Lipschitz Optimizer
The Lipschitz Optimizer exploits the Lipschitz continuity condition,
|f(x) - f(y)| <= L * ||x - y||, to compute upper bounds on the objective
value at unevaluated points. Given a set of already-evaluated positions, the
algorithm estimates the Lipschitz constant L and uses it to derive an upper
envelope over the search space. It then selects the candidate point with the
highest upper bound for the next evaluation. Regions where the upper bound falls
below the current best value are effectively pruned from consideration.
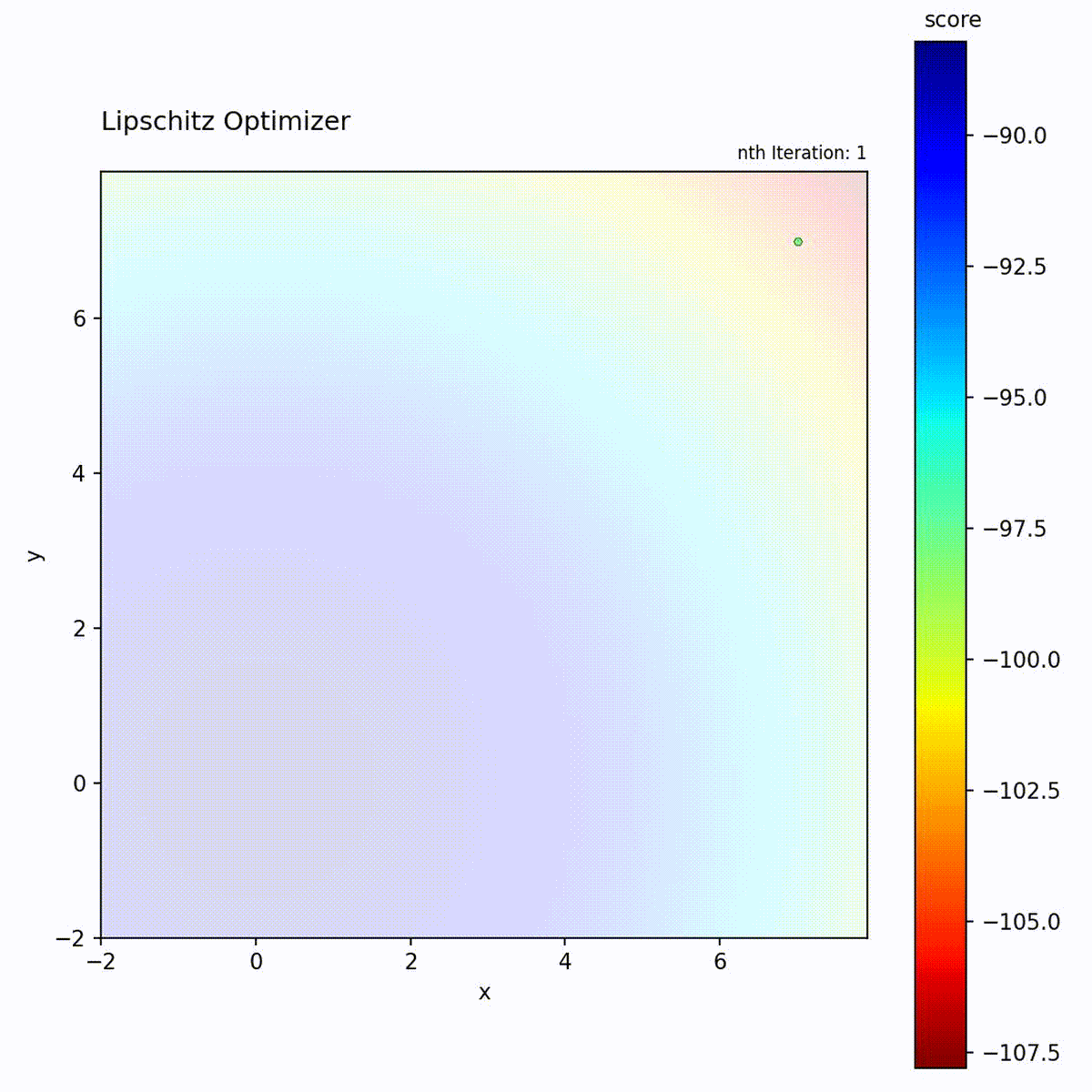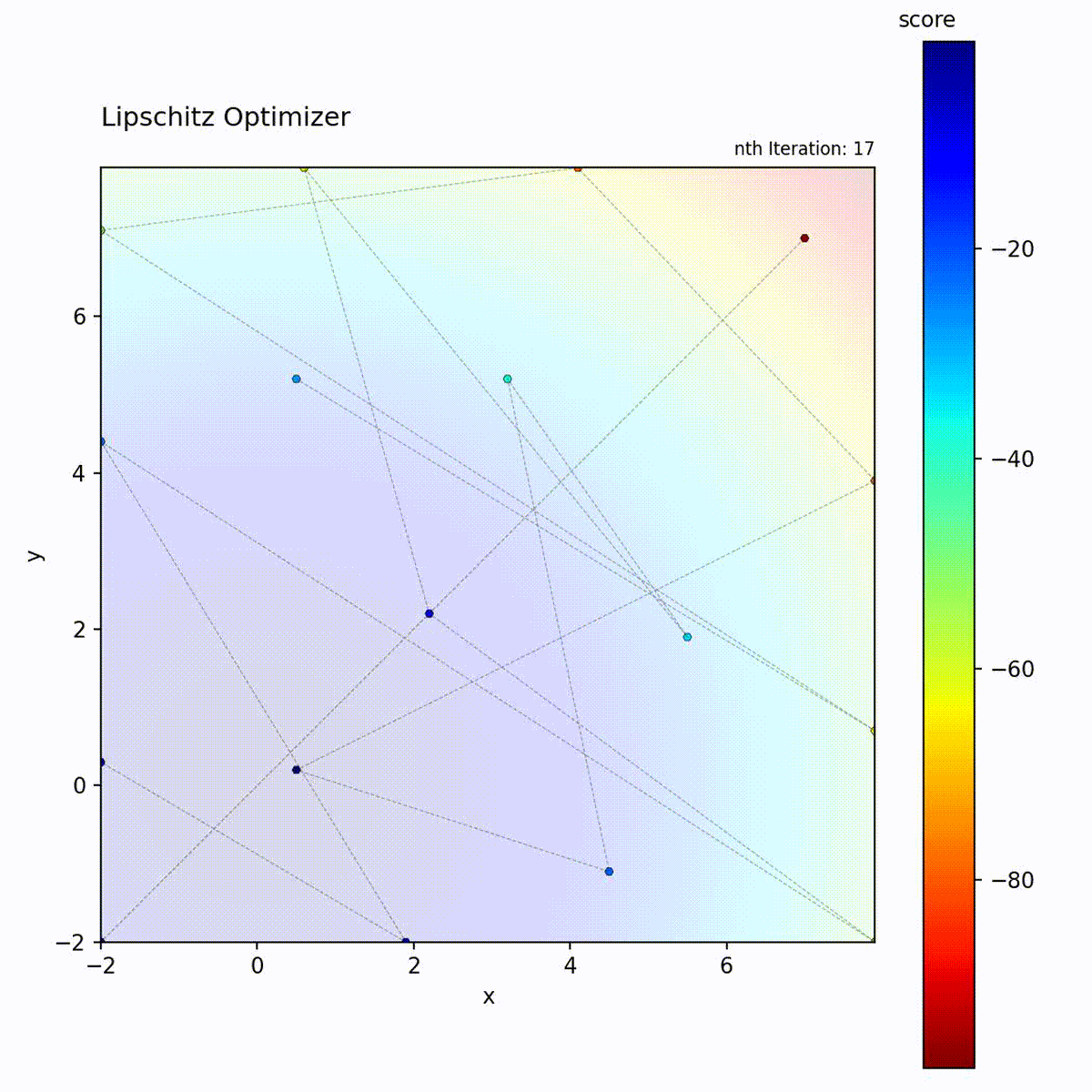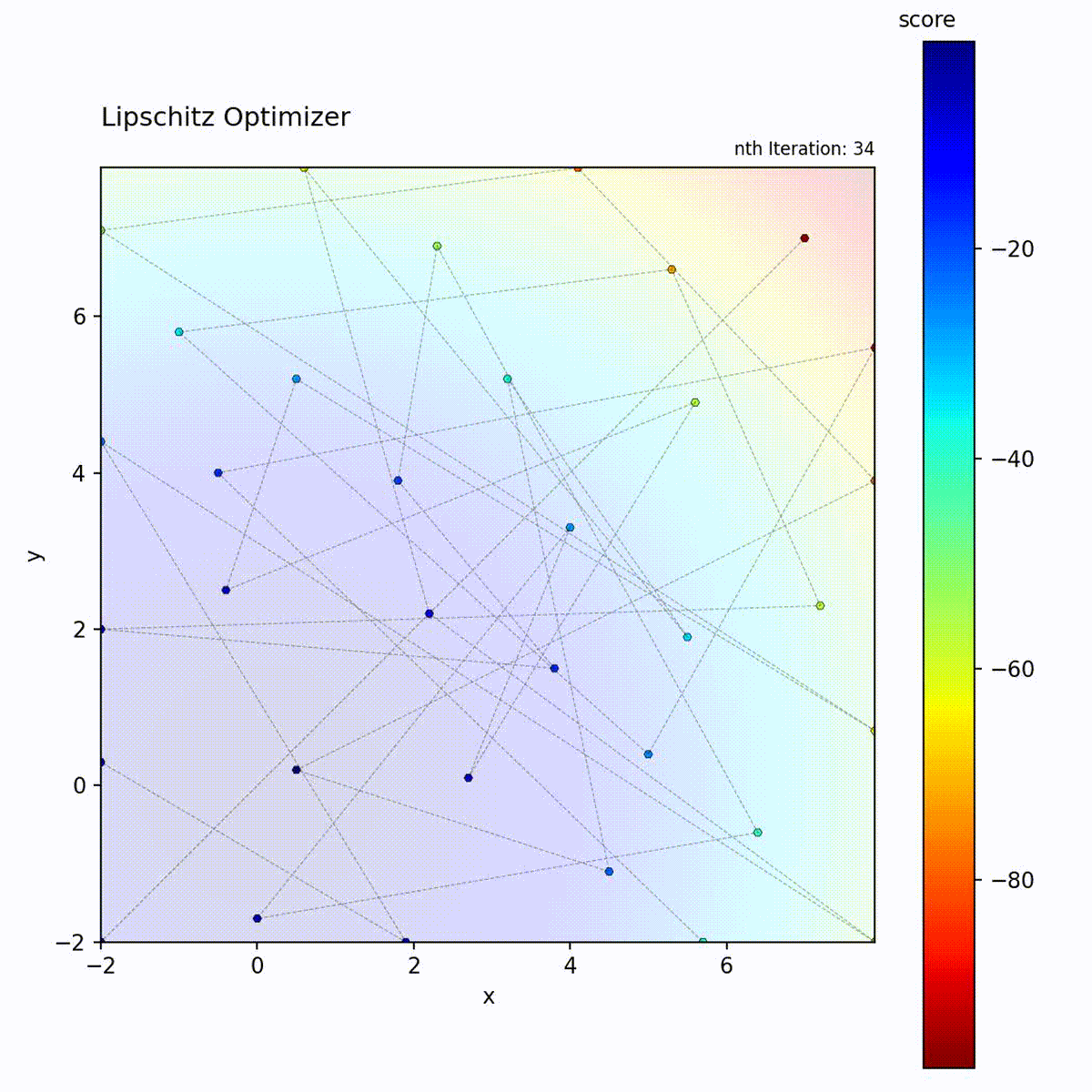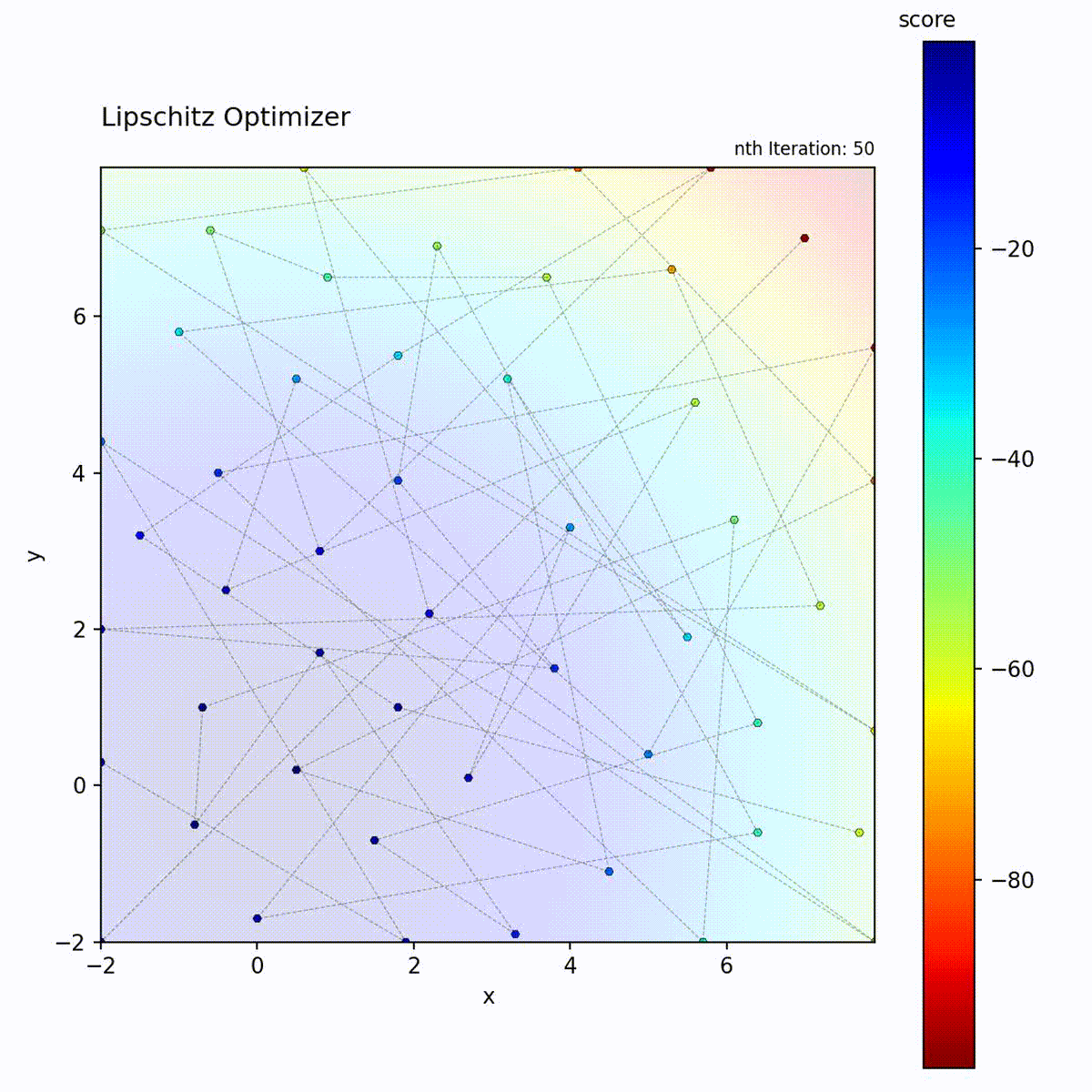
Convex function: Uses bounds to focus search.
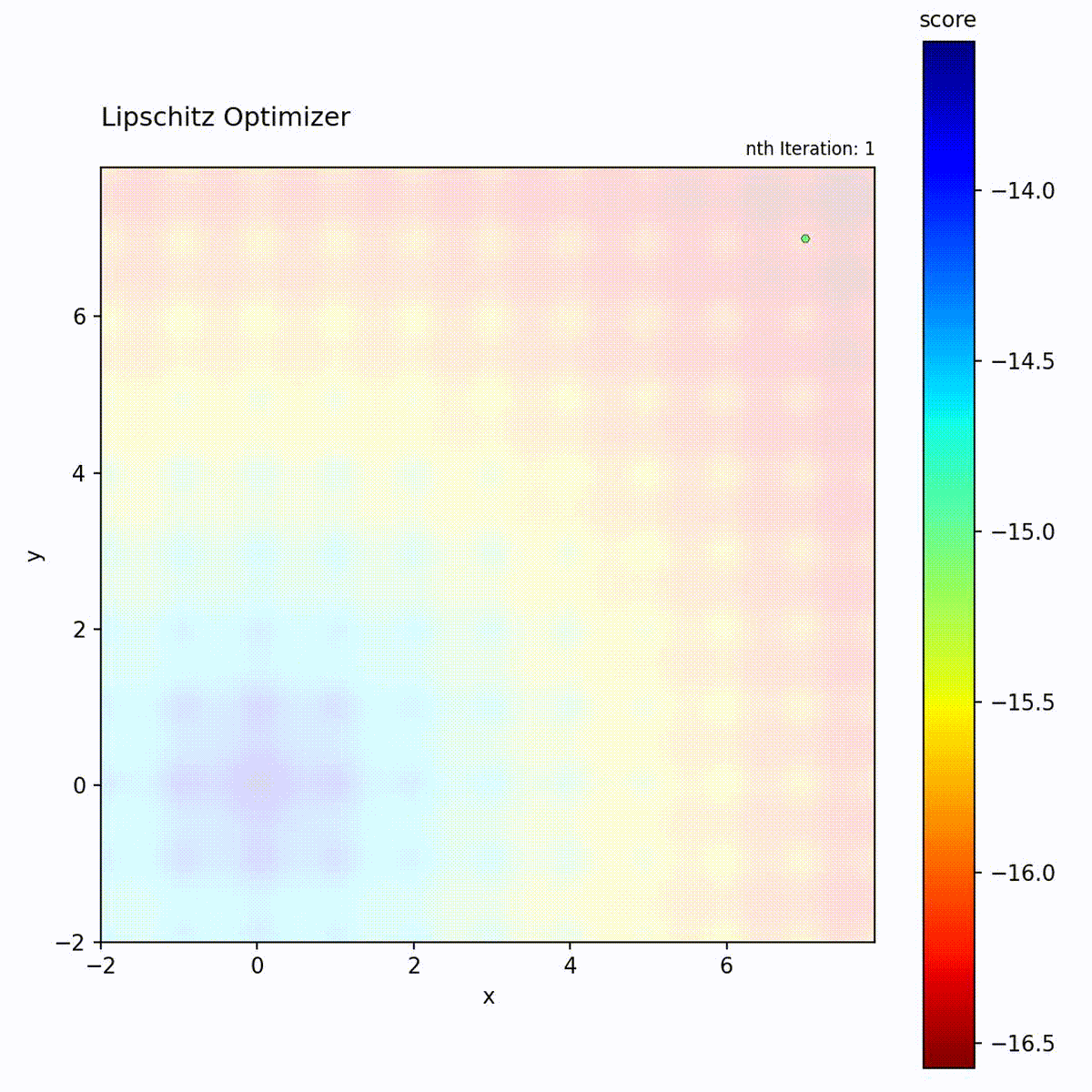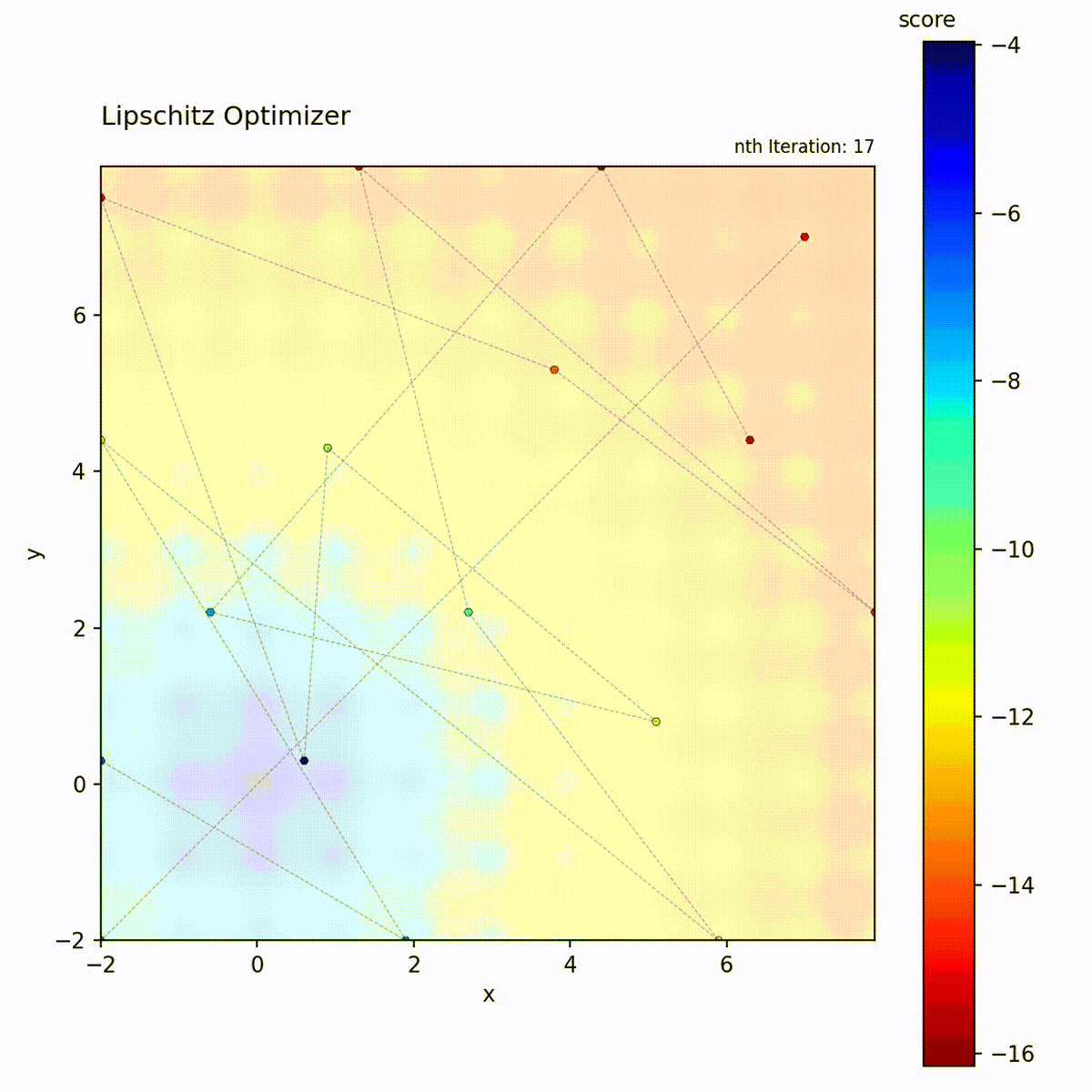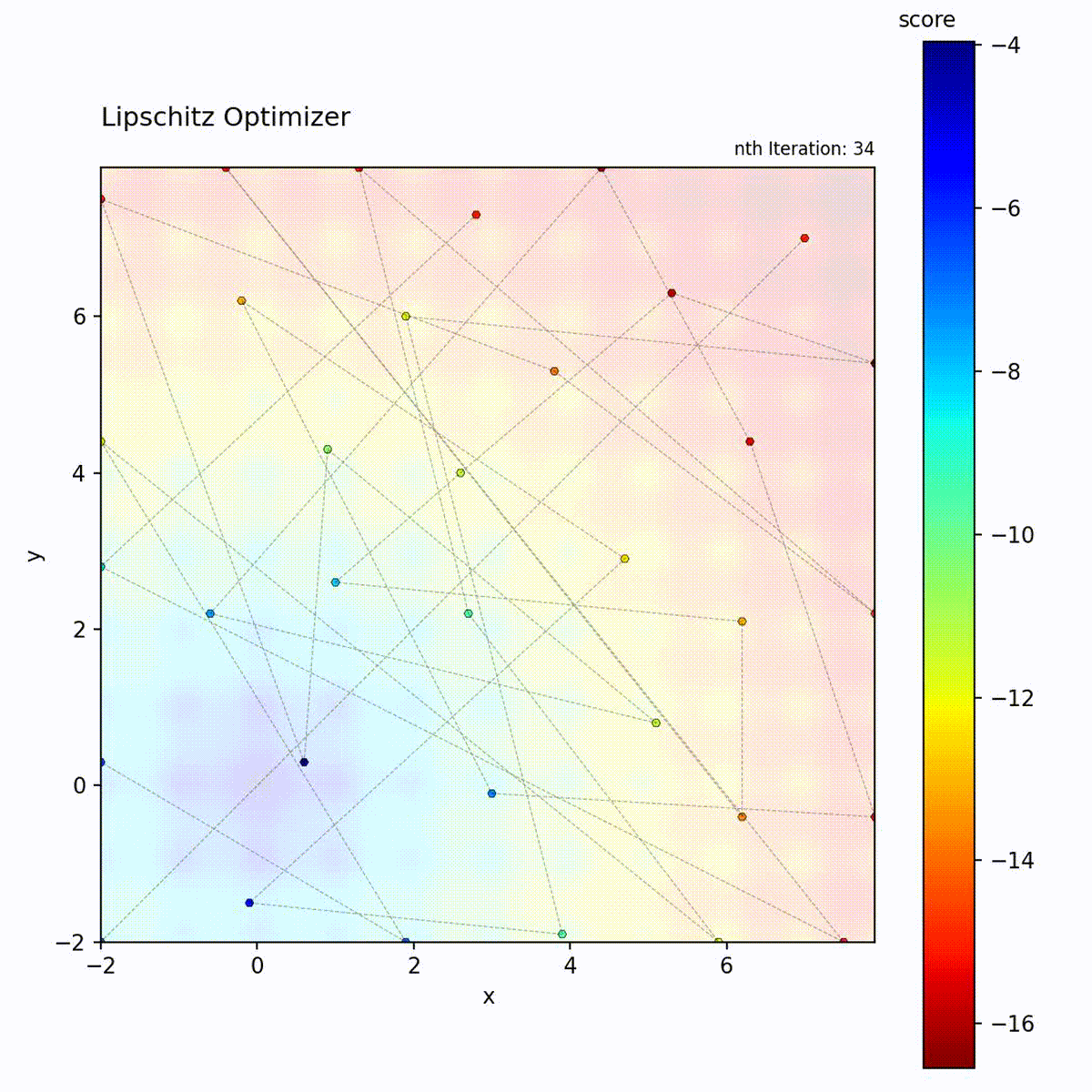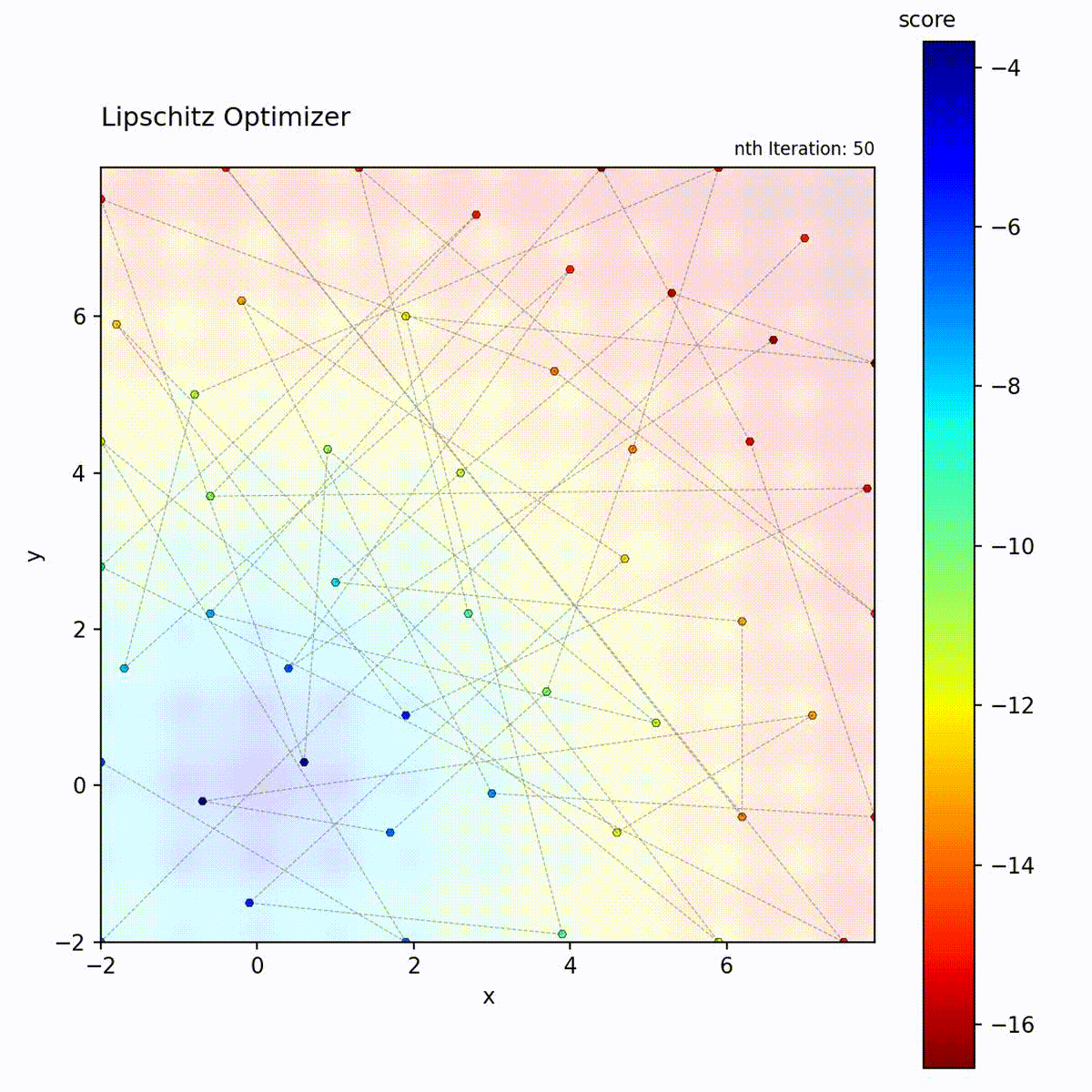
Multi-modal function: Bounds help prune unpromising regions.
The Lipschitz Optimizer is the only algorithm in this library that provides mathematically provable bounds on the objective, rather than relying on heuristic search strategies. This comes at a cost: computing bounds requires comparing each candidate against all previously evaluated points, which introduces significant per-iteration overhead. The algorithm also assumes that the objective is Lipschitz continuous; performance degrades on discontinuous or highly noisy functions where the assumption is violated. Compared to DIRECT, which implicitly considers all possible Lipschitz constants, this optimizer works with a single estimated constant. Choose the Lipschitz Optimizer when function evaluations are expensive enough to justify the overhead and when the objective is known to be smooth.
Algorithm
The Lipschitz condition states that for any two points x and y:
|f(x) - f(y)| <= L * ||x - y||
where L is the Lipschitz constant. This provides upper and lower bounds on function values at unevaluated points.
The algorithm:
Sample candidate points from the search space
For each candidate, compute bounds based on nearby evaluated points
Select the point with the best potential (highest upper bound)
Evaluate and add to the set of observations
Note
The Lipschitz condition provides mathematical bounds on possible function values. If a nearby evaluated point has value v, then any unevaluated point within distance d can have at most value v + L*d. This allows the algorithm to provably rule out regions that cannot contain the global optimum, making it more efficient than random sampling.
Parameters
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
dict |
{“random”: 1000000} |
How many candidate samples to consider |
|
int |
10000000 |
Maximum sample size for efficiency |
Example
import numpy as np
from gradient_free_optimizers import LipschitzOptimizer
def objective(para):
return -(para["x"]**2 + para["y"]**2)
search_space = {
"x": np.linspace(-10, 10, 100),
"y": np.linspace(-10, 10, 100),
}
opt = LipschitzOptimizer(
search_space,
sampling={"random": 100000},
)
opt.search(objective, n_iter=50)
print(f"Best: {opt.best_para}, Score: {opt.best_score}")
When to Use
Good for:
Functions with known or assumed smoothness
When you want theoretical guarantees
Problems where pruning can significantly reduce search space
Not ideal for:
Discontinuous or very noisy functions
Functions with unknown Lipschitz constant
Very cheap function evaluations (overhead may dominate)
Higher-Dimensional Example
import numpy as np
from gradient_free_optimizers import LipschitzOptimizer
def smooth_3d(para):
x, y, z = para["x"], para["y"], para["z"]
return -(x**2 + y**2 + z**2 + 0.5 * np.sin(5 * x) * np.sin(5 * y))
search_space = {
"x": np.linspace(-5, 5, 100),
"y": np.linspace(-5, 5, 100),
"z": np.linspace(-5, 5, 100),
}
opt = LipschitzOptimizer(
search_space,
sampling={"random": 50000},
)
opt.search(smooth_3d, n_iter=100)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Automatically balanced through the upper bound computation. Regions with high potential (either from good nearby values or large unexplored volume) are prioritized.
Computational overhead: High. Computing bounds requires comparing against all previously evaluated points.
Parameter sensitivity: The
samplingparameter controls the resolution of candidate evaluation. More samples give better coverage but higher cost.