Random Annealing
Random Annealing applies an exponential decay schedule to the step size rather
than to the acceptance probability. At each iteration, a neighbor is sampled
within a radius proportional to epsilon * start_temp * annealing_rate^t,
where t is the current iteration. The algorithm only accepts the neighbor if
it improves on the current position; worse solutions are never accepted. As the
step size shrinks over iterations, the search transitions from broad spatial
coverage to fine-grained local refinement around the current position.
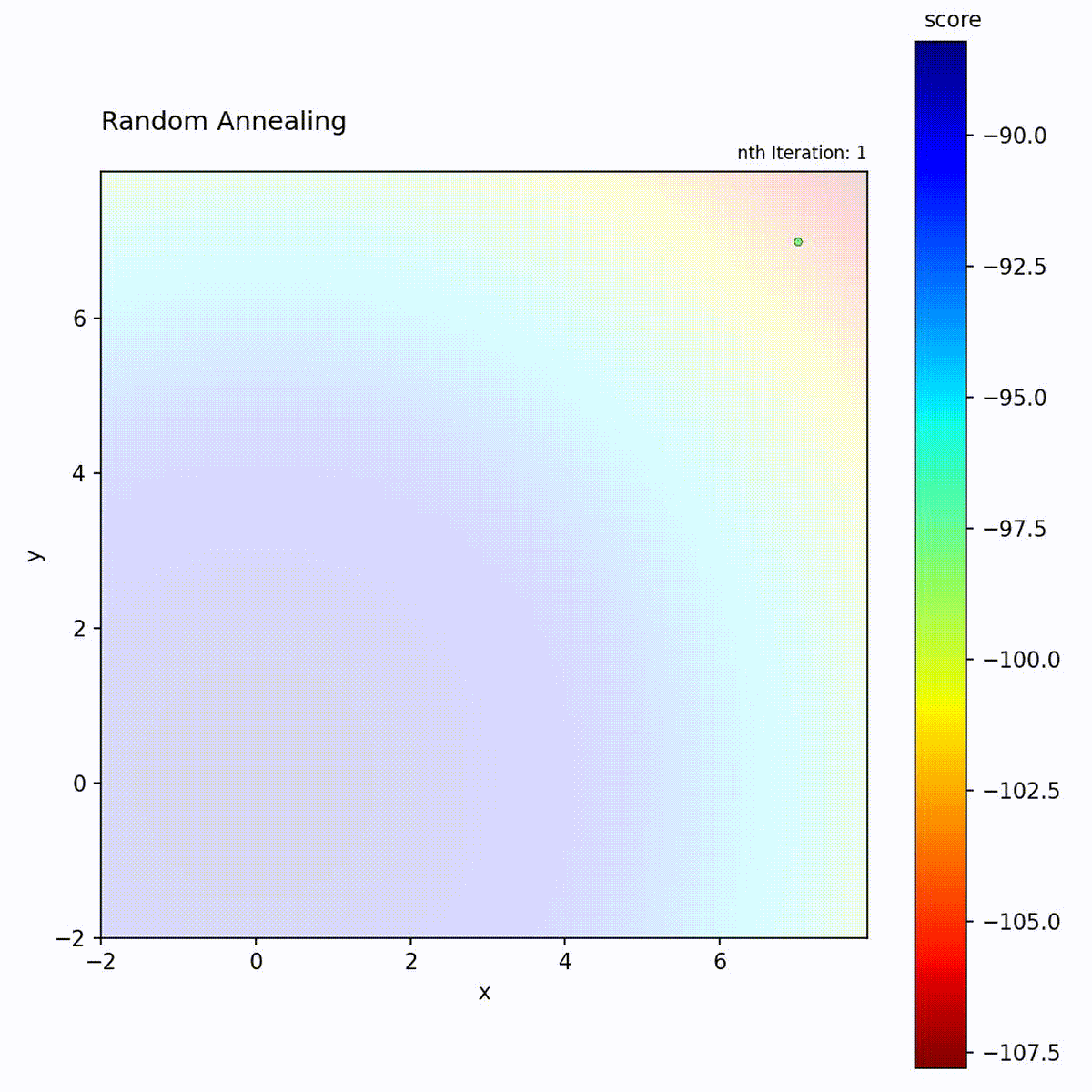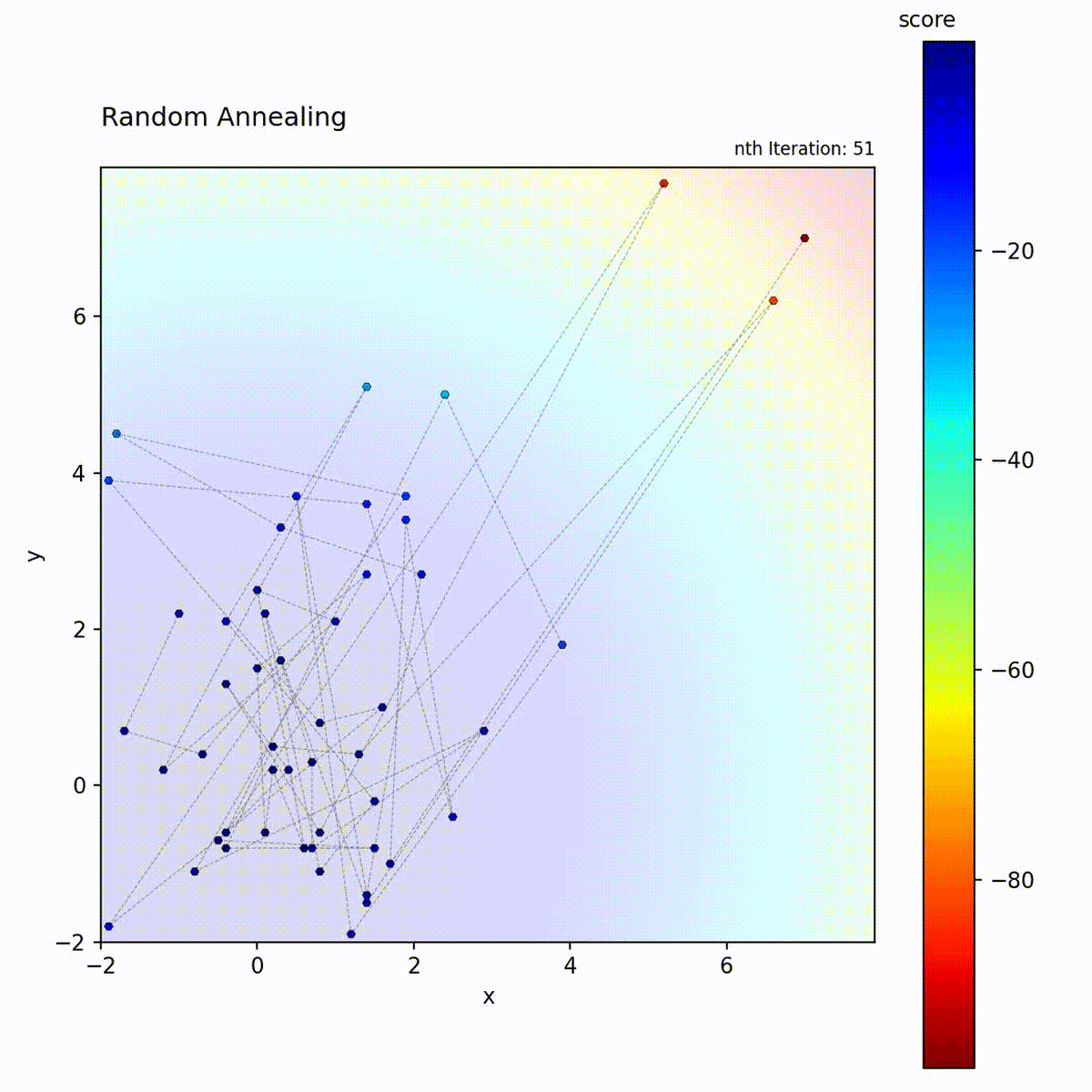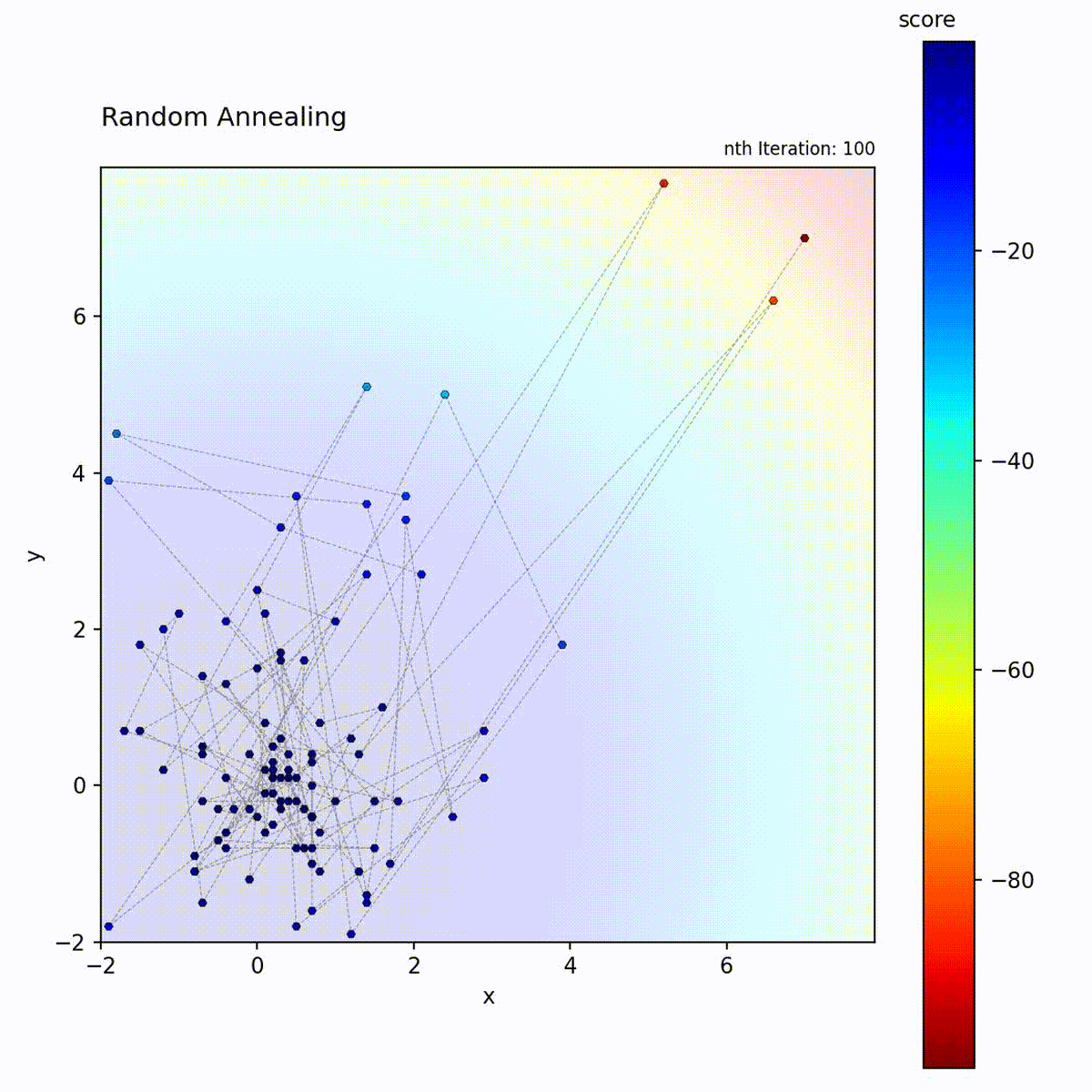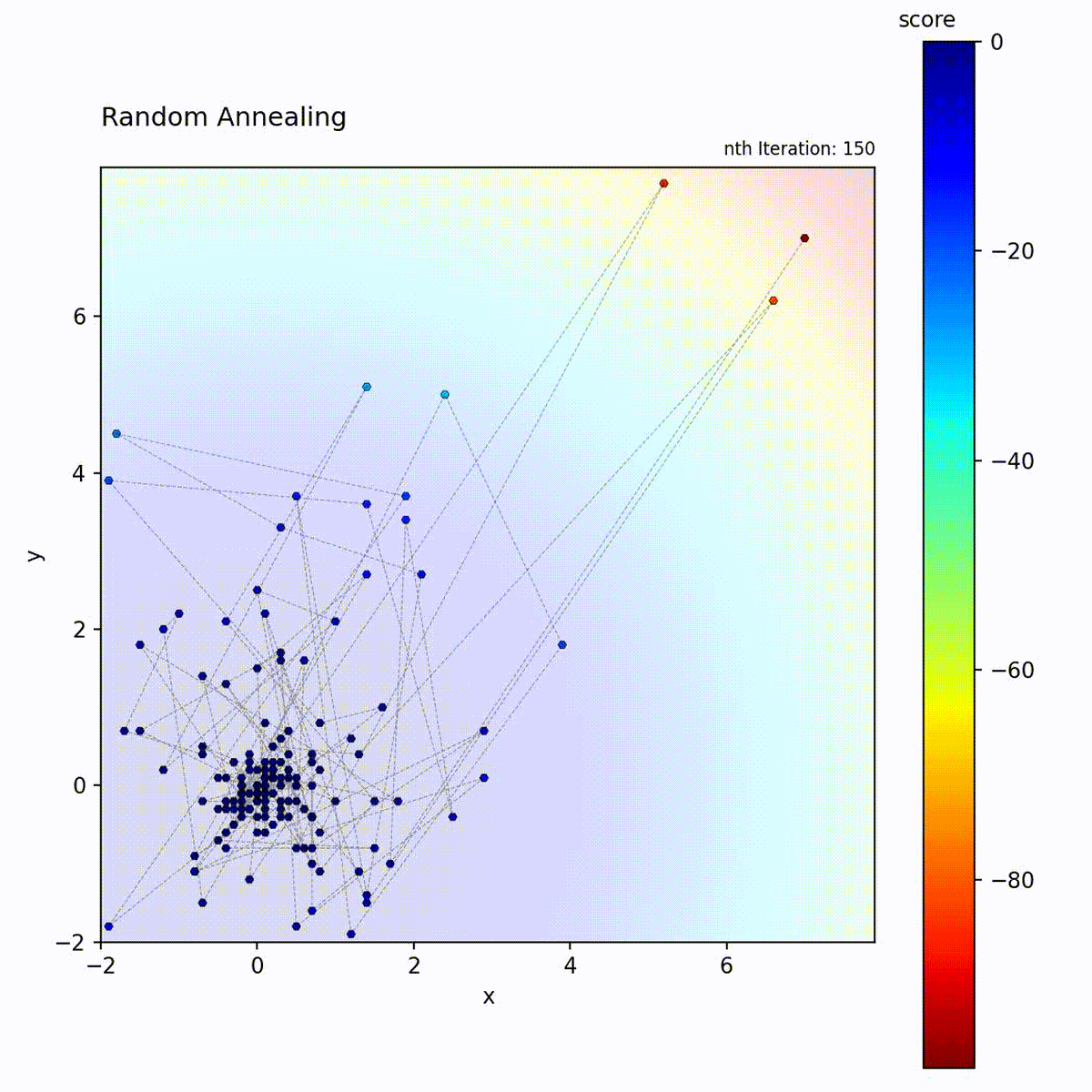
Convex function: Large initial steps quickly find the region, then small steps refine.
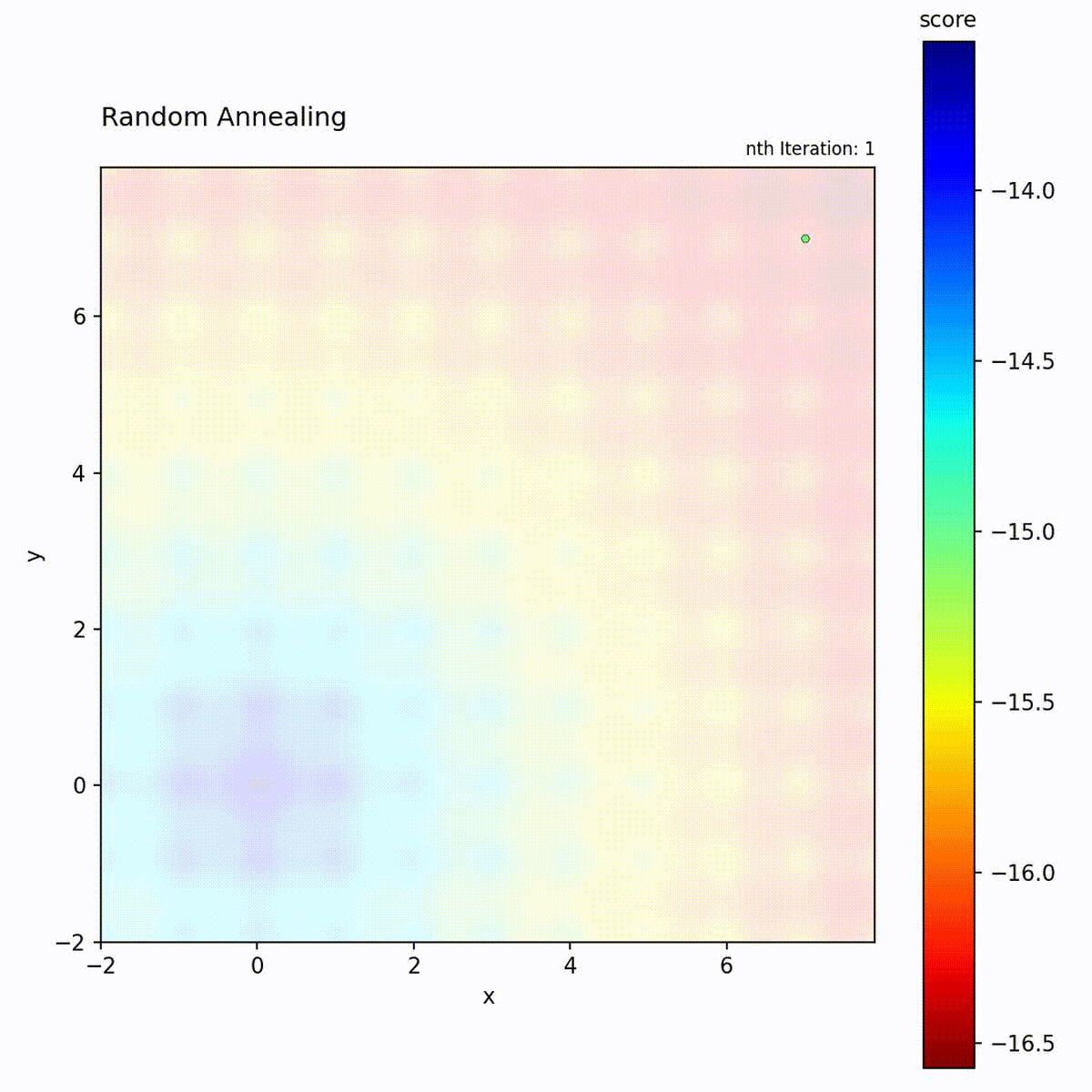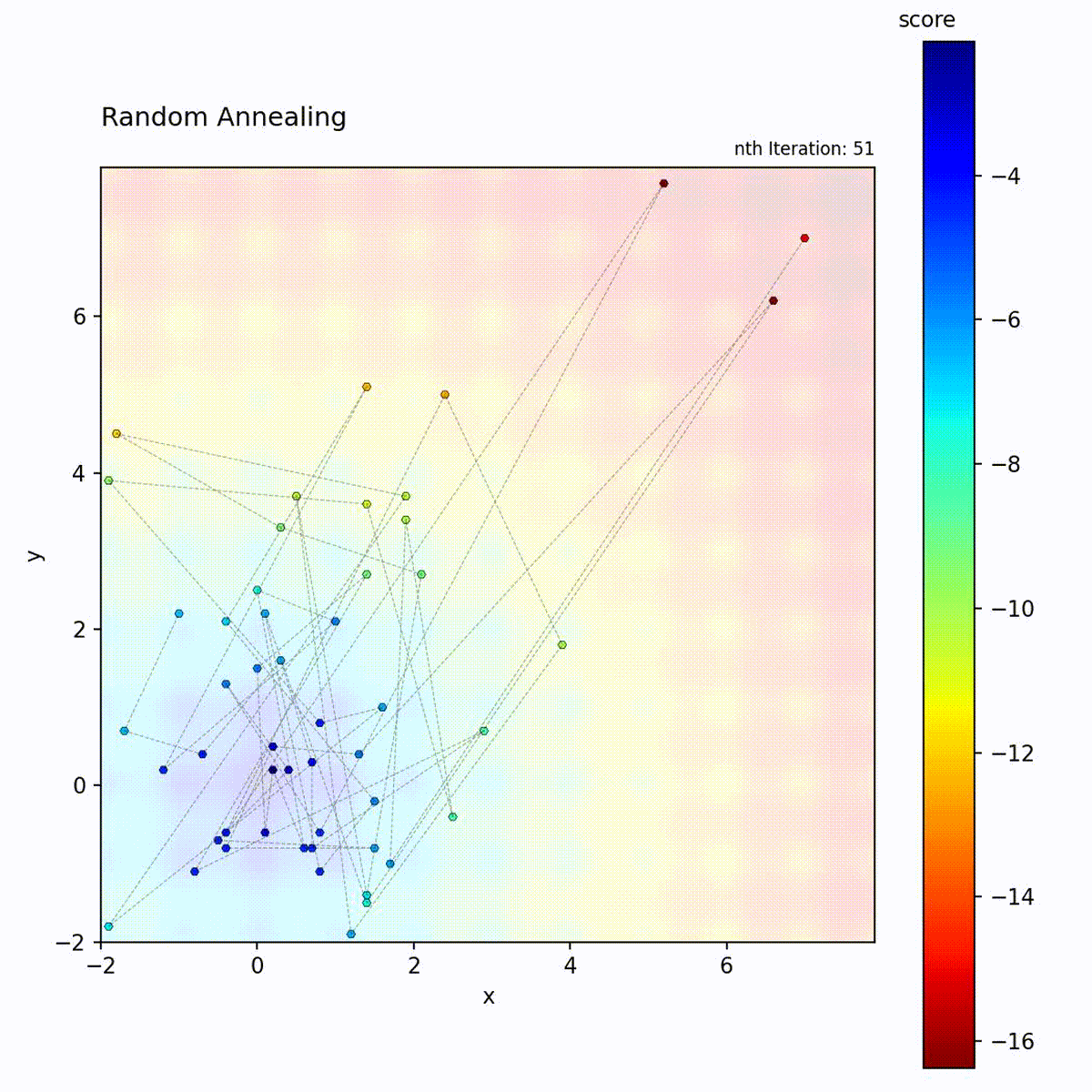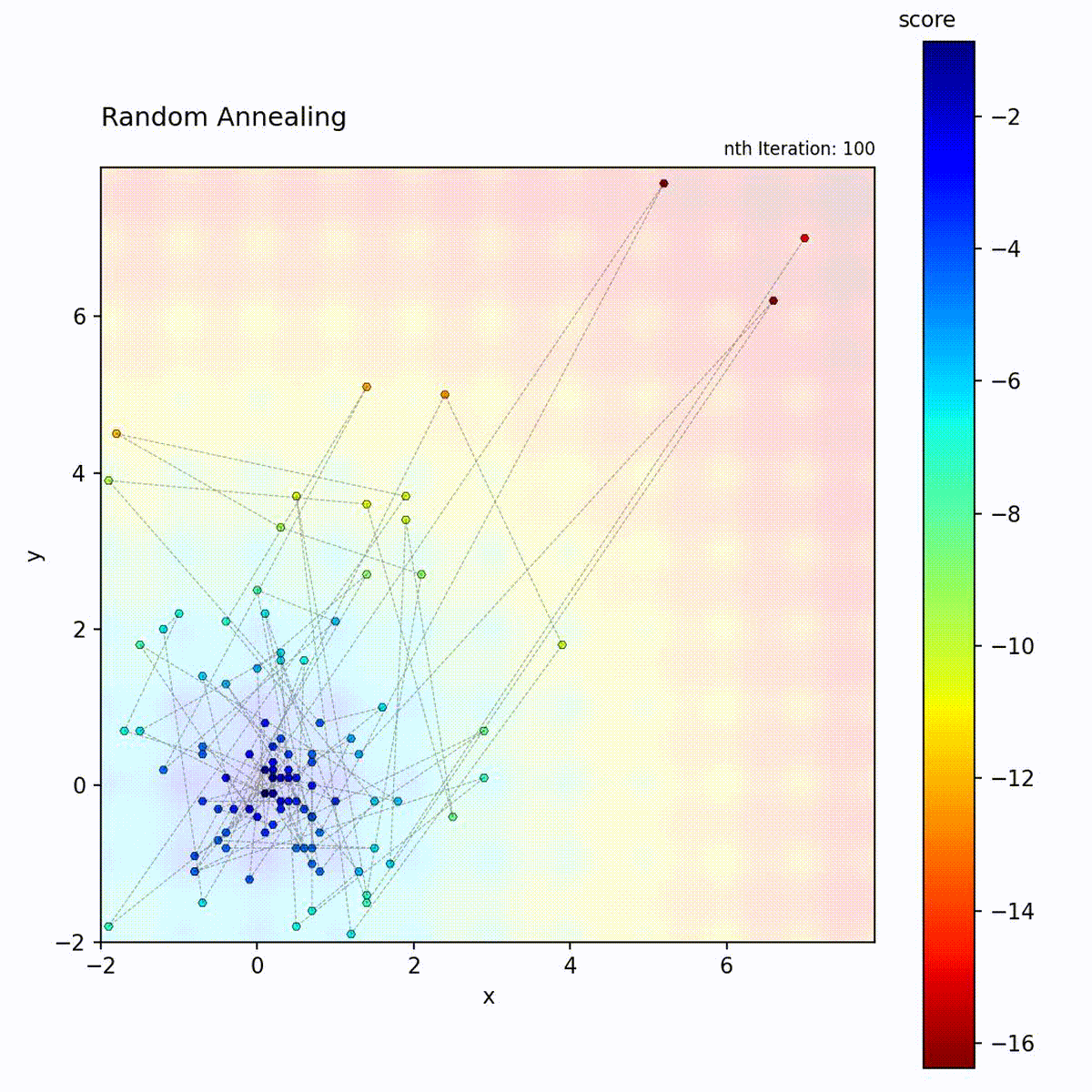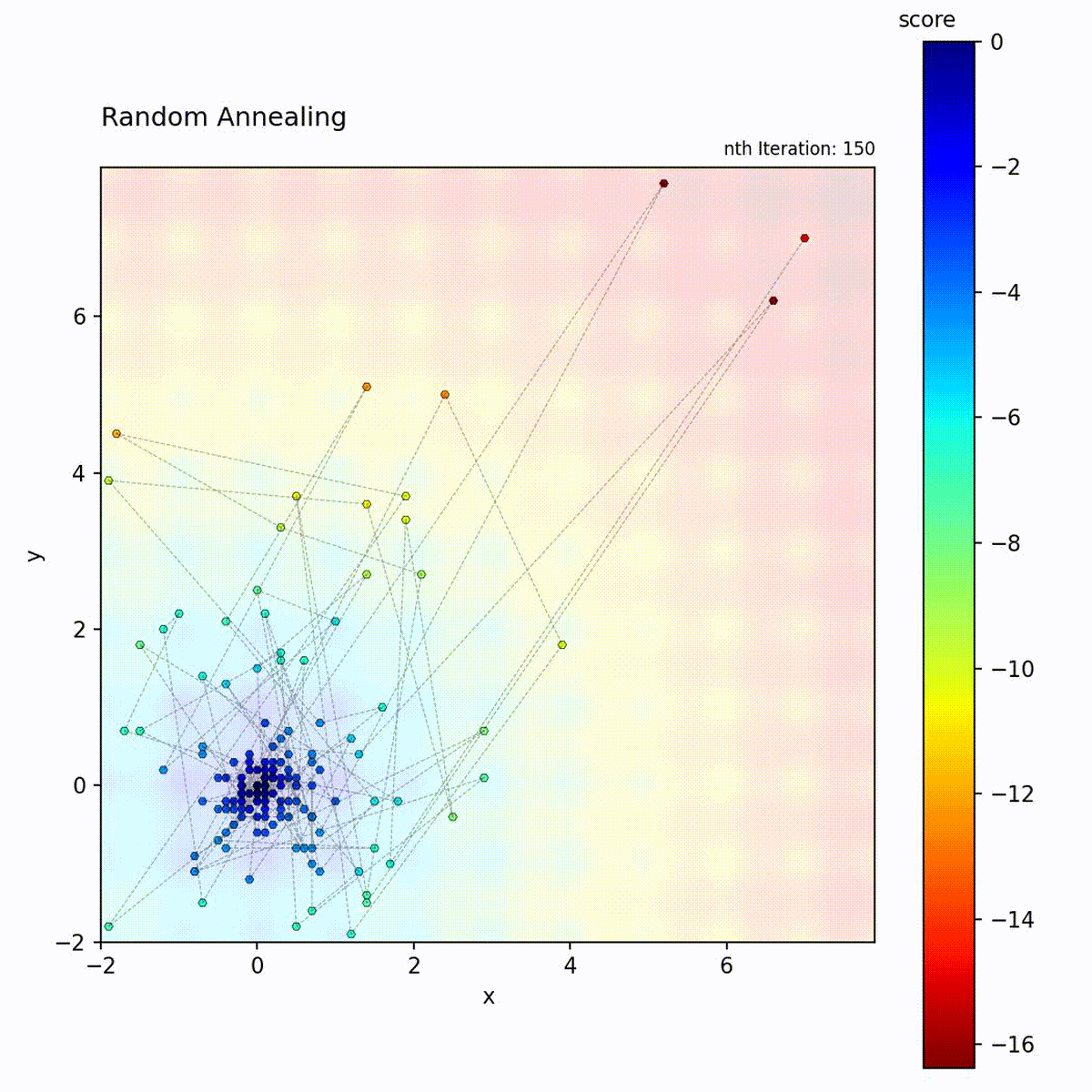
Multi-modal function: Broad early exploration followed by focused local search.
The key difference from Simulated Annealing is the source of the exploration-to-exploitation transition. Simulated Annealing maintains a fixed step size but reduces the probability of accepting worse moves over time. Random Annealing keeps strictly greedy acceptance but shrinks the search radius, which makes its behavior more predictable and eliminates uphill moves entirely. The trade-off is that the algorithm depends on the early large-step phase to locate the correct basin; once the step size has decayed, it cannot escape a suboptimal region. Choose Random Annealing over Simulated Annealing when deterministic greedy behavior is preferred, and over Random Restart Hill Climbing when a smooth transition is preferred over hard resets.
Algorithm
At each iteration:
Generate a neighbor with current step size
Move toward the neighbor if it’s better
Decrease the step size:
step = step * annealing_rate
Unlike Simulated Annealing which decreases the probability of accepting worse solutions, Random Annealing keeps greedy acceptance but shrinks the search radius.
Note
Random Annealing never accepts worse solutions (it’s always greedy). Instead, it controls exploration through step size decay. This makes it more predictable than SA: early iterations explore broadly because steps are large, late iterations exploit because steps are small. The result is similar to SA but without the stochastic acceptance.
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
float |
0.98 |
Step size decay rate per iteration |
|
float |
10.0 |
Initial step size multiplier |
|
float |
0.03 |
Base step size (multiplied by temp) |
Temperature Schedule
The effective step size at iteration t:
step_size(t) = epsilon * start_temp * annealing_rate^t
Example with epsilon=0.03, start_temp=10, annealing_rate=0.98:
- Iteration 0: step = 0.30 (30% of search space)
- Iteration 50: step = 0.11
- Iteration 100: step = 0.04
- Iteration 200: step = 0.01
Example
import numpy as np
from gradient_free_optimizers import RandomAnnealingOptimizer
def objective(para):
return -(para["x"]**2 + para["y"]**2)
search_space = {
"x": np.linspace(-10, 10, 100),
"y": np.linspace(-10, 10, 100),
}
opt = RandomAnnealingOptimizer(
search_space,
annealing_rate=0.97,
start_temp=15.0,
)
opt.search(objective, n_iter=500)
print(f"Best: {opt.best_para}, Score: {opt.best_score}")
When to Use
Good for:
Unknown landscapes requiring initial exploration
When you want exploration-to-exploitation without accepting bad moves
Problems where step size adaptation is more intuitive
Compared to Simulated Annealing:
Random Annealing: Shrinks search radius, never accepts worse
Simulated Annealing: Constant radius, decreasing bad acceptance
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import RandomAnnealingOptimizer
def levy_3d(para):
import math
vals = [para["x"], para["y"], para["z"]]
w = [1 + (v - 1) / 4 for v in vals]
term1 = np.sin(math.pi * w[0])**2
term_sum = sum(
(wi - 1)**2 * (1 + 10 * np.sin(math.pi * wi + 1)**2)
for wi in w[:-1]
)
term_last = (w[-1] - 1)**2 * (1 + np.sin(2 * math.pi * w[-1])**2)
return -(term1 + term_sum + term_last)
search_space = {
"x": np.linspace(-10, 10, 200),
"y": np.linspace(-10, 10, 200),
"z": np.linspace(-10, 10, 200),
}
opt = RandomAnnealingOptimizer(
search_space,
annealing_rate=0.99,
start_temp=20.0,
)
opt.search(levy_3d, n_iter=2000)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Automatically transitions from exploration to exploitation via step size decay. No stochastic acceptance means more predictable behavior than SA.
Computational overhead: Minimal (same as Hill Climbing).
Parameter sensitivity:
start_tempandannealing_ratejointly determine the exploration schedule. Too fast a decay narrows the search prematurely.