Random Search
Random Search samples positions uniformly at random from the search space and retains the best result found across all iterations. Each candidate position is drawn independently, with no dependence on previously evaluated points. The algorithm maintains no model, performs no local refinement, and applies no selection pressure between iterations. It is a pure exploration strategy with zero exploitation.
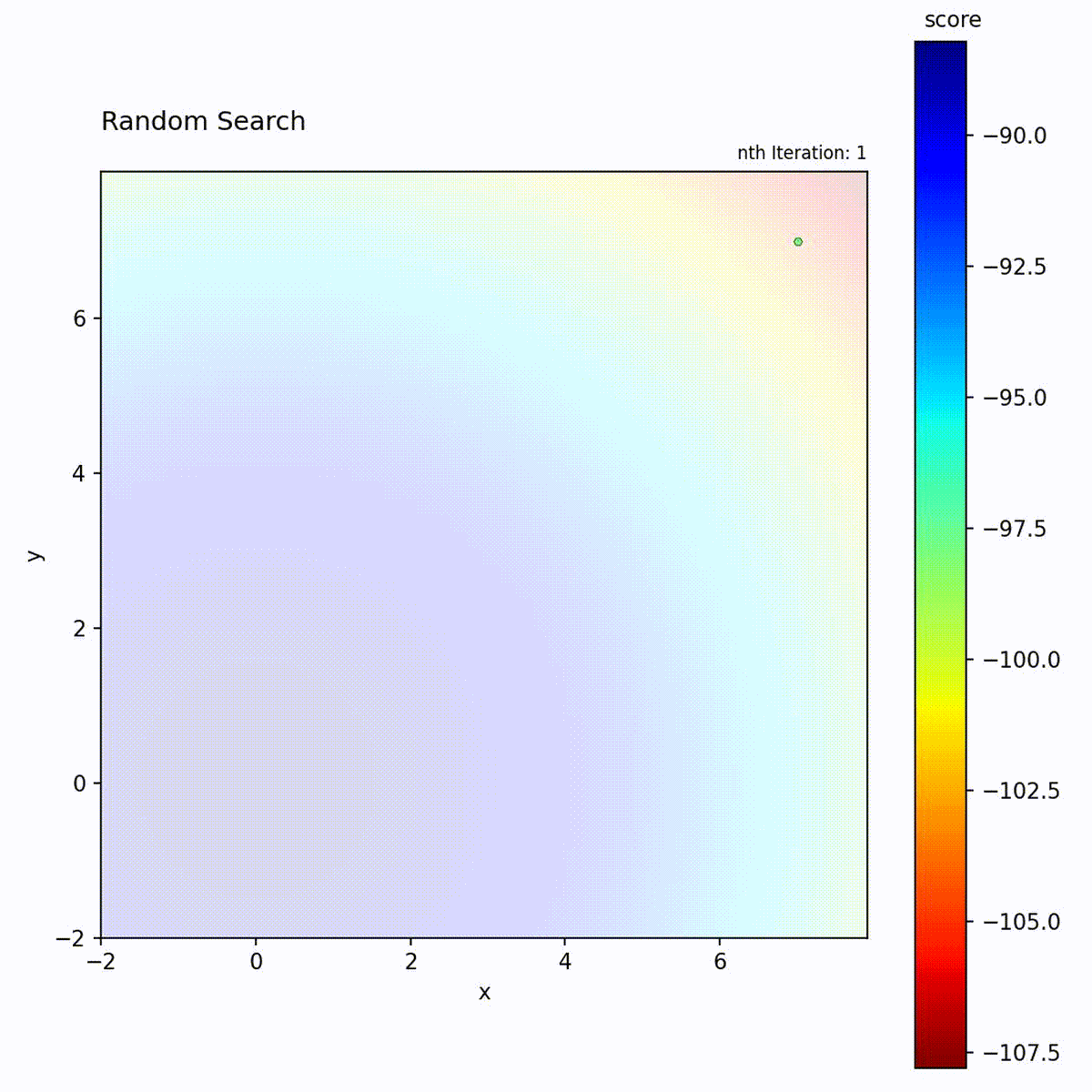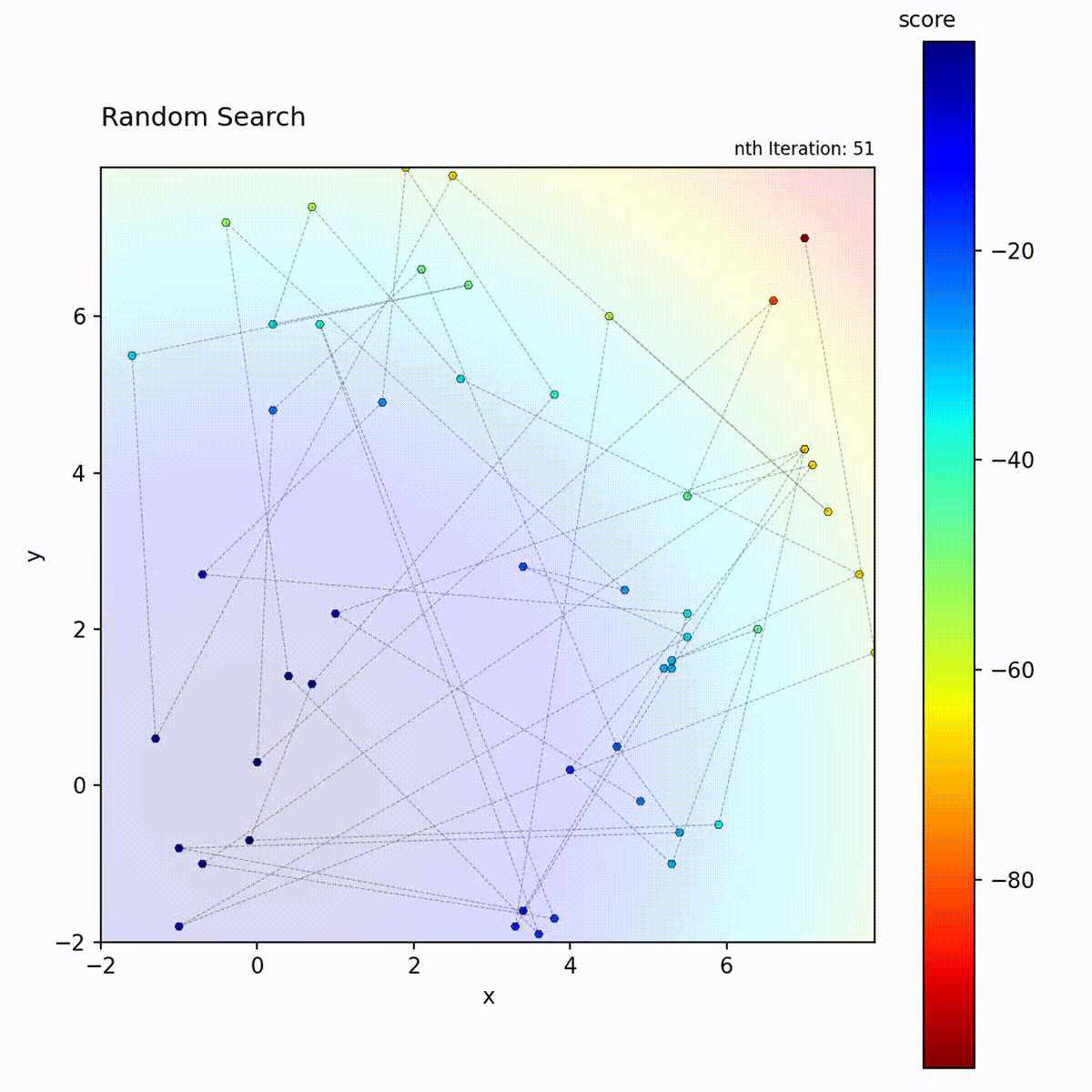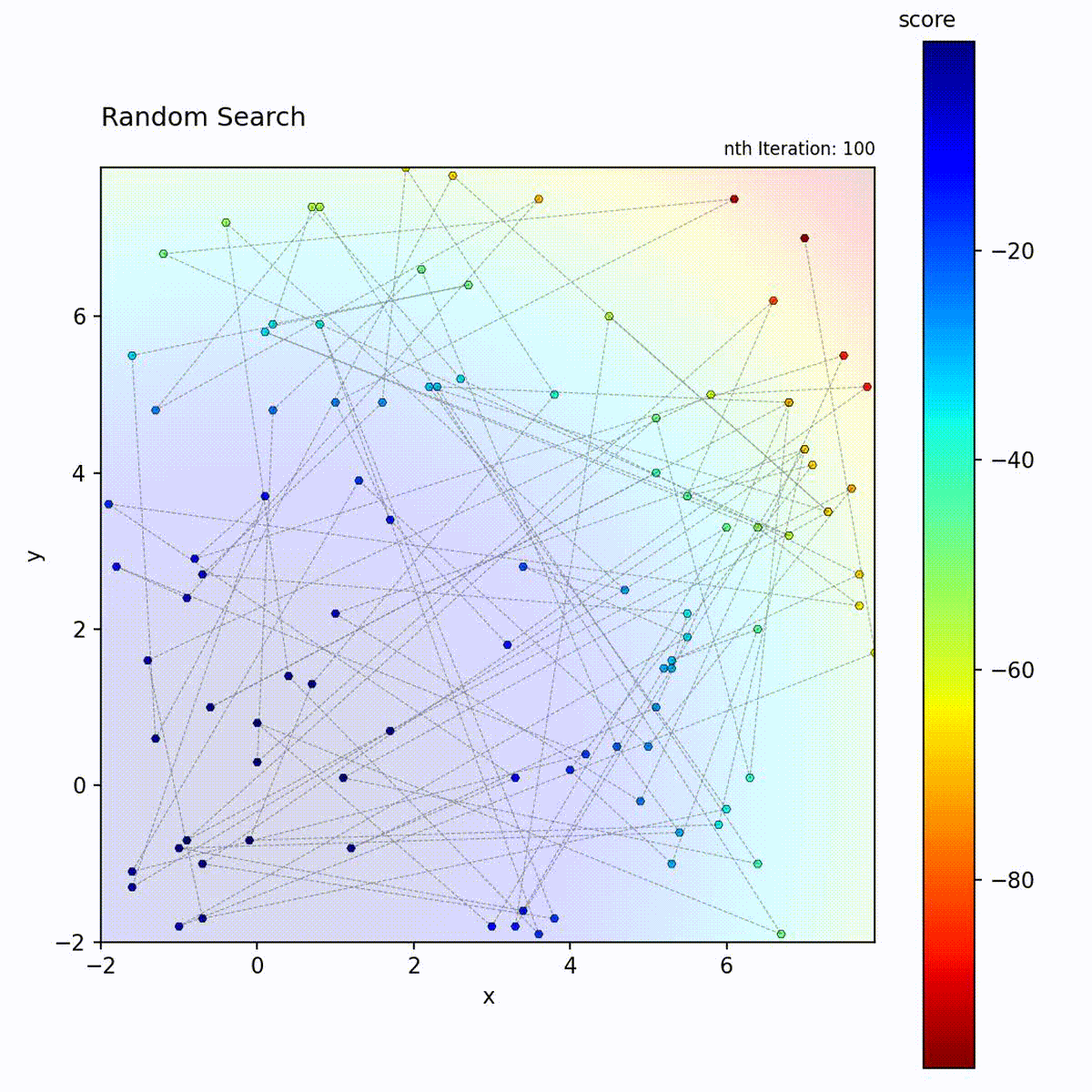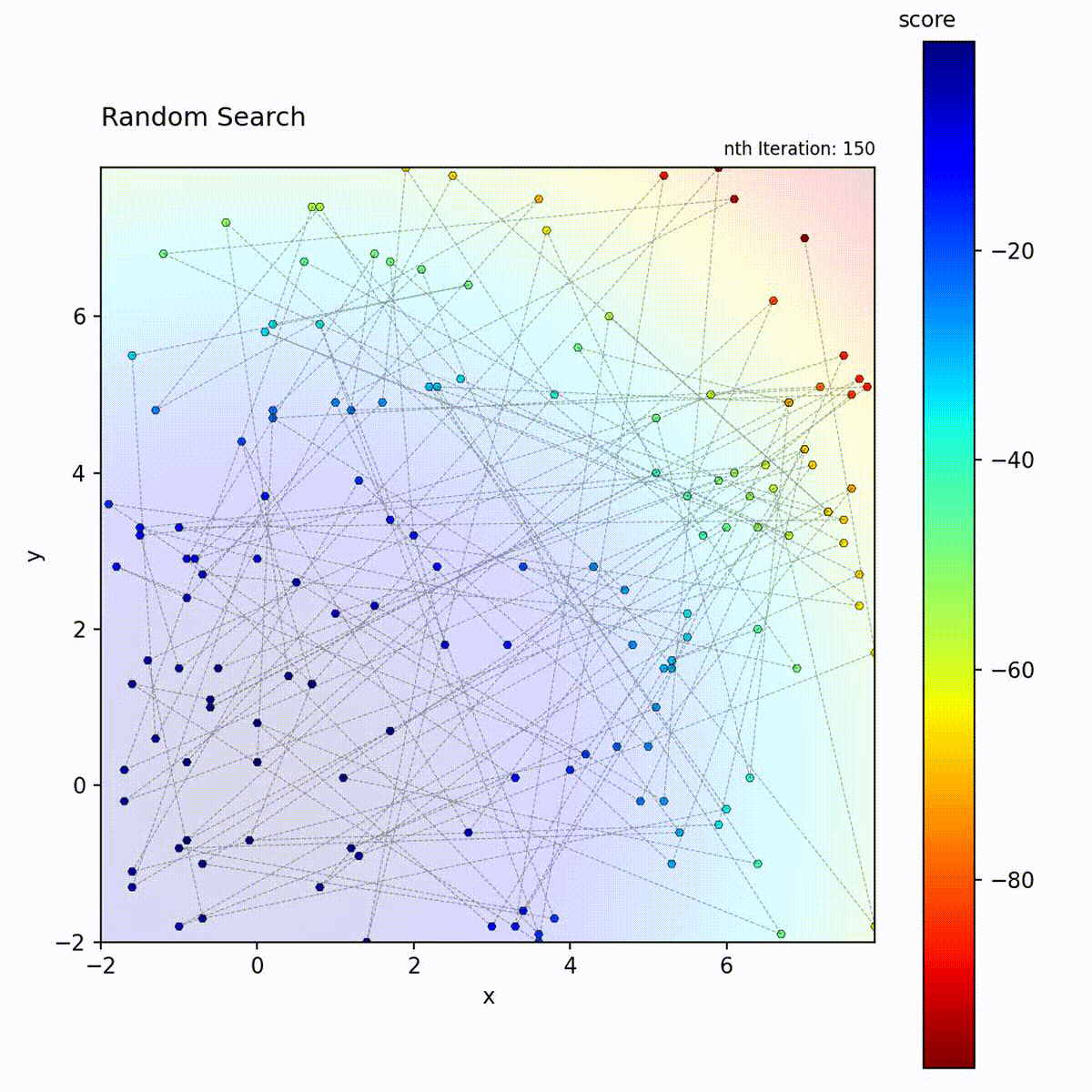
Convex function: Samples uniformly across the space.
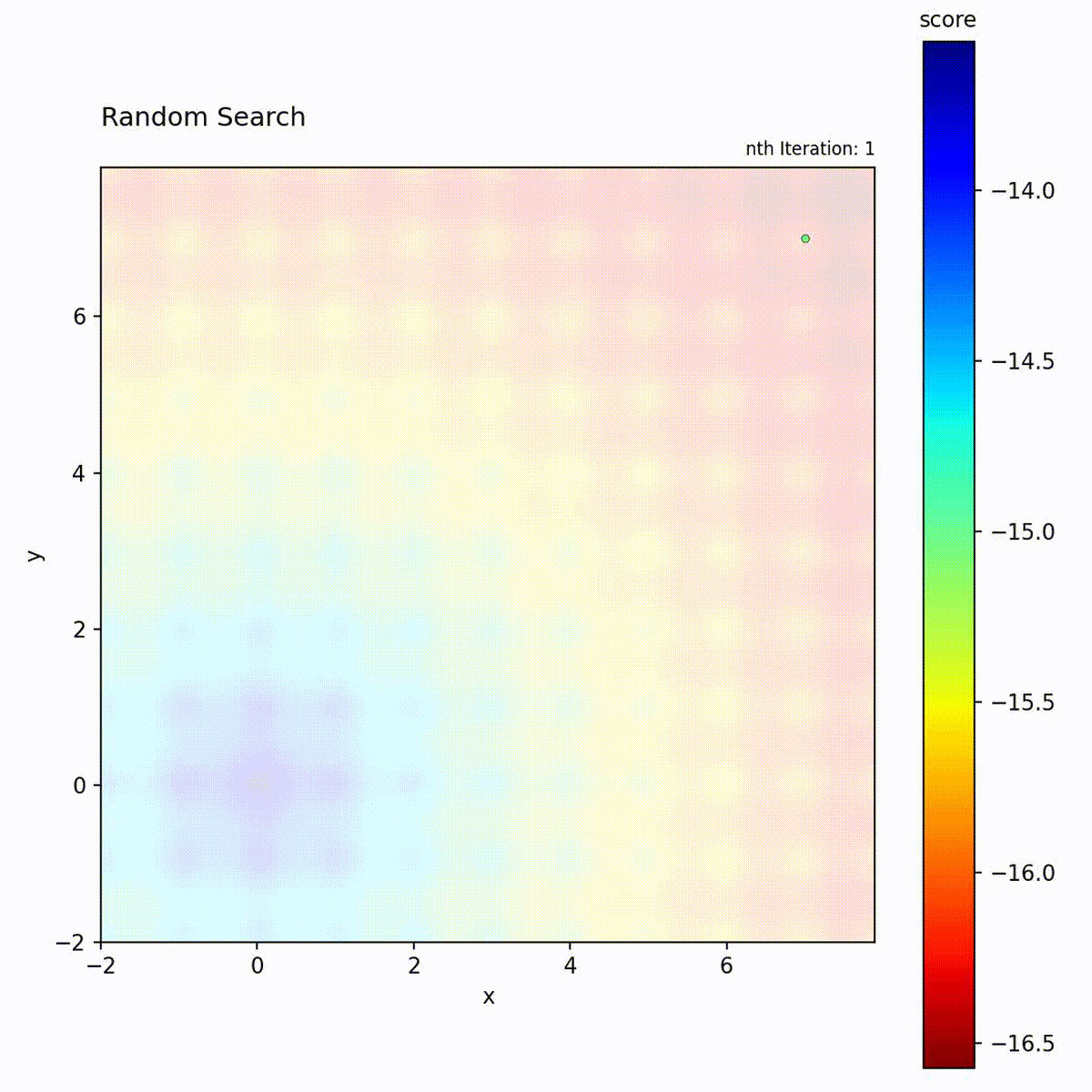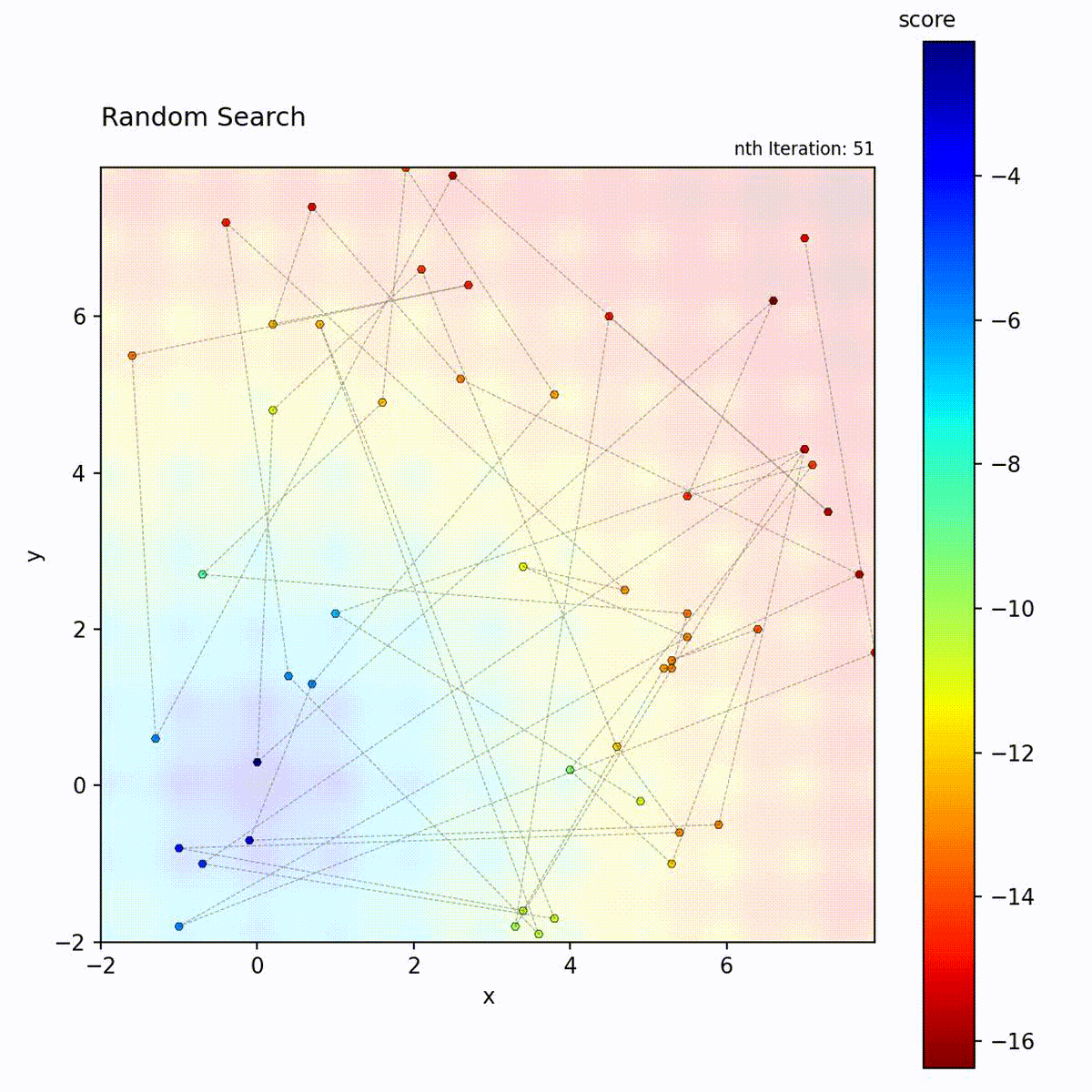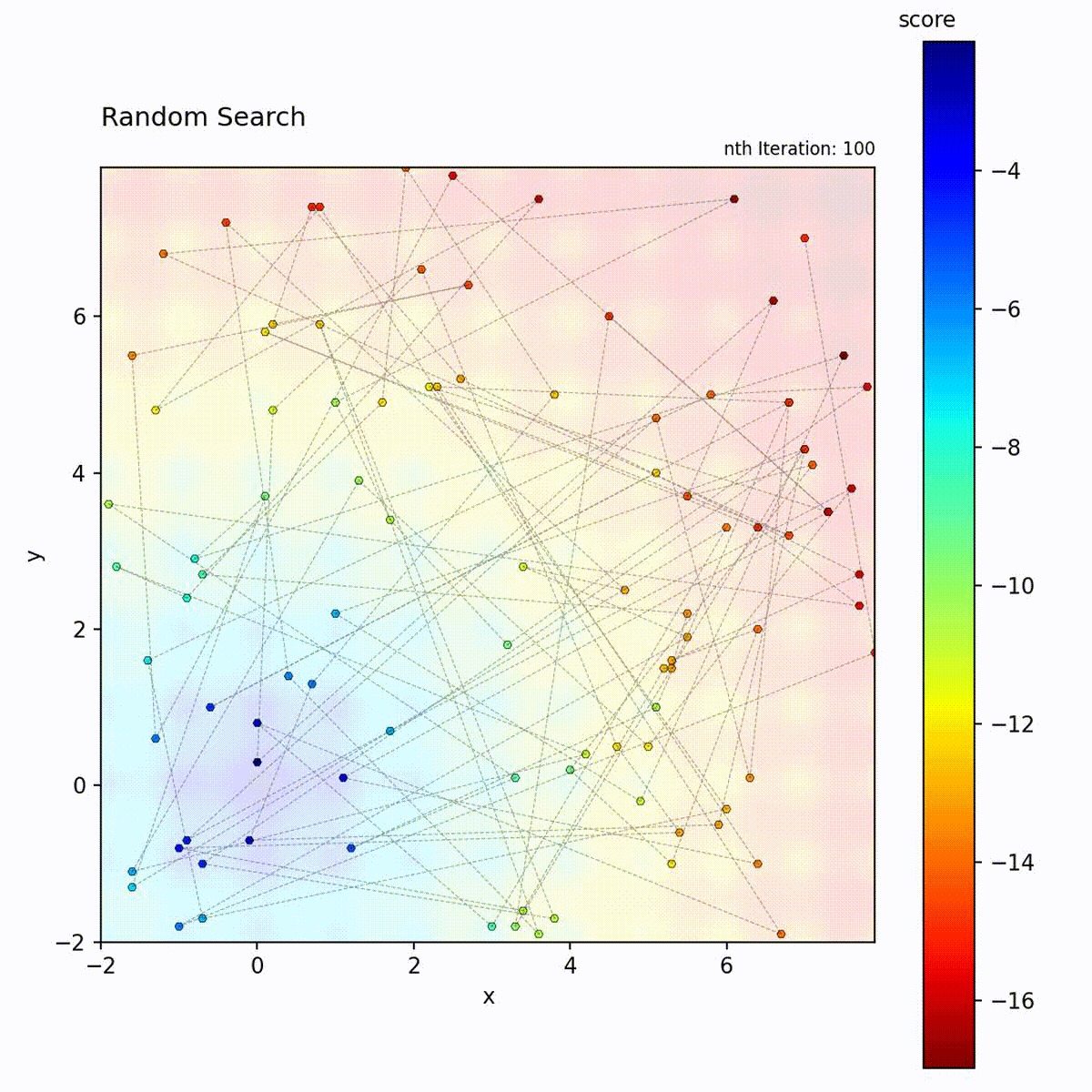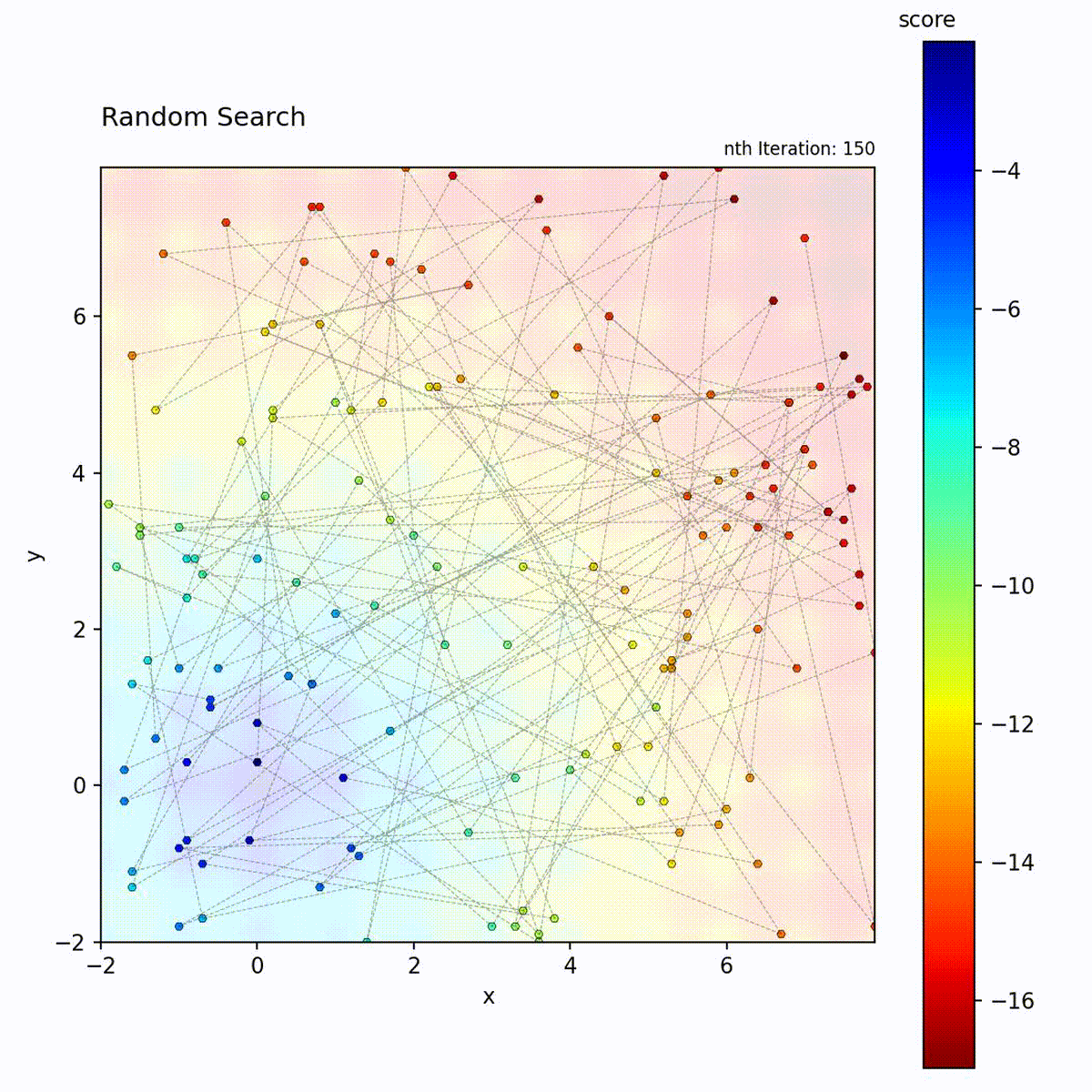
Multi-modal function: No bias toward any region, samples the entire space.
Random Search serves as the baseline against which all other optimizers in this library should be compared. Unlike Grid Search, it projects well onto important subspaces: in a high-dimensional problem where only a few parameters matter, random samples distribute their resolution across those dimensions rather than wasting evaluations on a fixed grid. It requires no algorithm-specific parameters and is trivially parallelizable since every evaluation is independent. Use Random Search when function evaluations are cheap and plentiful, when you need a reference baseline, or when you have no prior information about the objective landscape.
Algorithm
At each iteration:
Generate a random position in the search space
Evaluate the objective function
If better than current best, update best
pos = uniform_random(search_space)
score = objective(pos)
if score > best_score:
best_score, best_pos = score, pos
That’s it. No memory, no adaptation, no information sharing.
Why Random Search Matters
Random Search is more important than it might seem:
Baseline comparison: Any serious optimizer should beat Random Search. If it doesn’t, the problem may not benefit from intelligent search.
High dimensions: In very high-dimensional spaces, random sampling can be surprisingly competitive with more sophisticated methods.
Embarrassingly parallel: Every evaluation is independent, making it trivially parallelizable.
No hyperparameters: Nothing to tune, no risk of misconfiguration.
Note
Research has shown that for many hyperparameter tuning problems, Random Search performs nearly as well as Bayesian Optimization when given the same computational budget.
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
dict |
required |
Parameter space definition |
|
dict |
{“grid”: 4, “random”: 2, “vertices”: 4} |
Initialization strategy |
|
list |
[] |
Constraint functions |
|
int |
None |
Random seed for reproducibility |
Random Search has no algorithm-specific parameters.
Example
import numpy as np
from gradient_free_optimizers import RandomSearchOptimizer
def objective(para):
x, y = para["x"], para["y"]
return -(x**2 + y**2)
search_space = {
"x": np.linspace(-10, 10, 1000),
"y": np.linspace(-10, 10, 1000),
}
opt = RandomSearchOptimizer(search_space, random_state=42)
opt.search(objective, n_iter=1000)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
When to Use
Good for:
Establishing a baseline for comparison
Problems with very cheap function evaluations
Very high-dimensional spaces
When you need trivial parallelization
When you’re not sure what optimizer to use
Not ideal for:
Expensive function evaluations (wastes budget)
When you need to converge precisely
When you have good starting points to exploit
Comparison with Grid Search
Aspect |
Random Search |
Grid Search |
|---|---|---|
Coverage |
Probabilistic |
Deterministic |
High dimensions |
Scales well |
Curse of dimensionality |
Important dimensions |
Good (projects better) |
Poor (spreads evenly) |
Reproducibility |
With random_state |
Always identical |
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import RandomSearchOptimizer
def sphere_5d(para):
return -sum(para[f"x{i}"]**2 for i in range(5))
search_space = {
f"x{i}": np.linspace(-10, 10, 500)
for i in range(5)
}
opt = RandomSearchOptimizer(search_space, random_state=42)
opt.search(sphere_5d, n_iter=5000)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Pure exploration, zero exploitation. Every sample is independent of all previous samples.
Computational overhead: Effectively zero. The only cost is the objective function evaluation itself.
Parameter sensitivity: None. Random Search has no algorithm-specific parameters to tune, which is both its greatest strength and limitation.