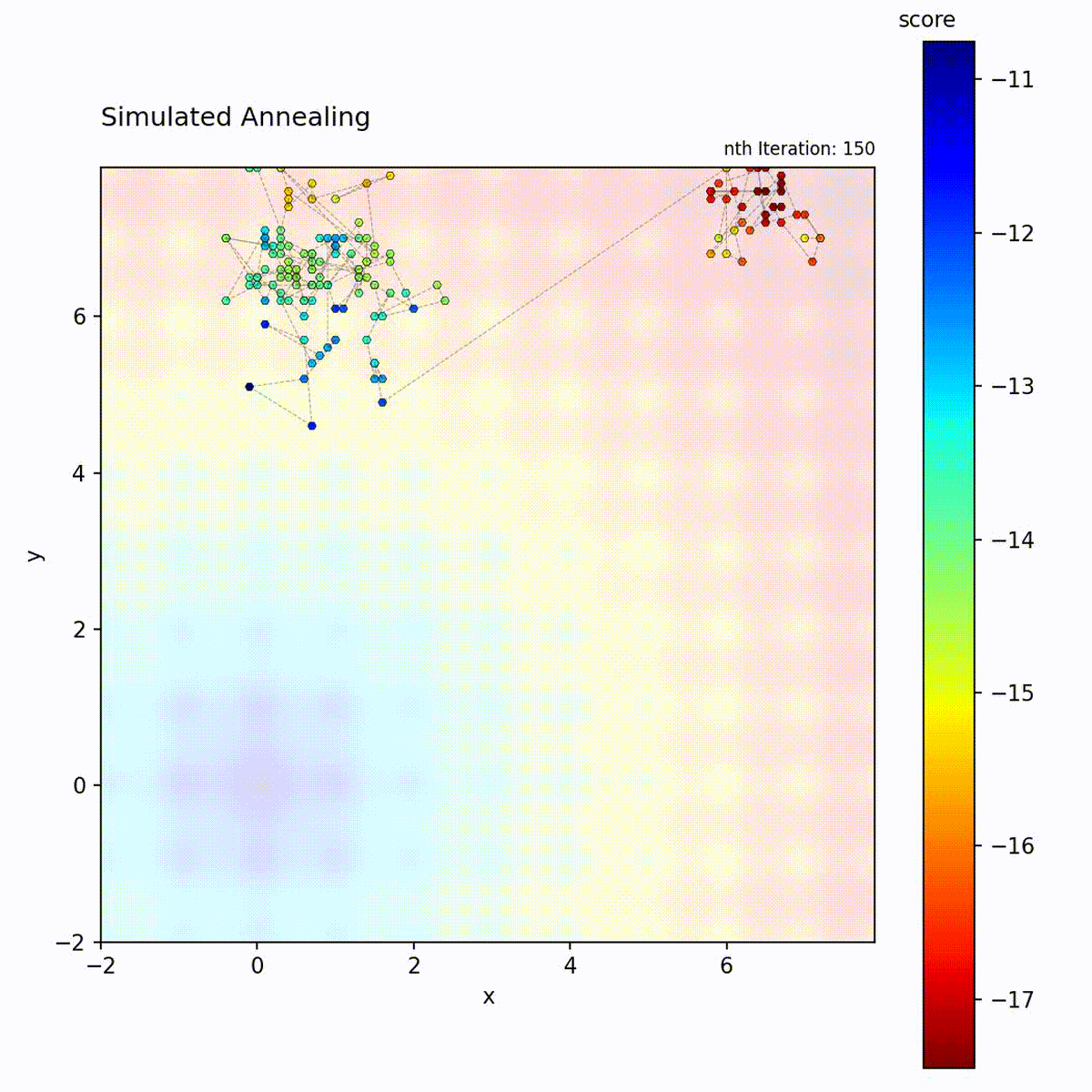
Multi-modal function: Temperature allows escaping local optima early in the search.
The temperature schedule creates a controlled transition from exploration to
exploitation, which is the key distinction from the other local search methods in
this library. Stochastic Hill Climbing offers a constant acceptance rate with no
transition, while Repulsing Hill Climbing adapts its step size reactively.
Simulated Annealing follows a predetermined schedule regardless of search
progress. Choose it for multi-modal landscapes where early broad exploration is
needed before converging to a specific region. The two schedule parameters
(start_temp and annealing_rate) must be tuned relative to the iteration
budget: slower cooling requires more iterations to converge but explores more of
the search space.
Algorithm
At each iteration:
Generate a neighbor within
epsilondistanceCalculate score difference:
delta = new_score - current_scoreIf
delta > 0(improvement): accept the moveIf
delta < 0(worse): accept with probabilityexp(delta / temperature)Decrease temperature:
temperature = temperature * annealing_rate
As temperature decreases, the probability of accepting worse solutions approaches zero, and the algorithm behaves more like Hill Climbing.
Note
The acceptance probability exp(delta / temperature)
depends on both the quality difference and the current temperature. Early
in the search, even large degradations are accepted frequently. Late in
the search, only tiny degradations have any chance. This provides a smooth,
principled transition from exploration to exploitation.

The Simulated Annealing loop: generate neighbor, apply Metropolis criterion, and cool the temperature.
The Temperature Schedule
temperature(t) = start_temp * annealing_rate^t
Example with start_temp=1.0, annealing_rate=0.97:
- Iteration 0: temp = 1.000
- Iteration 10: temp = 0.737
- Iteration 50: temp = 0.218
- Iteration 100: temp = 0.048
- Iteration 200: temp = 0.002
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
float |
0.97 |
Temperature decay rate per iteration (0 < rate < 1) |
|
float |
1.0 |
Initial temperature |
|
float |
0.03 |
Step size |
|
str |
“normal” |
Step distribution |
|
int |
3 |
Number of neighbors per iteration |
Tuning the Temperature
annealing_rate:
Higher (0.99): Slower cooling, more exploration, needs more iterations
Lower (0.90): Faster cooling, quicker convergence, may miss global optimum
start_temp:
Higher: More initial exploration, accepts more bad moves early
Lower: More conservative, behaves more like Hill Climbing from the start
Tip
A good rule of thumb: set start_temp such that early acceptance
probability for typical bad moves is around 0.5-0.8.
Example
import numpy as np
from gradient_free_optimizers import SimulatedAnnealingOptimizer
def schwefel(para):
x, y = para["x"], para["y"]
return -418.9829 * 2 + x * np.sin(np.sqrt(abs(x))) + y * np.sin(np.sqrt(abs(y)))
search_space = {
"x": np.linspace(-500, 500, 1000),
"y": np.linspace(-500, 500, 1000),
}
opt = SimulatedAnnealingOptimizer(
search_space,
annealing_rate=0.98, # Slow cooling
start_temp=1.5, # High initial temperature
)
opt.search(schwefel, n_iter=2000)
print(f"Best: {opt.best_para}, Score: {opt.best_score}")
When to Use
Good for:
Multi-modal functions with many local optima
When you want controlled transition from exploration to exploitation
Problems where you can afford many iterations
Compared to other algorithms:
vs. Stochastic HC: SA adapts acceptance over time, SHC keeps it constant
vs. Random Restart HC: SA transitions smoothly, RRHC restarts abruptly
vs. Parallel Tempering: SA uses one temperature, PT uses multiple in parallel
Adaptive Strategies
For very long runs, you might want to adjust the annealing rate:
# Slower cooling for more iterations
opt = SimulatedAnnealingOptimizer(
search_space,
annealing_rate=0.995, # Very slow cooling
start_temp=2.0,
)
opt.search(objective, n_iter=5000)
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import SimulatedAnnealingOptimizer
def rastrigin_5d(para):
A = 10
vals = [para[f"x{i}"] for i in range(5)]
return -(A * len(vals) + sum(
v**2 - A * np.cos(2 * np.pi * v) for v in vals
))
search_space = {
f"x{i}": np.linspace(-5.12, 5.12, 200)
for i in range(5)
}
opt = SimulatedAnnealingOptimizer(
search_space,
annealing_rate=0.995,
start_temp=2.0,
epsilon=0.08,
)
opt.search(rastrigin_5d, n_iter=5000)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Controlled by
annealing_rateandstart_temp. Slower cooling gives more exploration but needs more iterations.Computational overhead: Same as Hill Climbing (minimal).
Parameter sensitivity: The cooling schedule is critical. If temperature drops too fast, the algorithm becomes a greedy Hill Climber before exploring enough. If too slow, it wastes iterations accepting bad moves.