DIRECT Algorithm
DIRECT (DIviding RECTangles) partitions the search space into hyperrectangles and recursively subdivides them. At each iteration, it evaluates the objective at the center of each rectangle and identifies “potentially optimal” rectangles: those that lie on the Pareto front of center-point value versus rectangle size. These selected rectangles are subdivided further, while others are left intact. This selection criterion means that both high-value small rectangles and large unexplored rectangles are refined simultaneously.
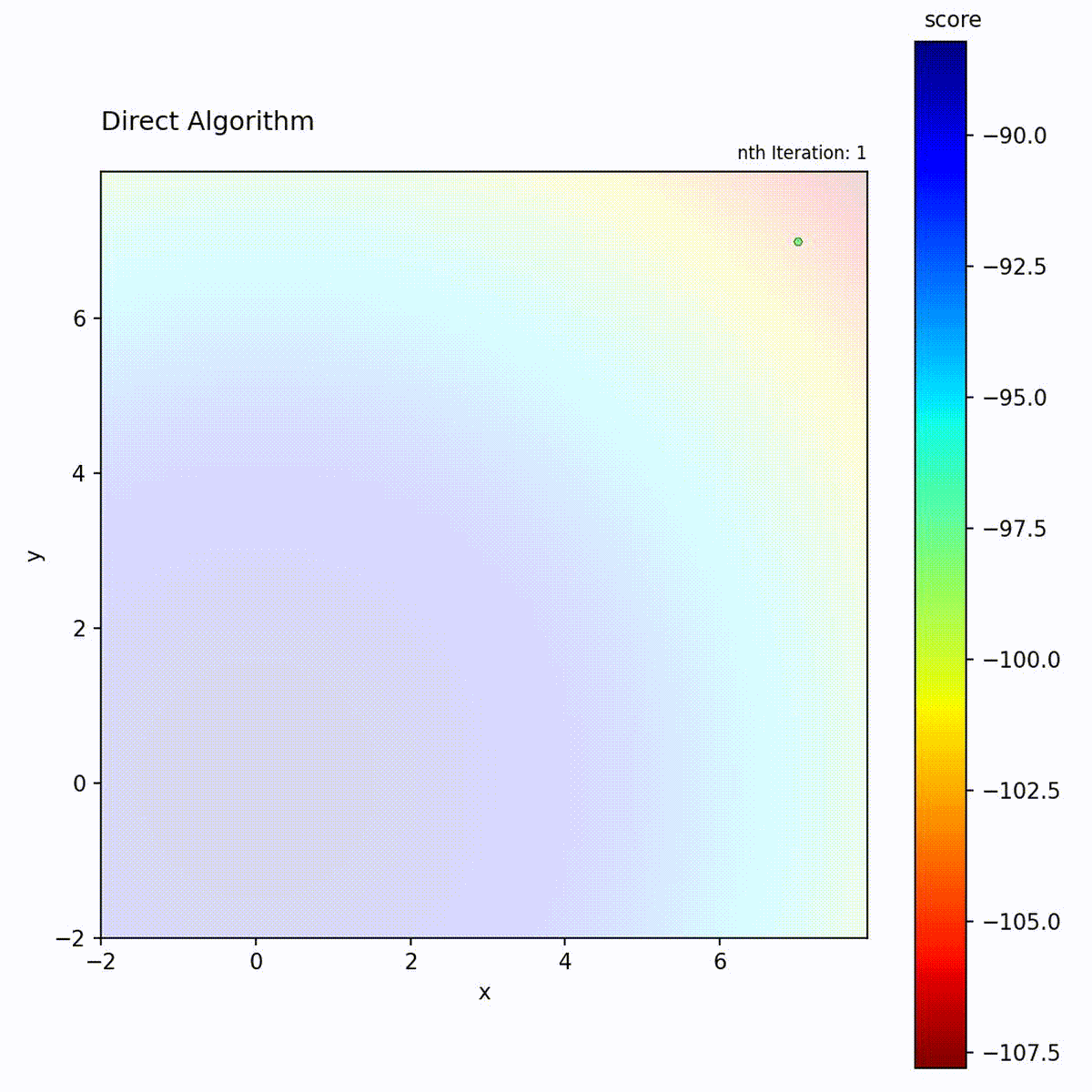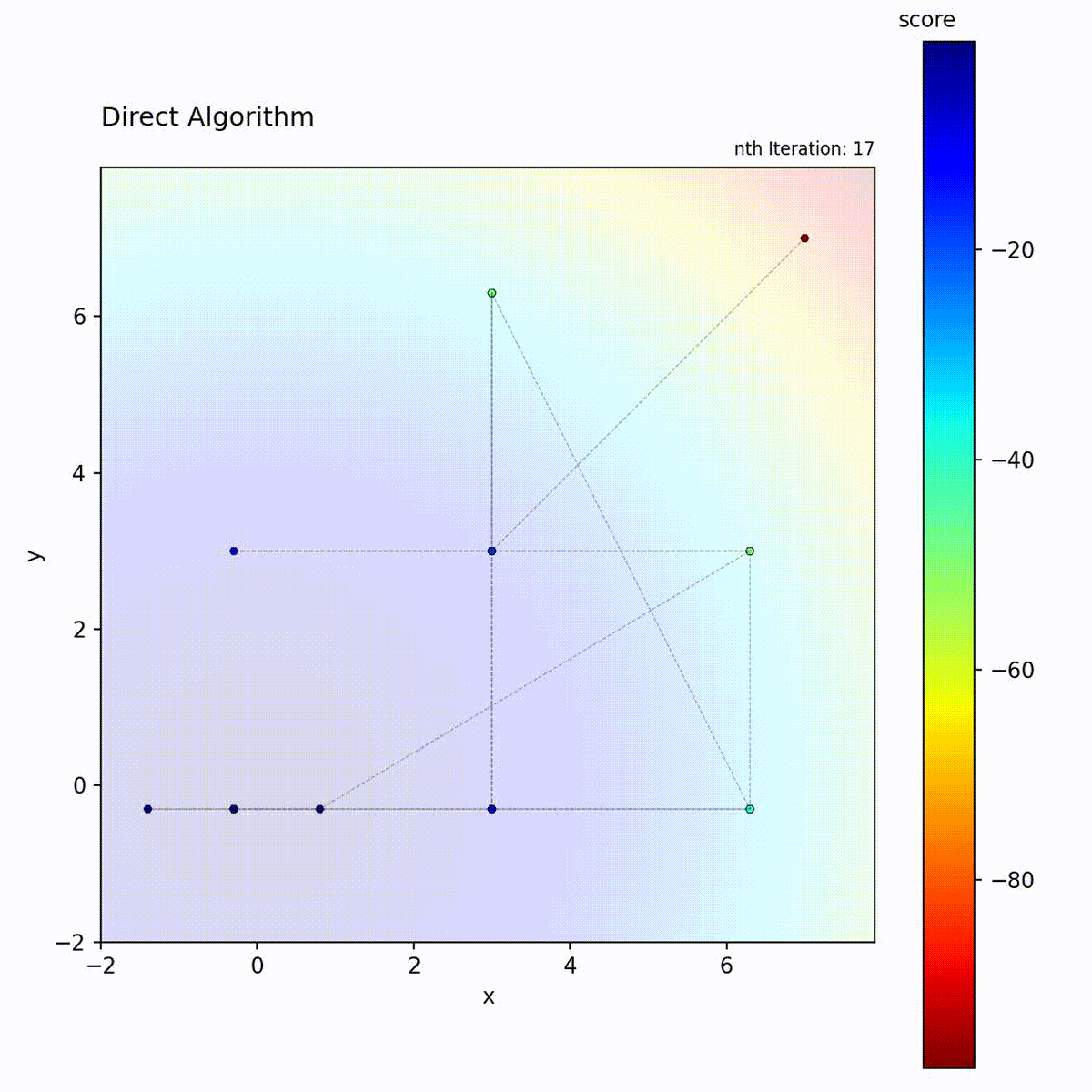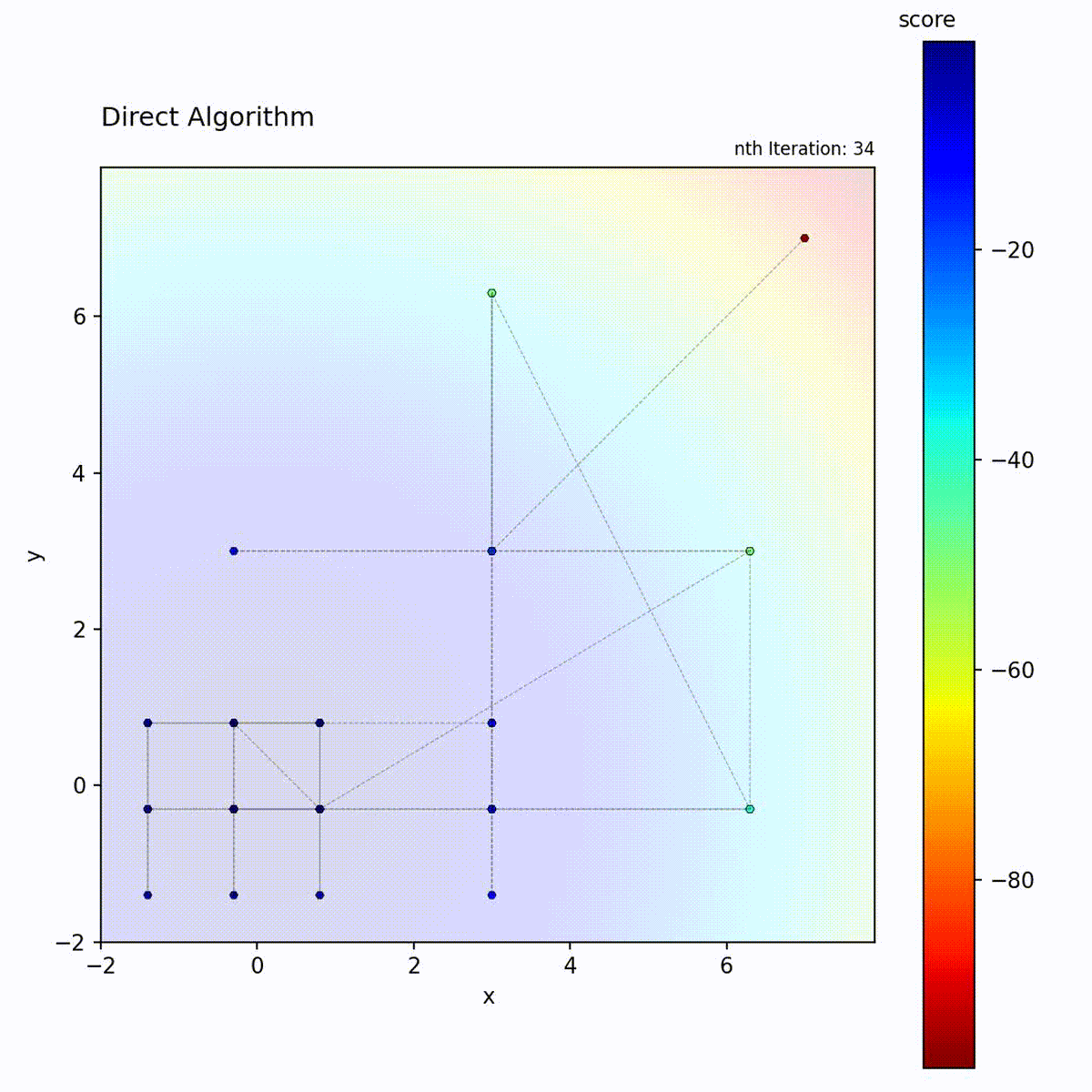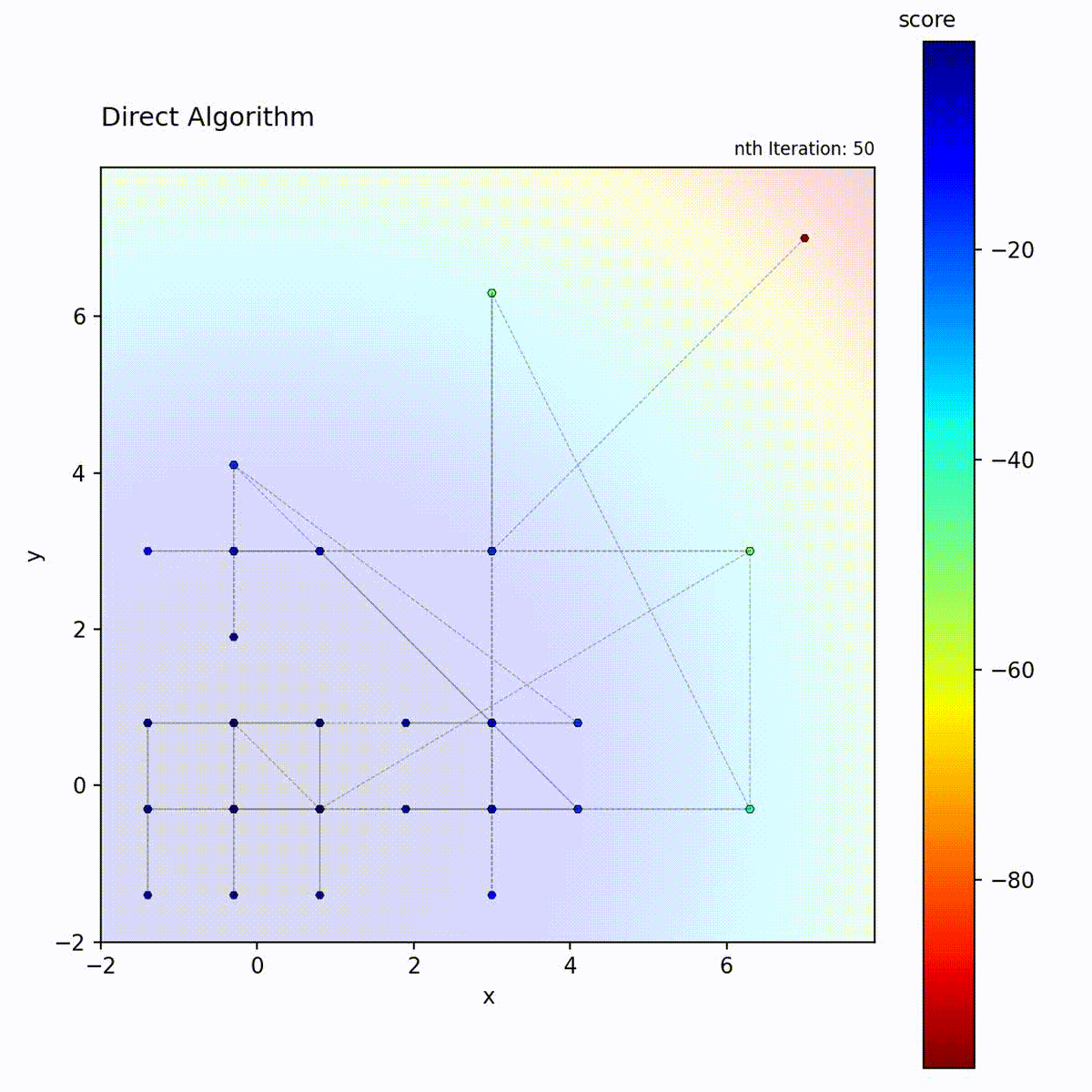
Convex function: Hierarchical division focuses quickly.
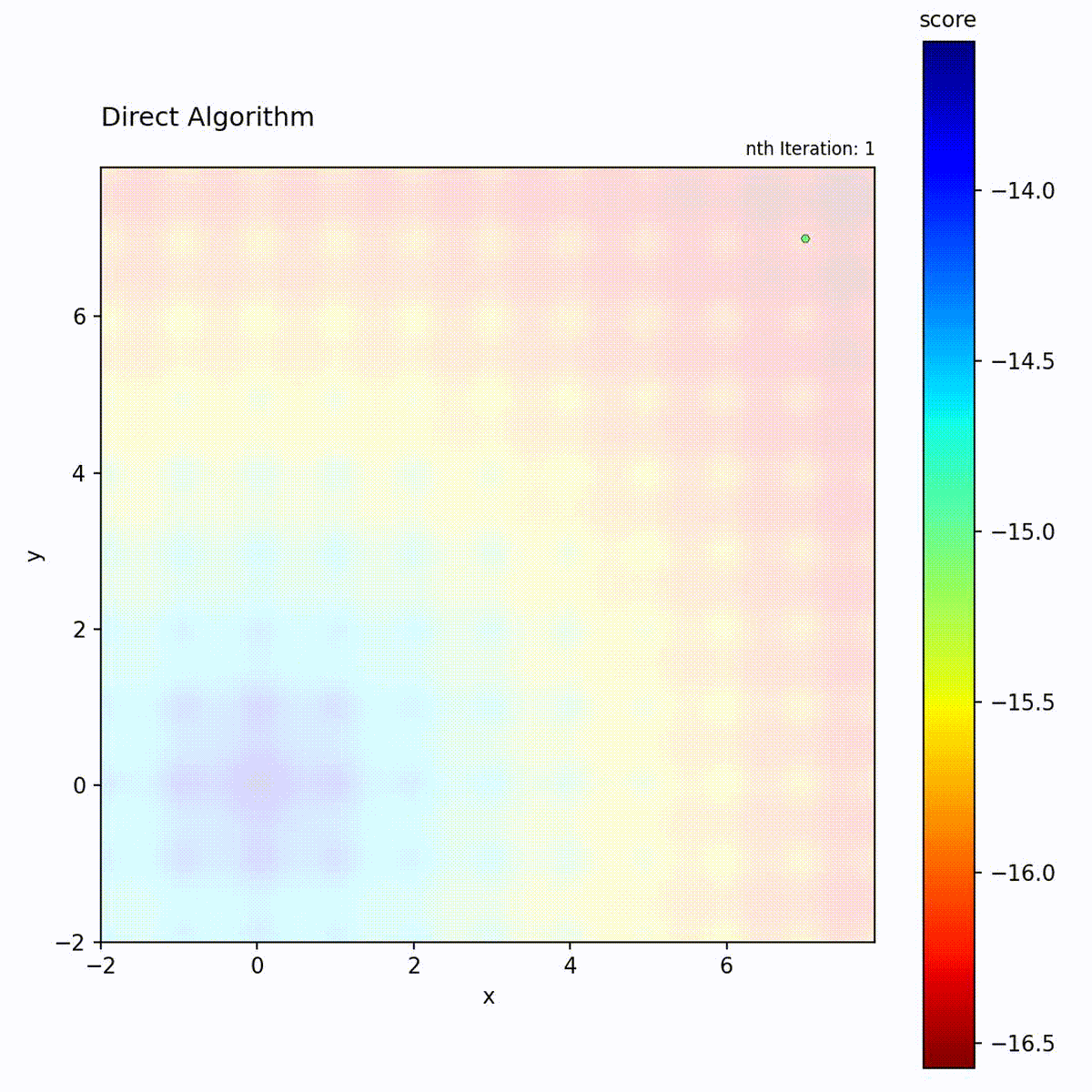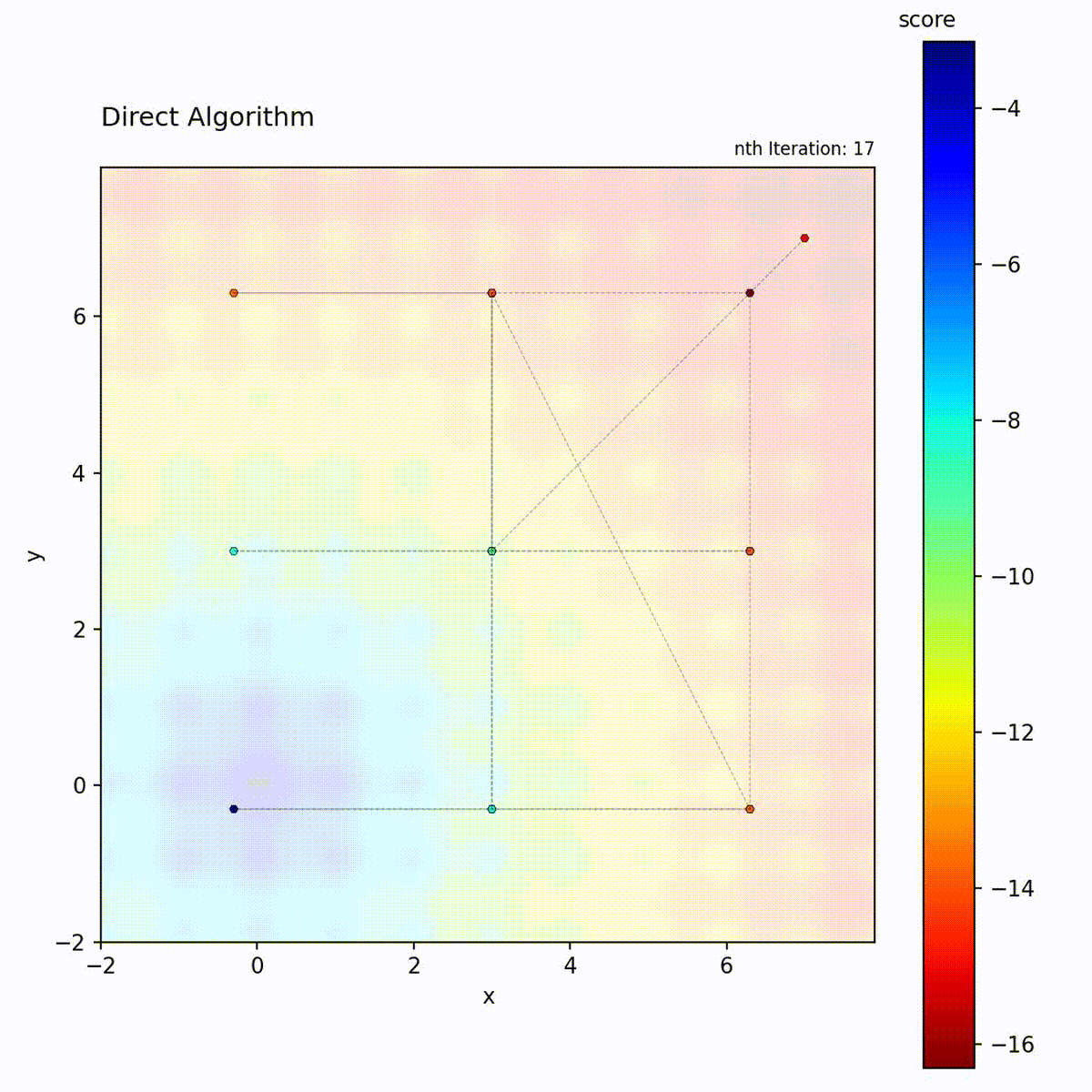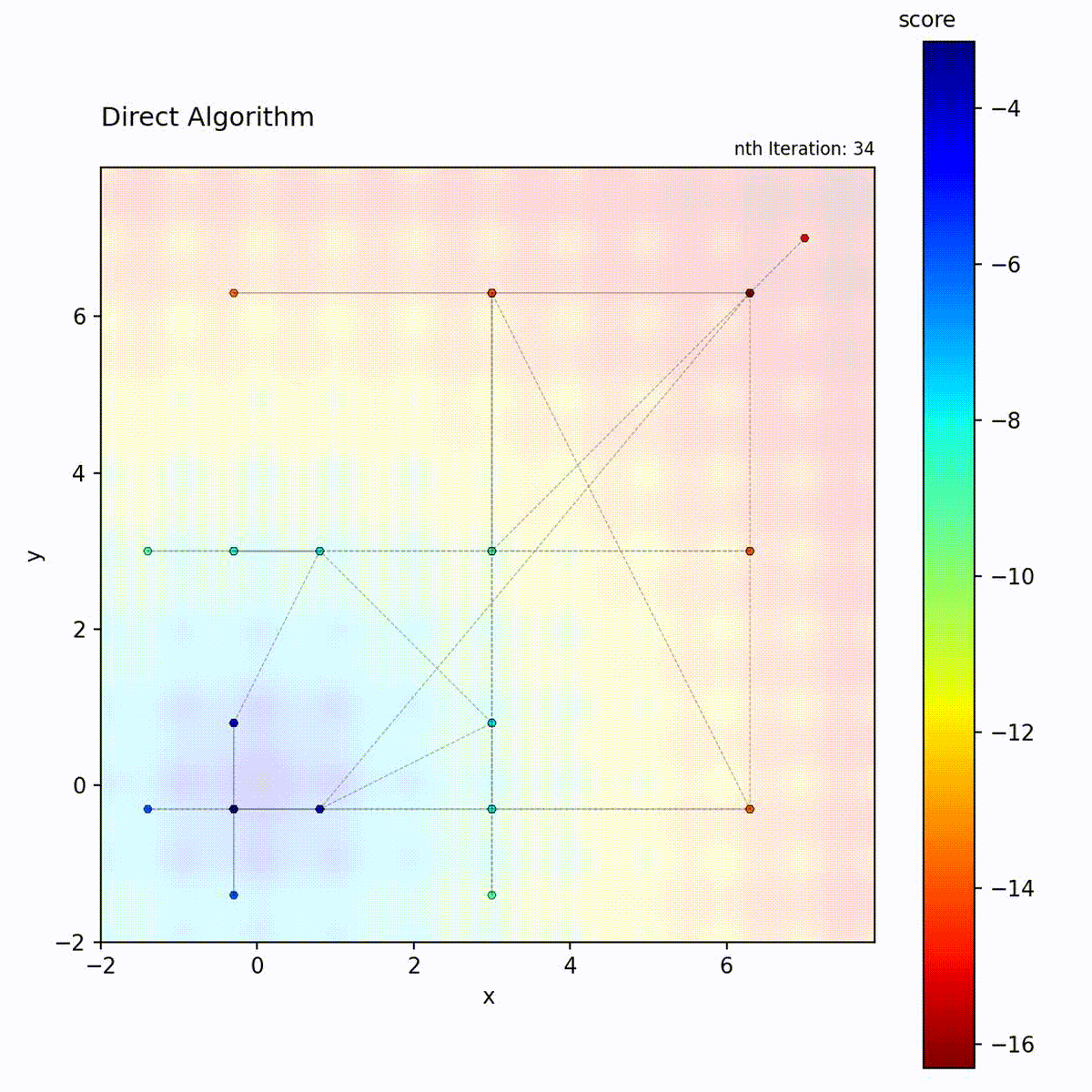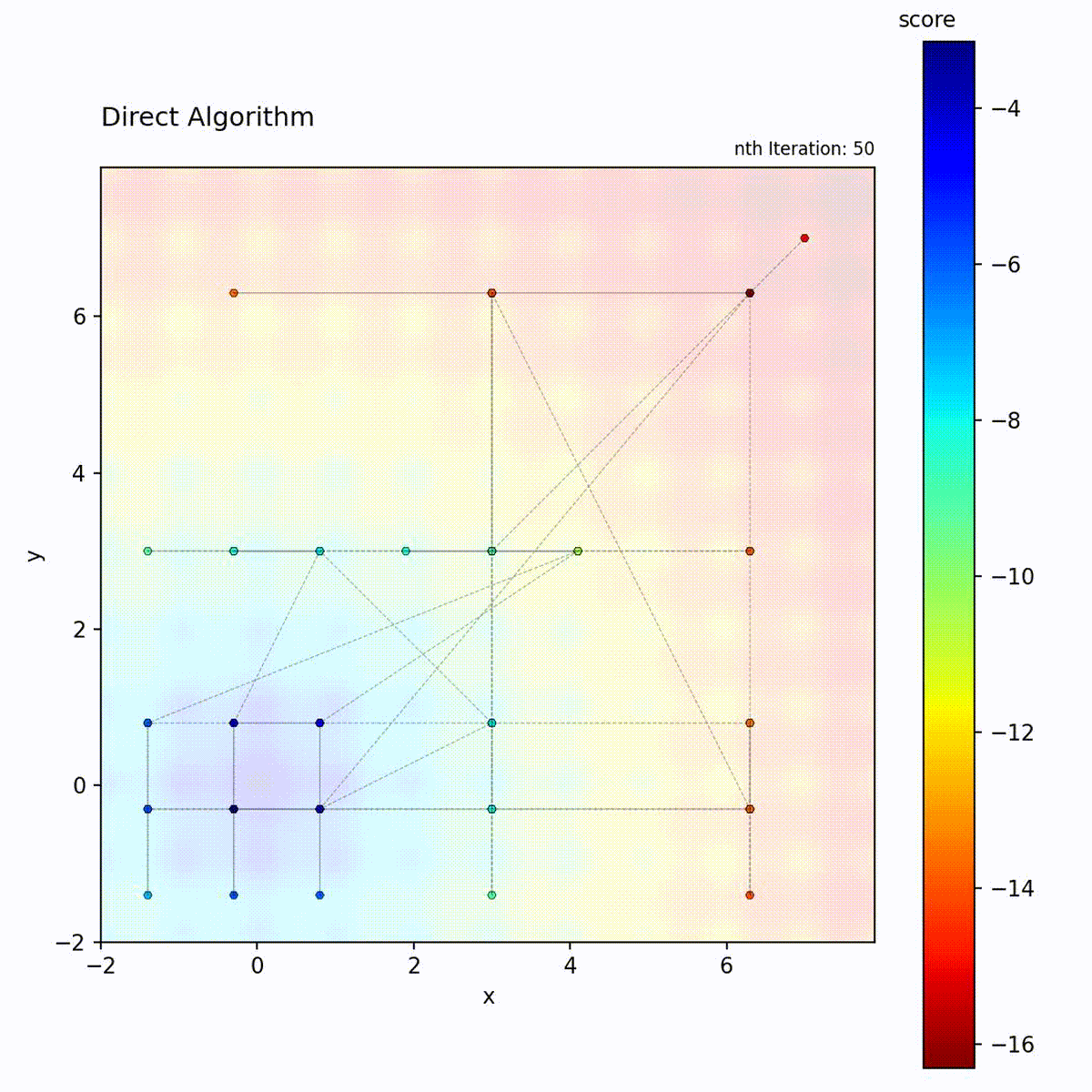
Multi-modal function: Balanced exploration and exploitation.
DIRECT is deterministic, requires no algorithm-specific hyperparameters, and is provably convergent to the global optimum given sufficient iterations. Unlike the Lipschitz Optimizer, which requires estimating a single Lipschitz constant, DIRECT implicitly considers all possible constant values through its Pareto-based selection criterion, making it more robust when the smoothness of the objective is unknown. The number of rectangles grows with each iteration and with dimensionality, which limits practical use to low and moderate dimensions. Choose DIRECT when you need deterministic global search with convergence guarantees and no tuning. Prefer the Lipschitz Optimizer when the objective is known to be smooth, because its single-constant bound can prune larger portions of the search space per iteration, reaching the optimum in fewer evaluations on such functions.
Algorithm
DIRECT works by:
Evaluate the center of the search space
Divide the space into smaller hyperrectangles
For each rectangle, compute a potential based on:
The function value at the center
The size of the rectangle (larger = more unexplored)
Select potentially optimal rectangles (Pareto-optimal in value vs. size)
Divide selected rectangles and repeat
This approach balances:
Exploitation: Focus on regions with good values
Exploration: Continue investigating large, unexplored regions
Note
DIRECT’s “potentially optimal” selection is the key to its balance. A rectangle is potentially optimal if no other rectangle is both smaller and has a better center value. This Pareto criterion ensures that both small rectangles in good regions AND large unexplored rectangles are selected, providing provable convergence without any tuning.
Key Properties
Deterministic: Same results for same input
Global convergence: Guaranteed to find global optimum as iterations increase
No hyperparameters: Self-adapting division strategy
Lipschitz-free: Doesn’t require knowledge of Lipschitz constant
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
dict |
{“random”: 1000000} |
Sampling strategy for candidates |
|
int |
10000000 |
Maximum sample size |
Example
import numpy as np
from gradient_free_optimizers import DirectAlgorithm
def schwefel(para):
x, y = para["x"], para["y"]
return (x * np.sin(np.sqrt(abs(x))) +
y * np.sin(np.sqrt(abs(y))))
search_space = {
"x": np.linspace(-500, 500, 1000),
"y": np.linspace(-500, 500, 1000),
}
opt = DirectAlgorithm(search_space)
opt.search(schwefel, n_iter=100)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
When to Use
Good for:
Global optimization with convergence guarantees
Unknown landscapes where you need both exploration and exploitation
Problems where you want deterministic, reproducible results
Not ideal for:
Very high-dimensional spaces (rectangle count grows exponentially)
Problems with cheap evaluations where simpler methods suffice
Comparison with Other Global Methods
Algorithm |
Approach |
Guarantees |
|---|---|---|
DIRECT |
Hierarchical division |
Global convergence |
Lipschitz |
Bound-based pruning |
Requires smoothness |
Random Search |
Pure random |
Probabilistic |
Bayesian |
Surrogate model |
None (model-based) |
3D Example
import numpy as np
from gradient_free_optimizers import DirectAlgorithm
def ackley_3d(para):
import math
vals = [para["x"], para["y"], para["z"]]
n = len(vals)
sum_sq = sum(v**2 for v in vals) / n
sum_cos = sum(np.cos(2 * math.pi * v) for v in vals) / n
return -(- 20 * np.exp(-0.2 * np.sqrt(sum_sq))
- np.exp(sum_cos) + 20 + math.e)
search_space = {
"x": np.linspace(-5, 5, 200),
"y": np.linspace(-5, 5, 200),
"z": np.linspace(-5, 5, 200),
}
opt = DirectAlgorithm(search_space)
opt.search(ackley_3d, n_iter=200)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Automatically balanced through the “potentially optimal” rectangle selection. No parameters to tune.
Computational overhead: Moderate. Rectangle management and selection adds overhead that grows with the number of iterations.
Parameter sensitivity: DIRECT has no tunable hyperparameters, which is both a strength (robust) and limitation (no way to bias the search).