Differential Evolution
Differential Evolution (DE) generates new candidate solutions by adding the weighted difference between two randomly selected population members to a third member. This produces a mutant vector whose step size and direction are derived from the current population distribution. The mutant is then mixed with the original target vector through a crossover operation, and the result replaces the target only if it achieves a better score. Because the difference vectors are computed from the population itself, the step sizes adapt automatically: they are large when the population is spread out and shrink as it converges.
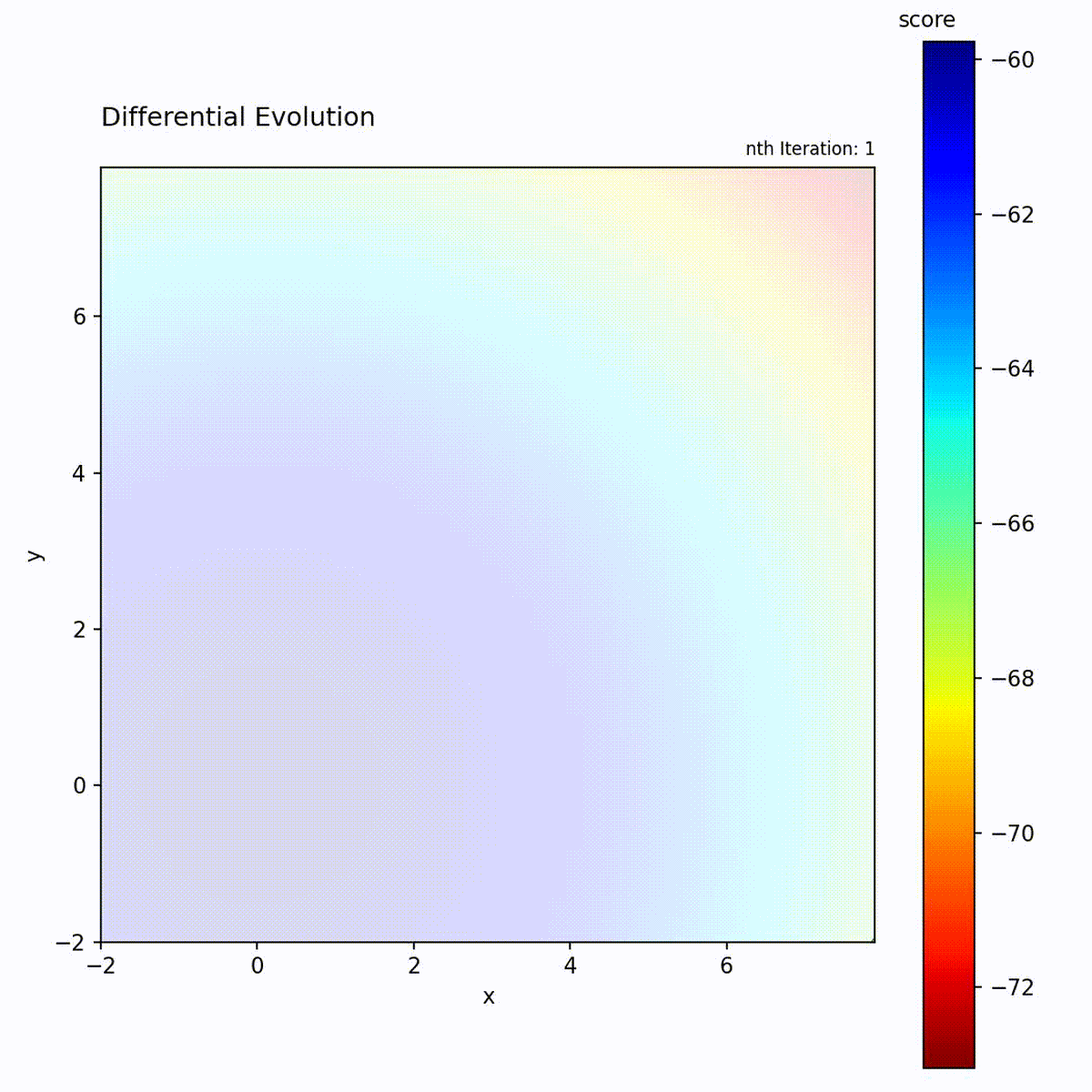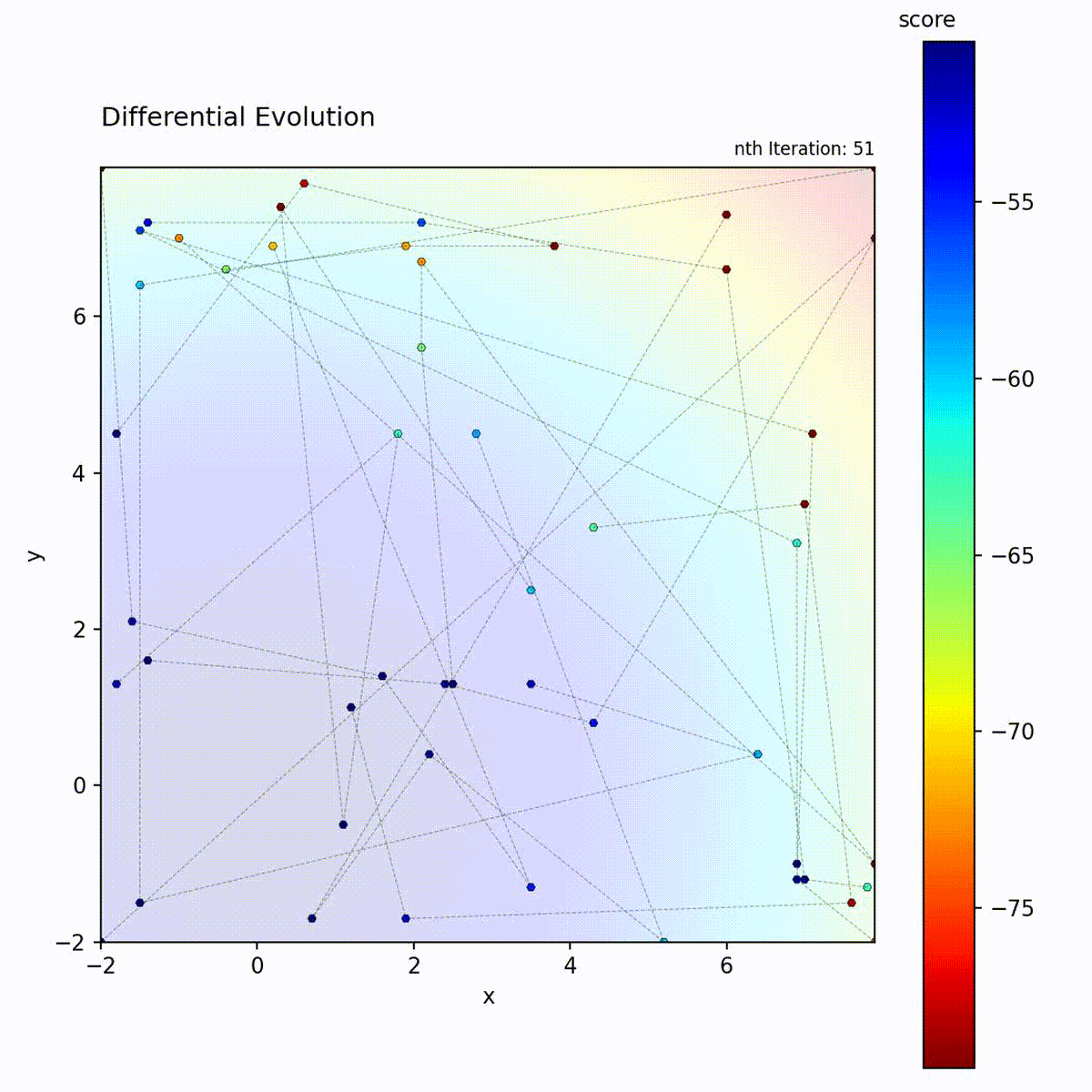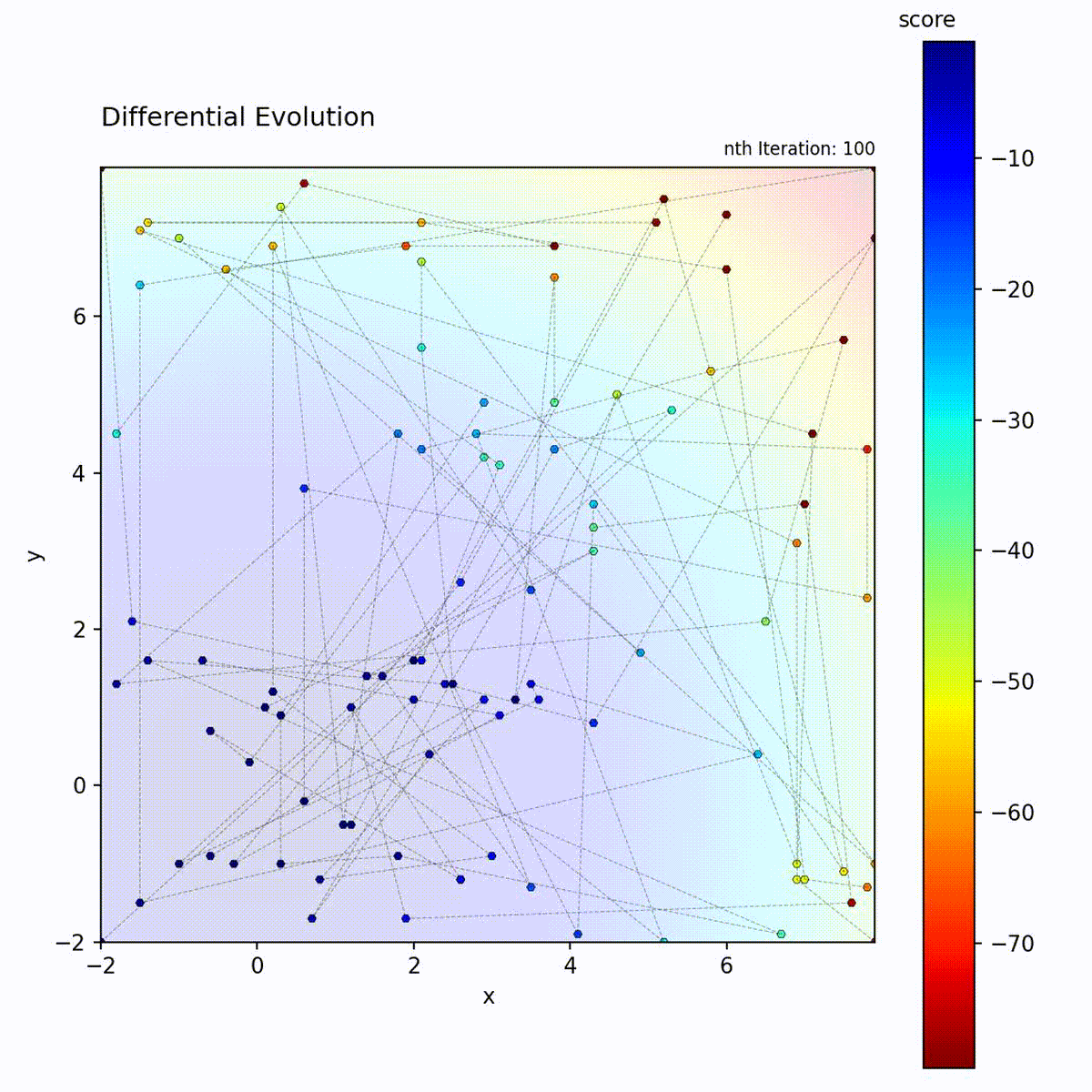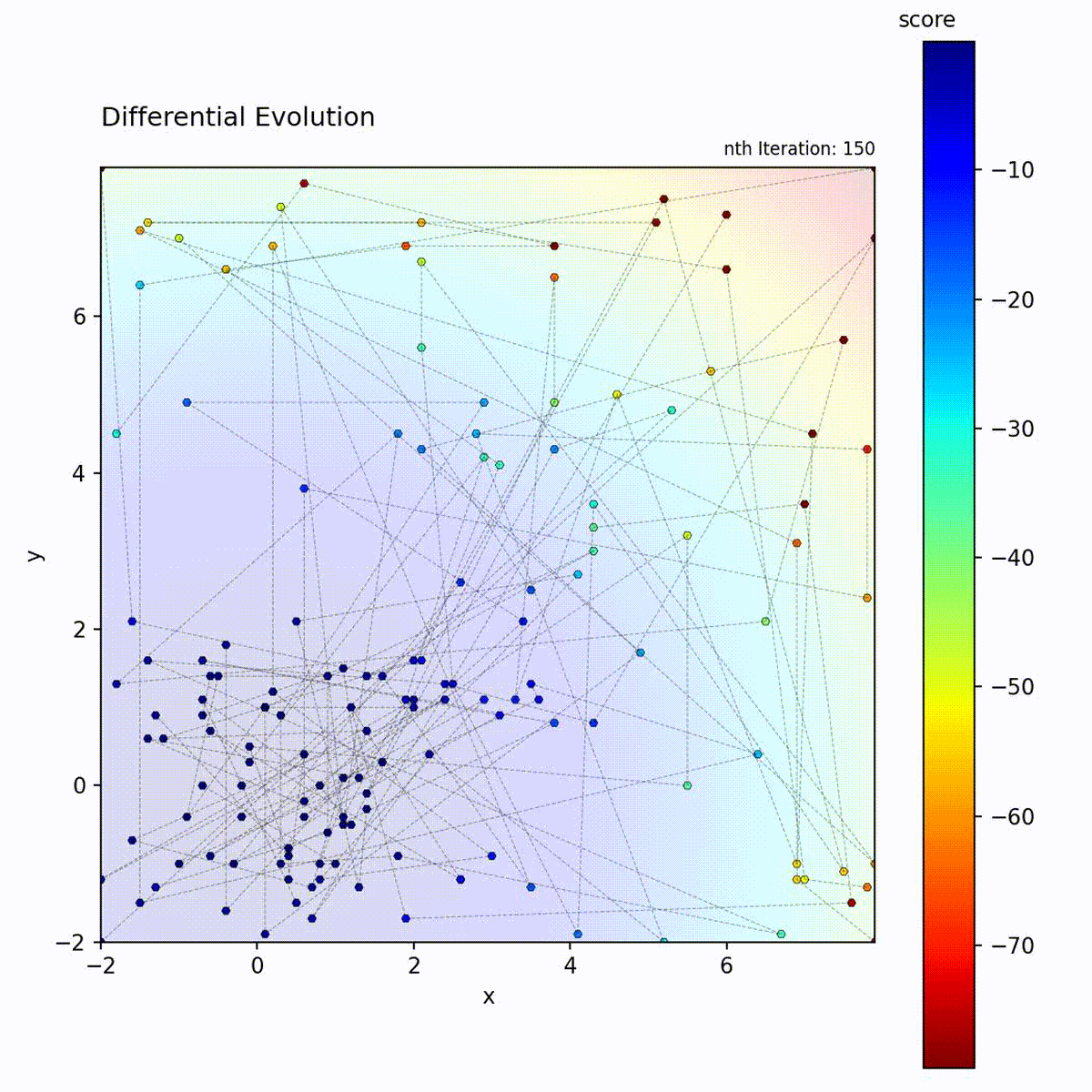
Convex function: Population quickly converges.
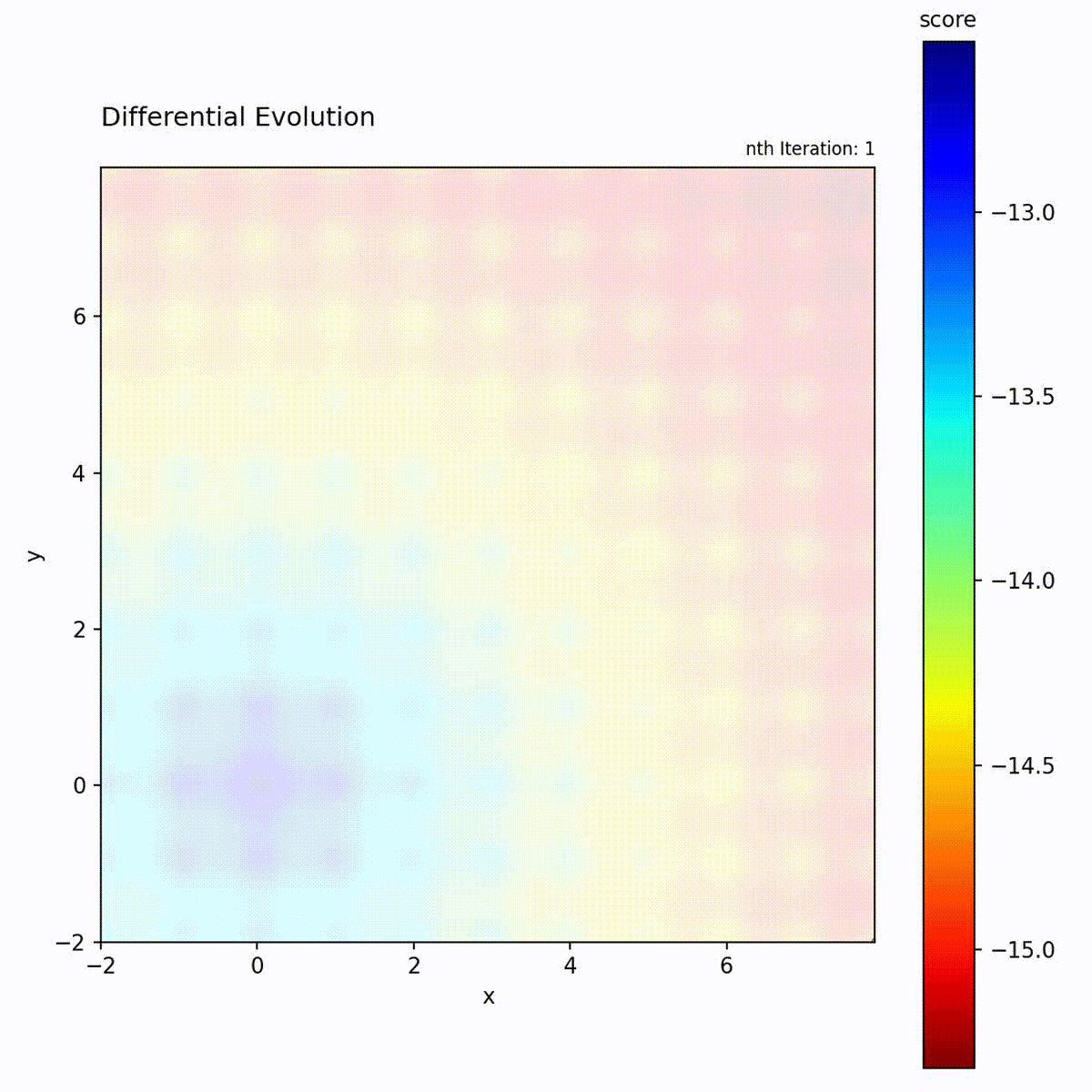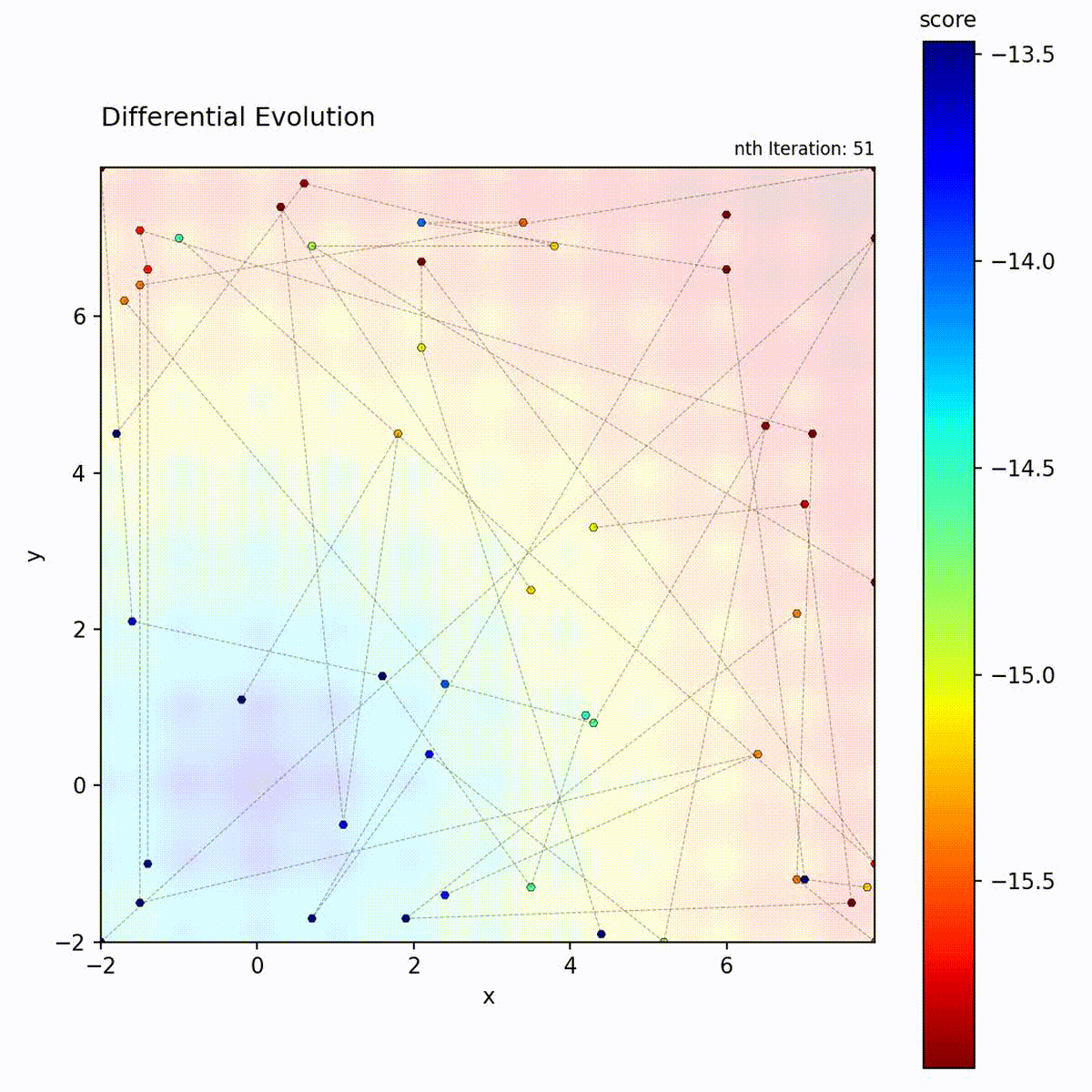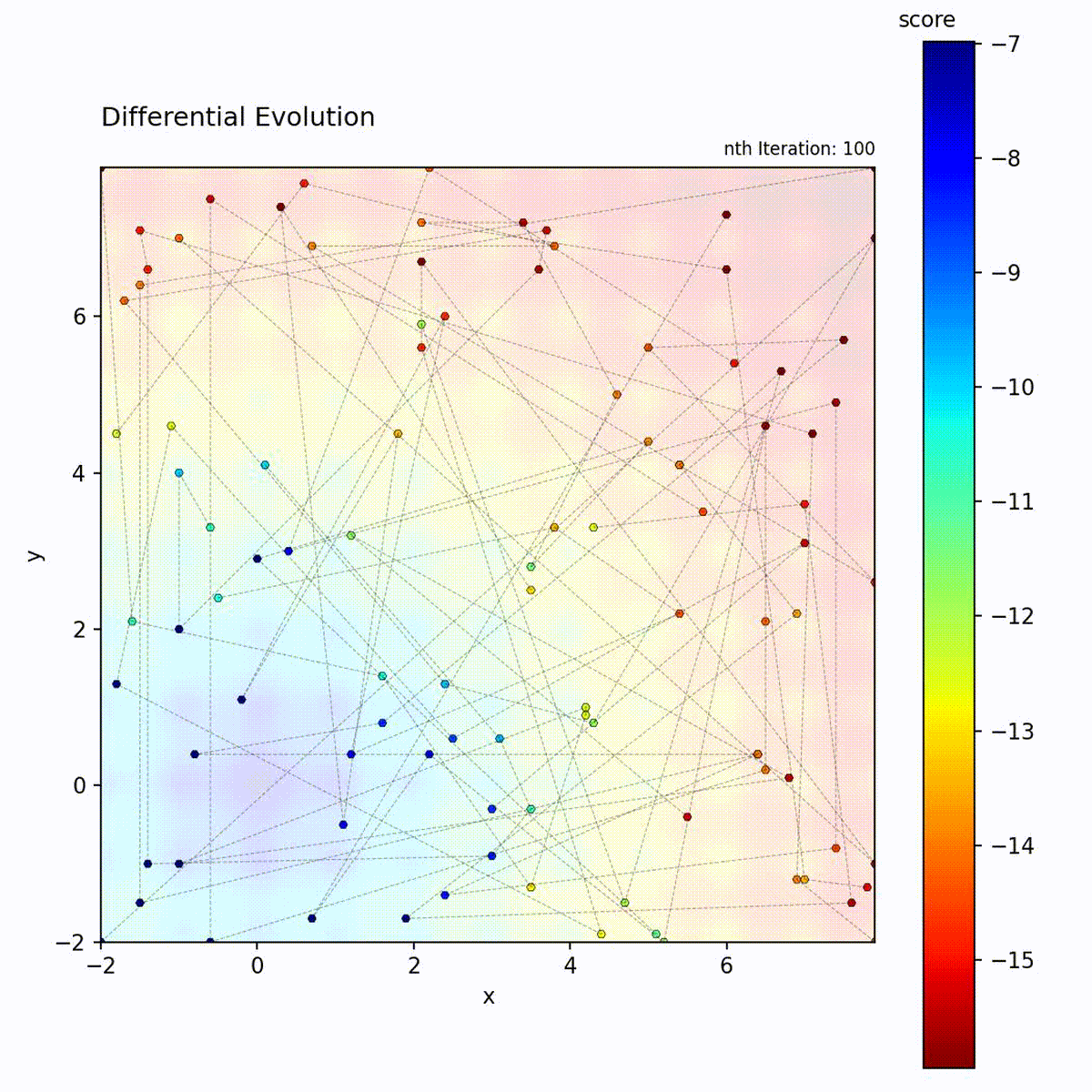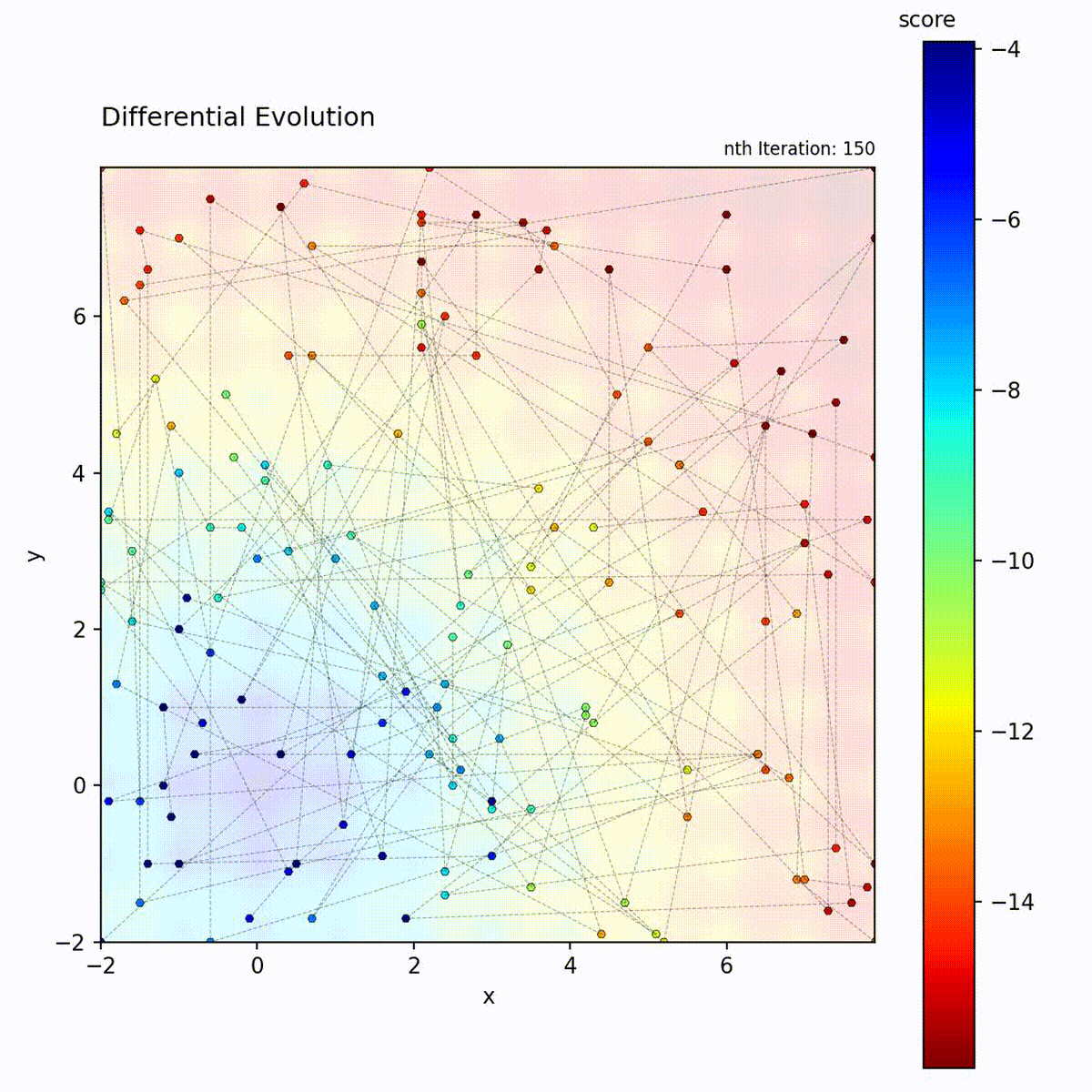
Multi-modal function: Difference vectors help escape local optima.
The self-adaptive step size is the key property that distinguishes DE from the other population-based optimizers in this library. PSO requires explicit velocity weights, ES requires a tuned mutation rate, and GA relies on a fixed crossover operator. DE derives both step direction and magnitude from the population, which makes it less sensitive to parameter settings. The default configuration (F=0.8, CR=0.9) works across a broad range of continuous problems without adjustment. DE is the preferred choice for real-valued optimization in this library when the problem has moderate to high dimensionality. It requires a minimum population size of 4 to form the necessary difference vectors.
Algorithm
For each target vector in the population:
Mutation: Create mutant vector from three random population members
mutant = x_r1 + F * (x_r2 - x_r3)
where F is the mutation factor (
mutation_rate)Crossover: Mix mutant with target vector
trial[i] = mutant[i] if random() < CR else target[i]
where CR is the crossover rate
Selection: Keep trial if better than target
The Key Insight
The difference vector (x_r2 - x_r3) automatically adapts:
Early in search: population is spread out, large differences
Late in search: population converges, small differences
This provides self-adaptive step sizes without explicit parameters.
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
int |
10 |
Population size |
|
float |
0.9 |
Mutation factor F (typically 0.5-1.0) |
|
float |
0.9 |
Crossover probability CR (typically 0.5-1.0) |
Tuning Tips
Mutation rate (F):
F = 0.5: Conservative mutations
F = 1.0: More aggressive exploration
F > 1.0: Very aggressive (may overshoot)
Crossover rate (CR):
Low CR (0.1-0.3): More of target preserved, slower mixing
High CR (0.7-1.0): More of mutant used, faster adaptation
Example
import numpy as np
from gradient_free_optimizers import DifferentialEvolutionOptimizer
def rosenbrock(para):
x, y = para["x"], para["y"]
return -((1 - x)**2 + 100 * (y - x**2)**2)
search_space = {
"x": np.linspace(-5, 5, 100),
"y": np.linspace(-5, 5, 100),
}
opt = DifferentialEvolutionOptimizer(
search_space,
population=20,
mutation_rate=0.8,
crossover_rate=0.9,
)
opt.search(rosenbrock, n_iter=300)
print(f"Best: {opt.best_para}, Score: {opt.best_score}")
When to Use
Good for:
Continuous, non-linear optimization
Functions with complex interactions
When you want self-adaptive step sizes
Real-parameter optimization
Not ideal for:
Pure discrete/categorical problems
Very small populations (needs at least 4 for basic DE)
Comparison with Other Methods
Algorithm |
Step Size |
Mechanism |
|---|---|---|
DE |
Self-adaptive (difference vectors) |
Mutation + crossover |
ES |
Mutation variance |
Mutation + selection |
PSO |
Velocity |
Attraction to bests |
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import DifferentialEvolutionOptimizer
def styblinski_tang_4d(para):
vals = [para[f"x{i}"] for i in range(4)]
return -sum(v**4 - 16 * v**2 + 5 * v for v in vals) / 2
search_space = {
f"x{i}": np.linspace(-5, 5, 200)
for i in range(4)
}
opt = DifferentialEvolutionOptimizer(
search_space,
population=25,
mutation_rate=0.7,
crossover_rate=0.9,
)
opt.search(styblinski_tang_4d, n_iter=500)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Self-adaptive through difference vectors.
mutation_rate(F) andcrossover_rate(CR) provide additional control.Computational overhead: Low per individual. Population must be at least 4 to form the required difference vectors.
Parameter sensitivity: The standard settings (F=0.8, CR=0.9) work surprisingly well across a wide range of problems. Population size matters more than the rates.