Hill Climbing
Hill Climbing is a greedy local search algorithm that iteratively moves to the
best neighboring solution. In each iteration, it generates a set of candidate
positions within a fixed step size (epsilon) of the current position,
evaluates them, and moves to the candidate with the highest score. If no
candidate improves upon the current score, the position remains unchanged. The
algorithm terminates or stagnates when no improving neighbor can be found,
meaning it has reached a local optimum.
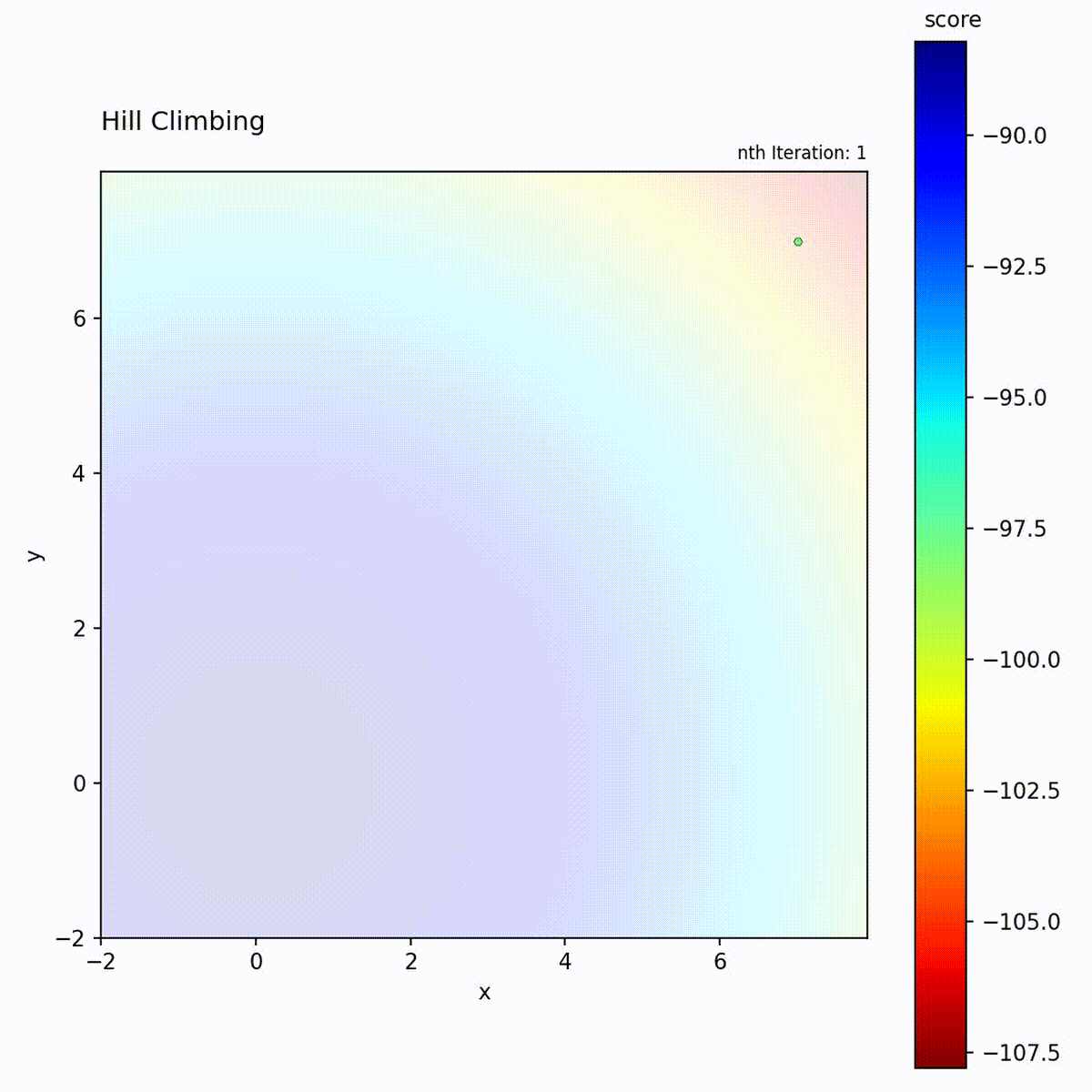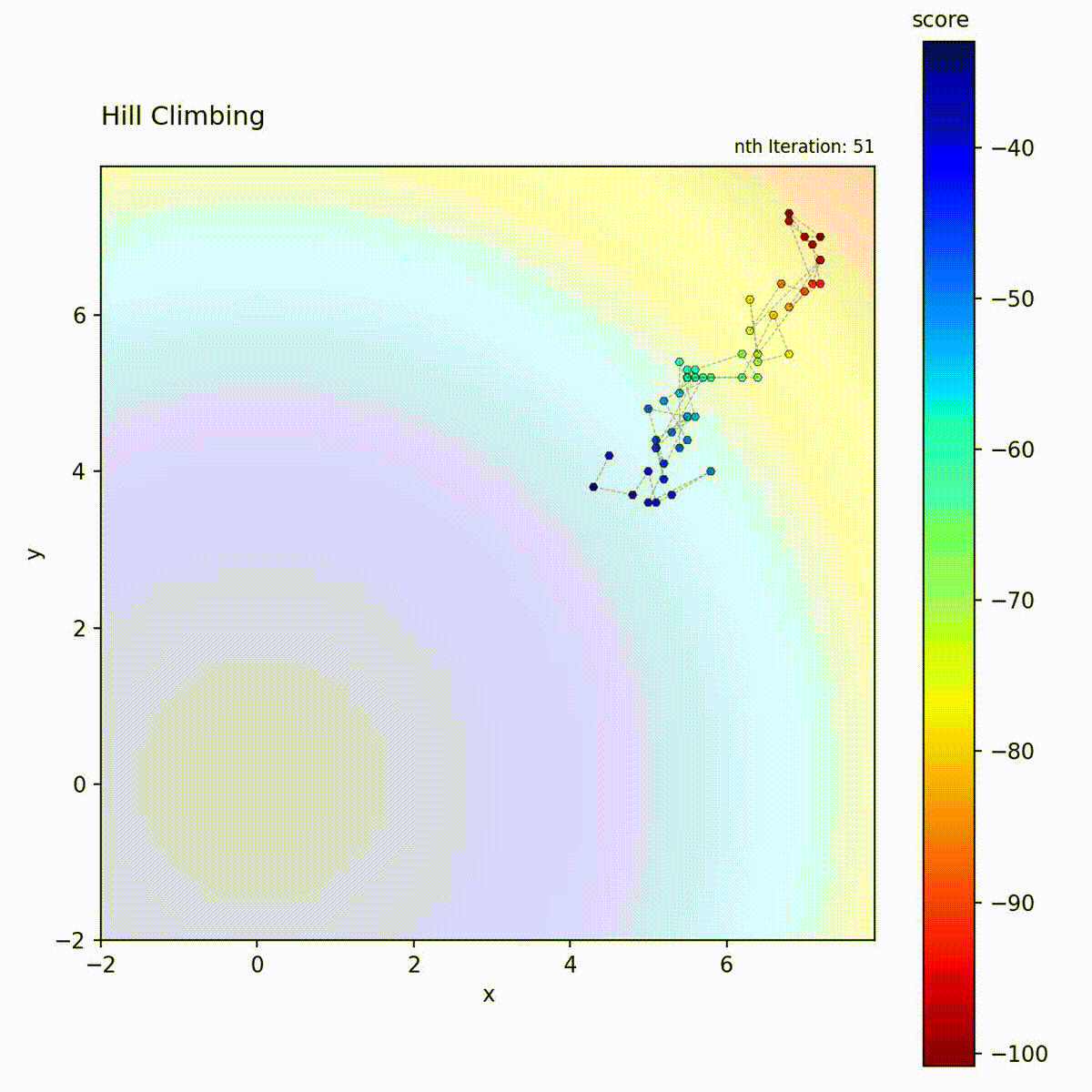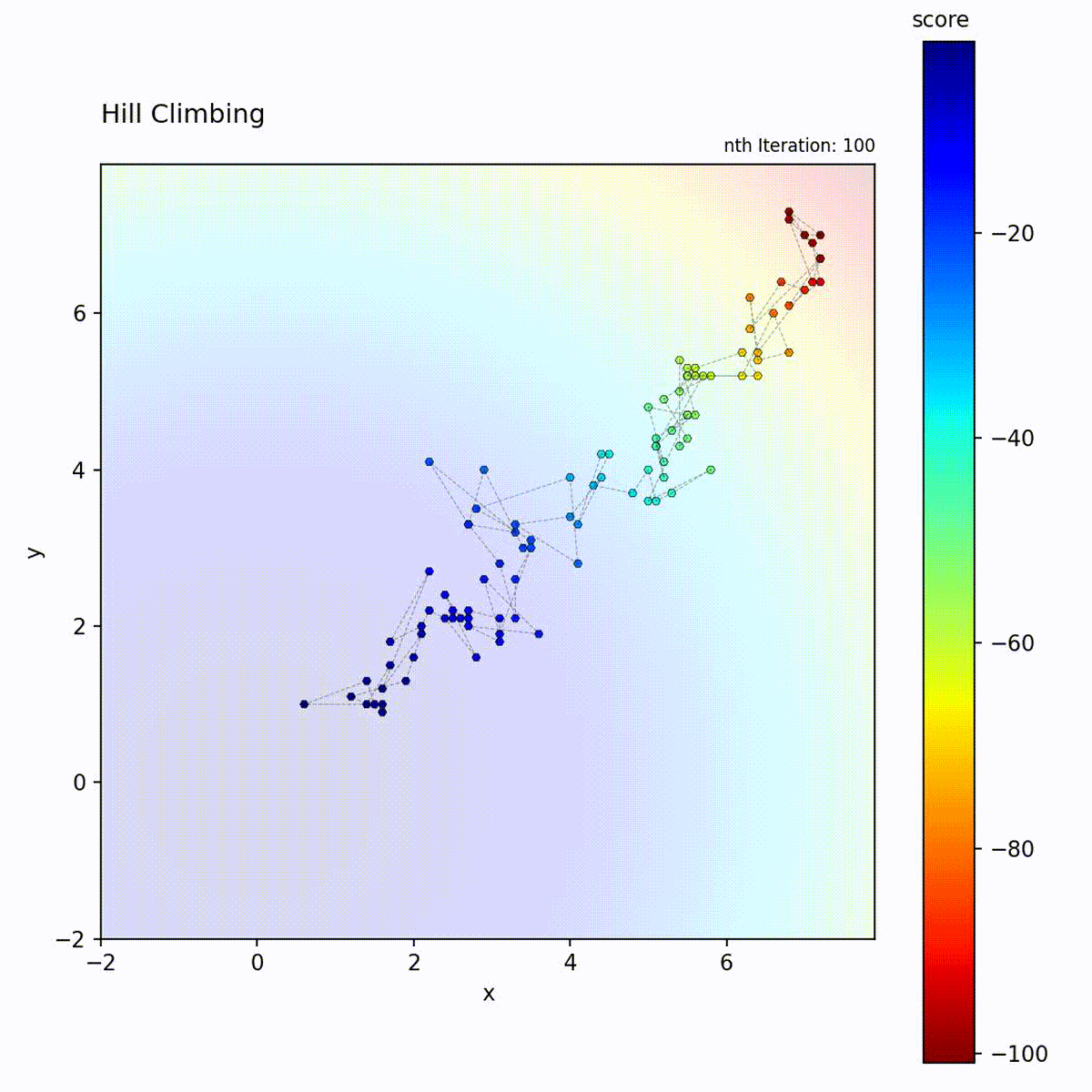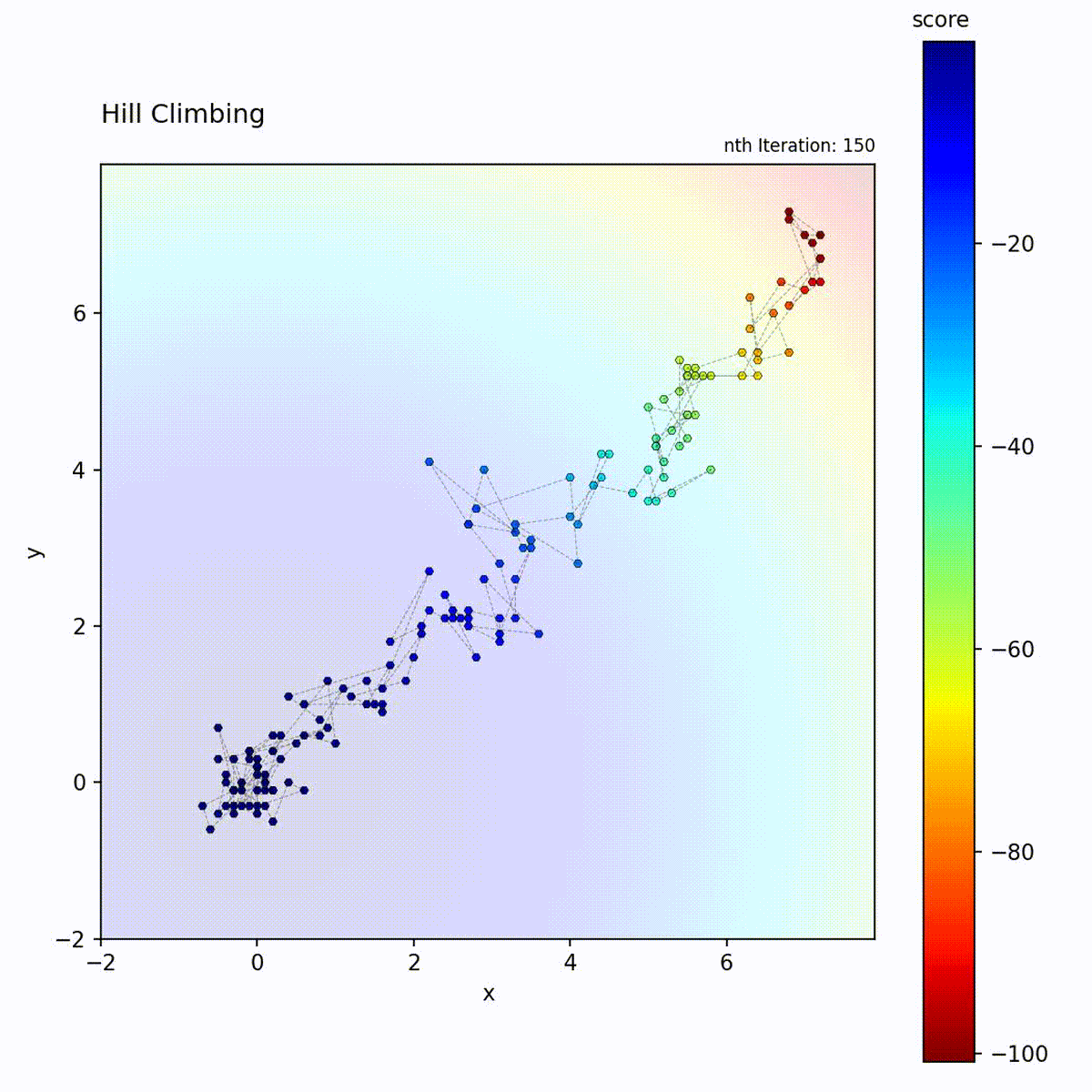
Convex function (Sphere): Converges quickly and reliably to the global optimum.
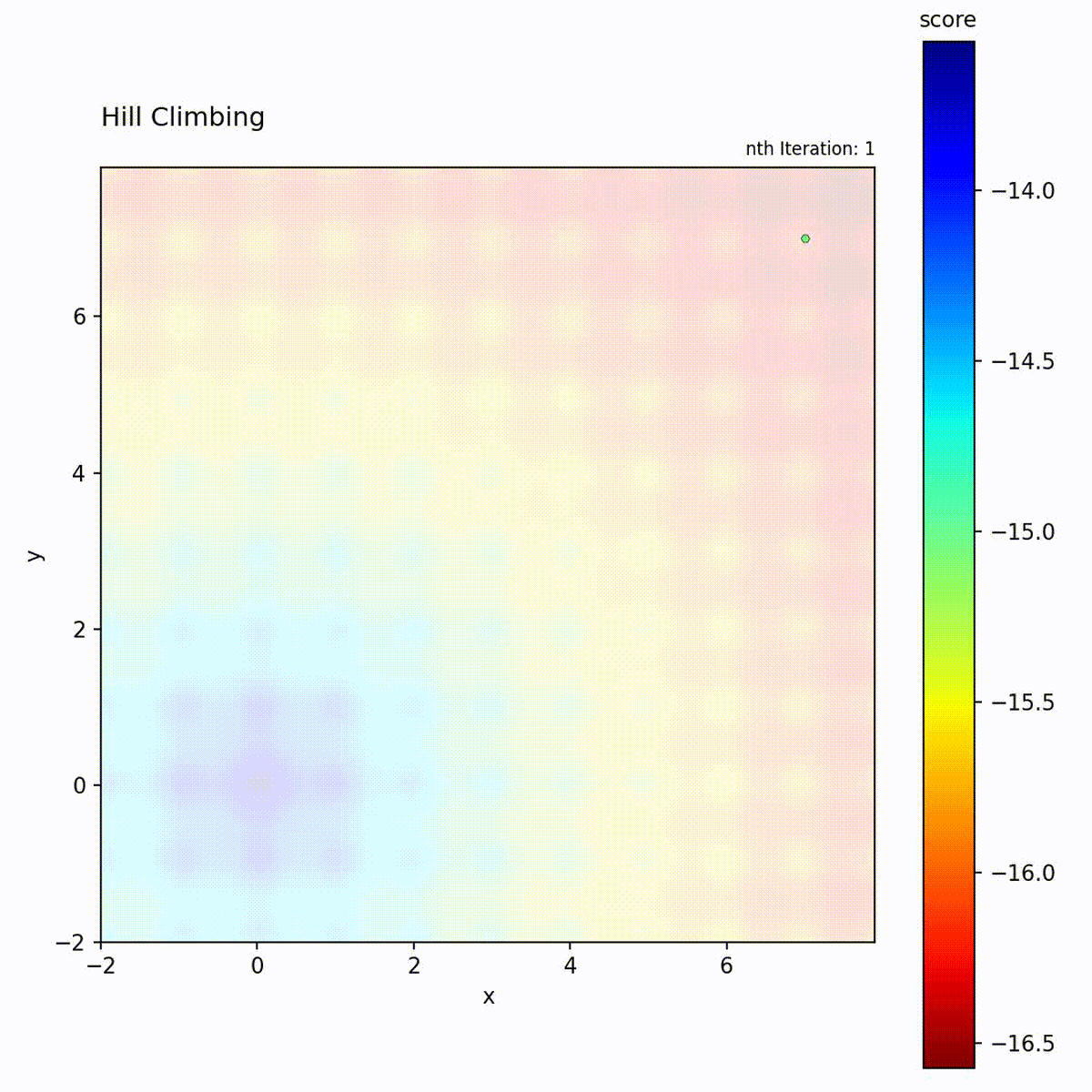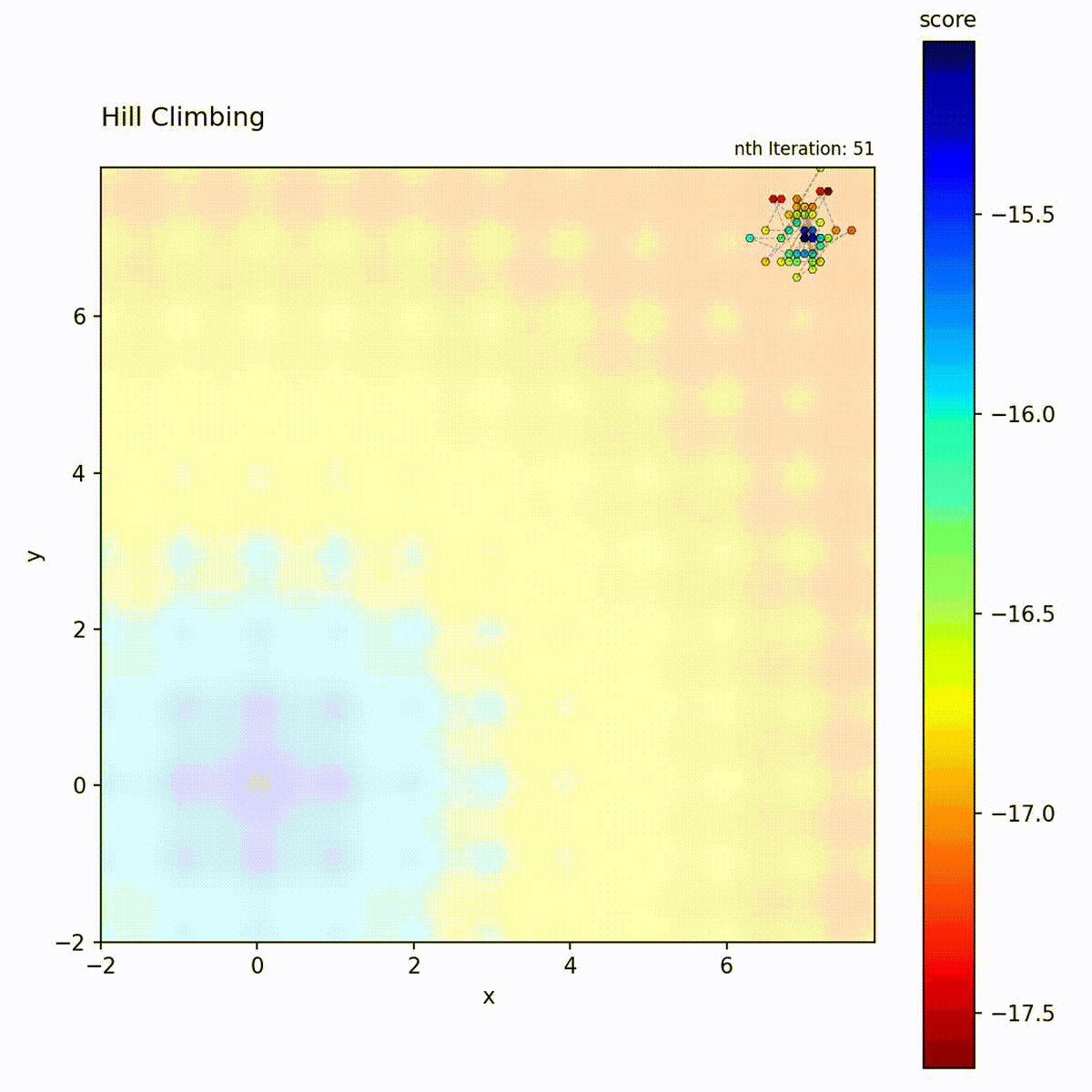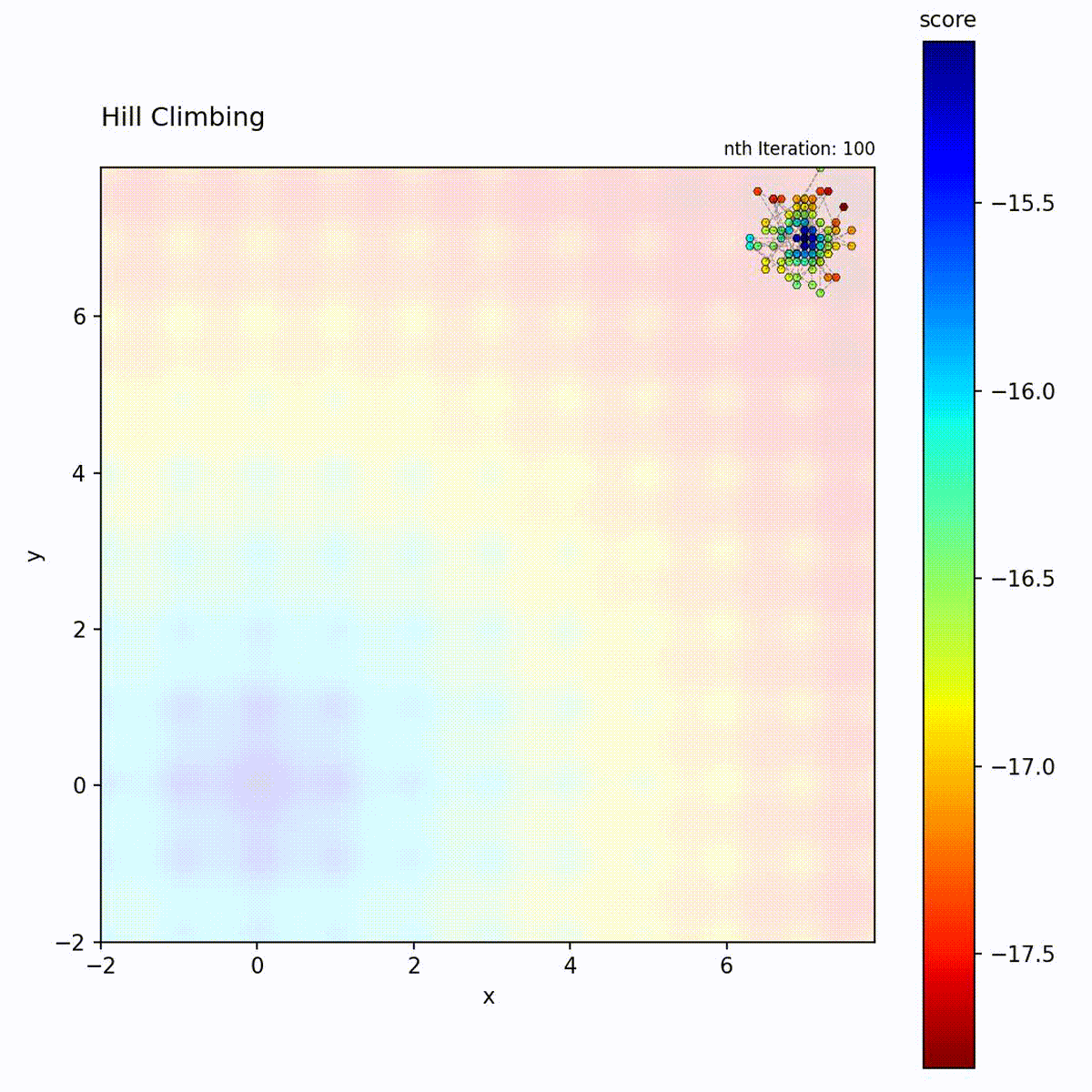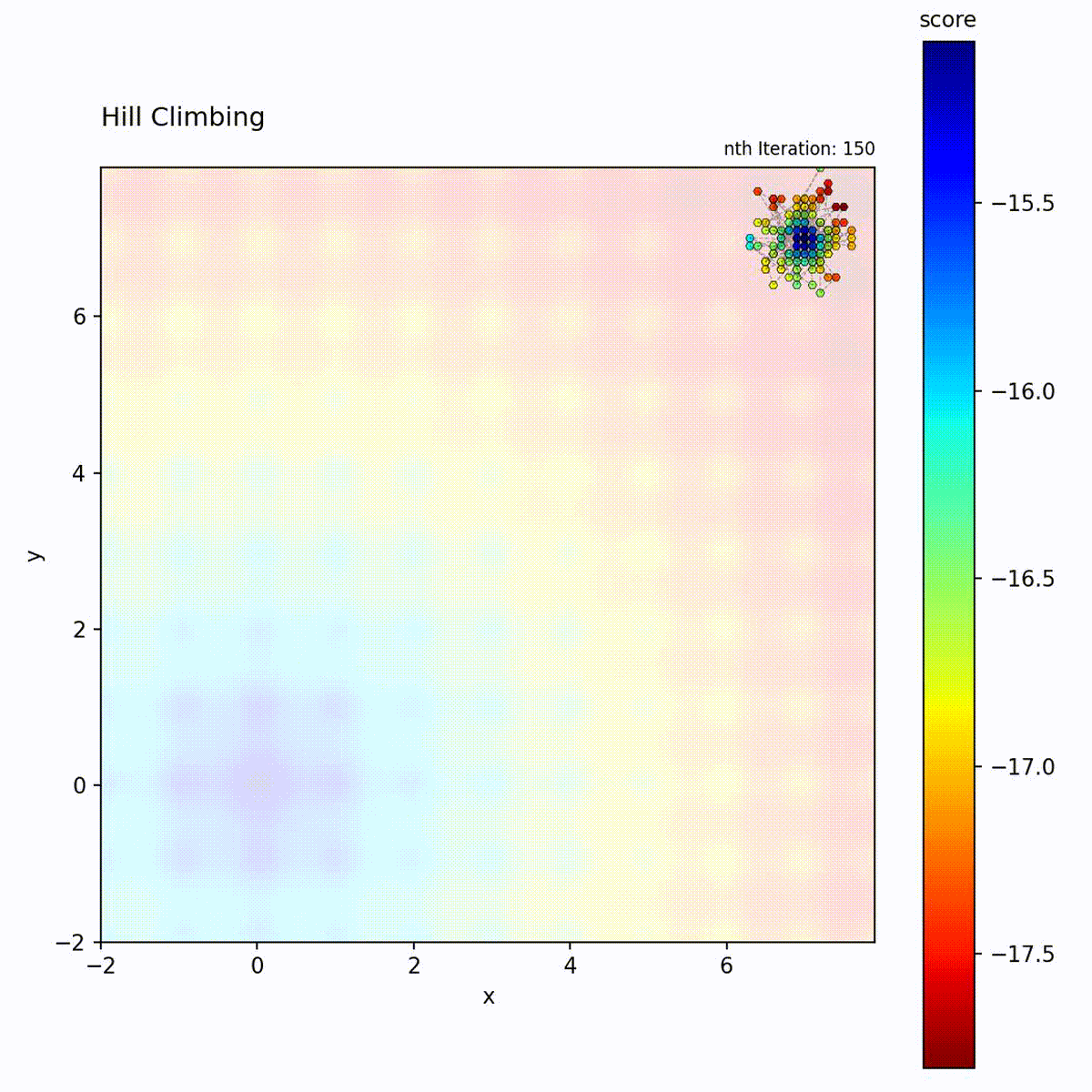
Multi-modal function (Ackley): May get stuck in local optima depending on starting point.
Hill Climbing serves as the base algorithm for the other local search optimizers
in this library. Stochastic Hill Climbing, Repulsing Hill Climbing, and Simulated
Annealing each extend it by adding a mechanism to escape local optima, which
standard Hill Climbing lacks. Choose Hill Climbing when the objective function is
unimodal or when you need to refine a solution that is already near the optimum.
Its per-iteration cost is limited to evaluating n_neighbours candidates,
making it the lowest-overhead option among the local search methods.
Algorithm
At each iteration:
Generate
n_neighboursrandom neighbors withinepsilondistanceEvaluate all neighbors
Move to the best neighbor if it improves the current score
If no improvement, stay in place (may try different neighbors)
neighbor = current_pos + epsilon * range(dim) * sample(distribution)
if score(neighbor) > score(current_pos):
current_pos = neighbor
Note
Hill Climbing is a greedy algorithm. It always moves toward improvement and never accepts worse solutions. This makes it the fastest local search method but also the most vulnerable to local optima. Its simplicity makes it an ideal building block: most other local search algorithms are modifications of Hill Climbing that add escape mechanisms.

The Hill Climbing loop: generate neighbors, evaluate, and move only if an improvement is found.
When to Use
Good for:
Smooth, unimodal functions
Fine-tuning from a good starting point
Fast convergence when the landscape is well-behaved
Initial exploration before switching to other algorithms
Not ideal for:
Functions with many local optima
Flat regions (plateaus)
Unknown landscapes without prior information
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
dict |
required |
Dictionary mapping parameter names to search-space definitions |
|
dict |
{“grid”: 4, “random”: 2, “vertices”: 4} |
Initialization strategy |
|
list |
[] |
List of constraint functions |
|
int |
None |
Random seed for reproducibility |
|
float |
0.0 |
Probability of random restart per iteration |
|
float |
0.03 |
Step size as fraction of search space range |
|
str |
“normal” |
Step distribution: “normal”, “laplace”, or “logistic” |
|
int |
3 |
Number of neighbors to evaluate per iteration |
Example
import numpy as np
from gradient_free_optimizers import HillClimbingOptimizer
def sphere(para):
return -(para["x"]**2 + para["y"]**2)
search_space = {
"x": np.linspace(-10, 10, 100),
"y": np.linspace(-10, 10, 100),
}
opt = HillClimbingOptimizer(
search_space,
epsilon=0.05, # Slightly larger steps
n_neighbours=5, # Evaluate more neighbors
)
opt.search(sphere, n_iter=500)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Tuning Tips
Step Size (epsilon)
Larger epsilon: Faster convergence, may overshoot optimum
Smaller epsilon: Precise convergence, slower exploration
# Start broad, then fine-tune
opt1 = HillClimbingOptimizer(search_space, epsilon=0.1)
opt1.search(objective, n_iter=100)
opt2 = HillClimbingOptimizer(
search_space,
epsilon=0.01,
initialize={"warm_start": [opt1.best_para]}
)
opt2.search(objective, n_iter=100)
Number of Neighbors
More neighbors: Better chance of finding improvements, more evaluations
Fewer neighbors: Faster iterations, may miss good directions
Adding Randomness
Use rand_rest_p to occasionally jump to random positions:
opt = HillClimbingOptimizer(
search_space,
rand_rest_p=0.1, # 10% chance of random jump per iteration
)
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import HillClimbingOptimizer
def styblinski_tang_4d(para):
vals = [para["x0"], para["x1"], para["x2"], para["x3"]]
return -sum(v**4 - 16 * v**2 + 5 * v for v in vals) / 2
search_space = {
"x0": np.linspace(-5, 5, 100),
"x1": np.linspace(-5, 5, 100),
"x2": np.linspace(-5, 5, 100),
"x3": np.linspace(-5, 5, 100),
}
opt = HillClimbingOptimizer(
search_space,
epsilon=0.08,
n_neighbours=10,
distribution="logistic",
)
opt.search(styblinski_tang_4d, n_iter=2000)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Hill Climbing is purely exploitative. Increase
epsilonorn_neighboursfor broader search, but it will never intentionally explore distant regions.Computational overhead: Minimal. The only cost is evaluating
n_neighbourscandidates per iteration.Parameter sensitivity: Mostly controlled by
epsilon. Too small and convergence stalls; too large and it oscillates around the optimum.