Powell’s Method
Powell’s Method decomposes a multidimensional optimization problem into a sequence of one-dimensional line searches along axis-aligned directions. It selects one dimension at a time, optimizes along that axis while holding all other parameters fixed, then moves to the next dimension. After cycling through all dimensions, it repeats. The implementation here uses fixed axis-aligned directions rather than the conjugate direction updates found in some variants.
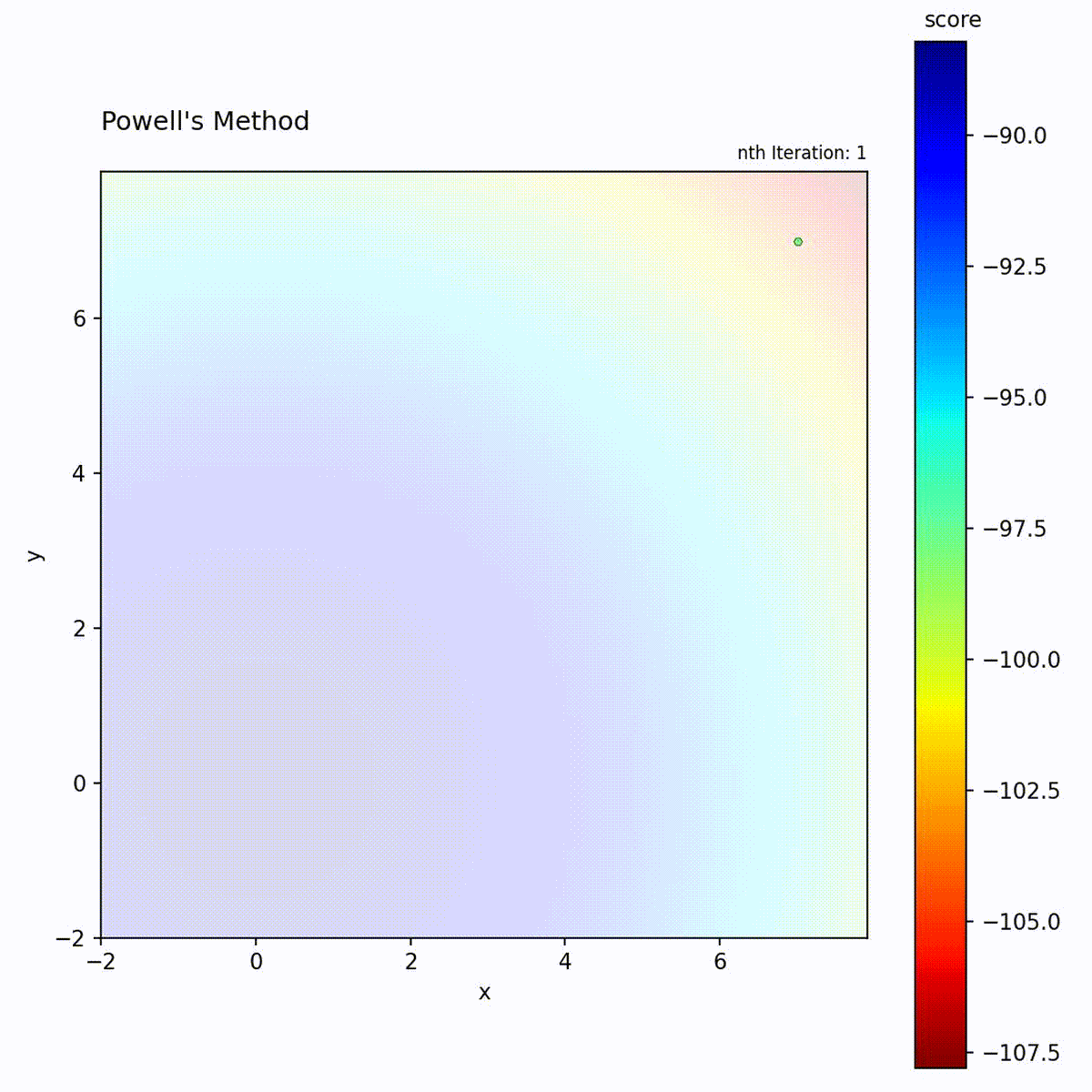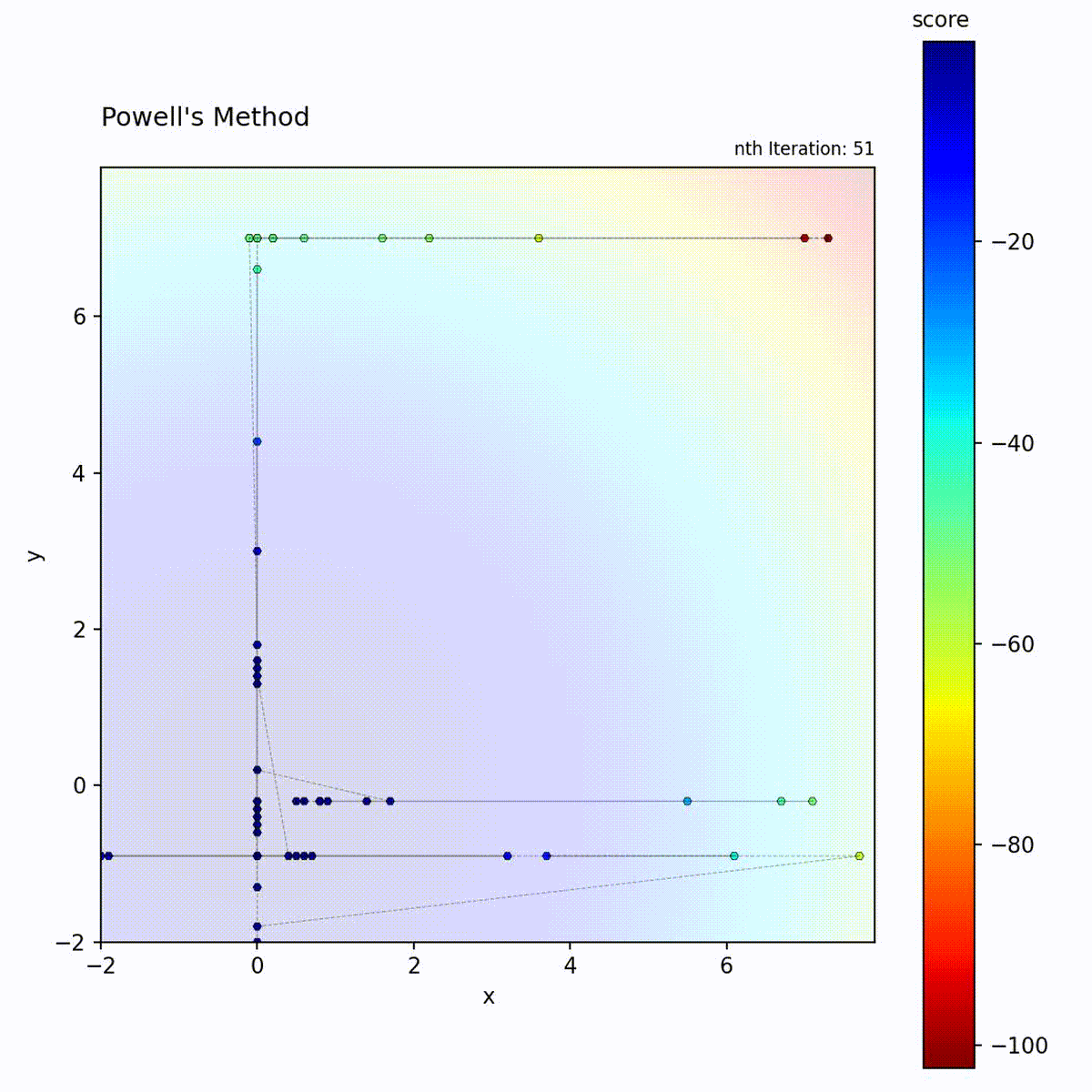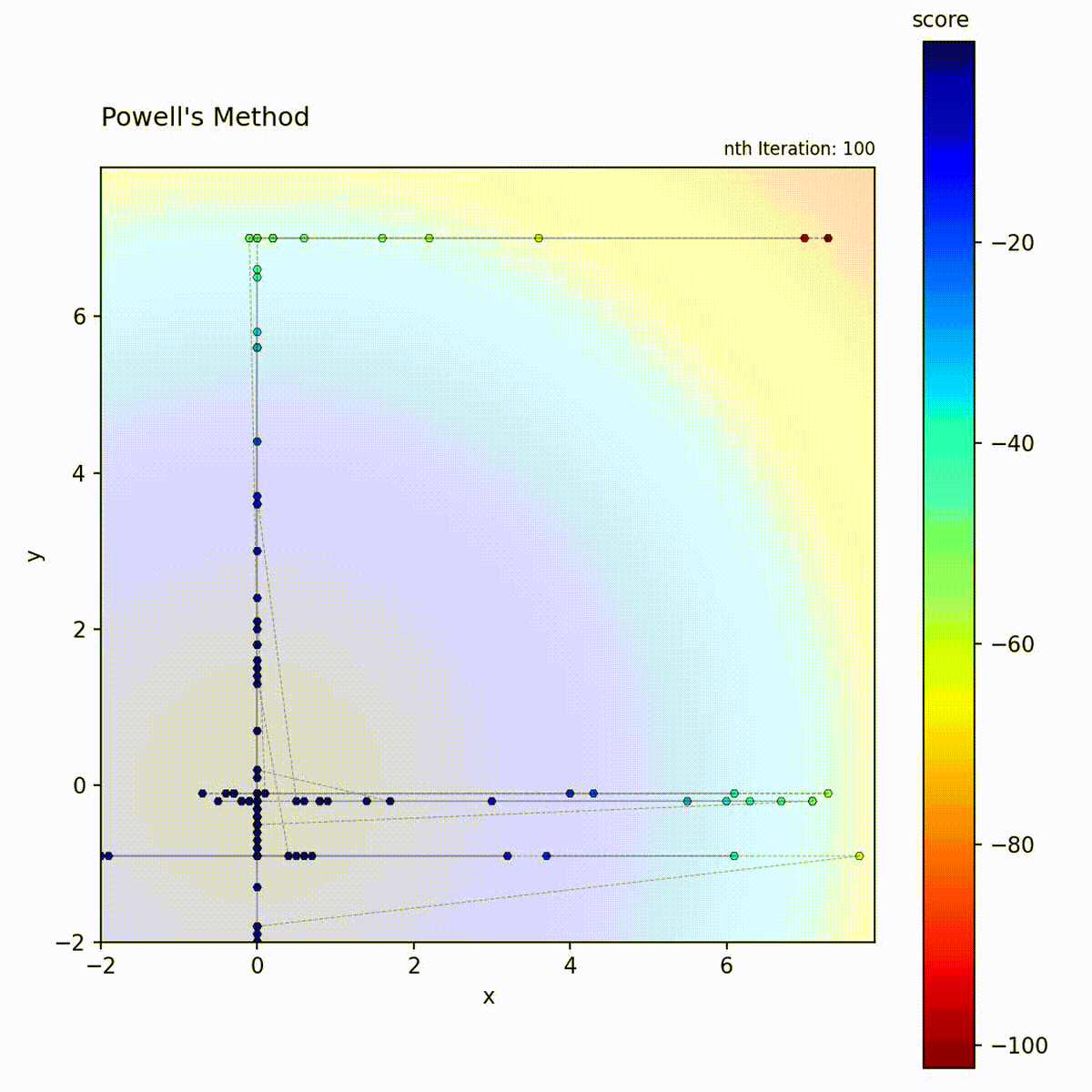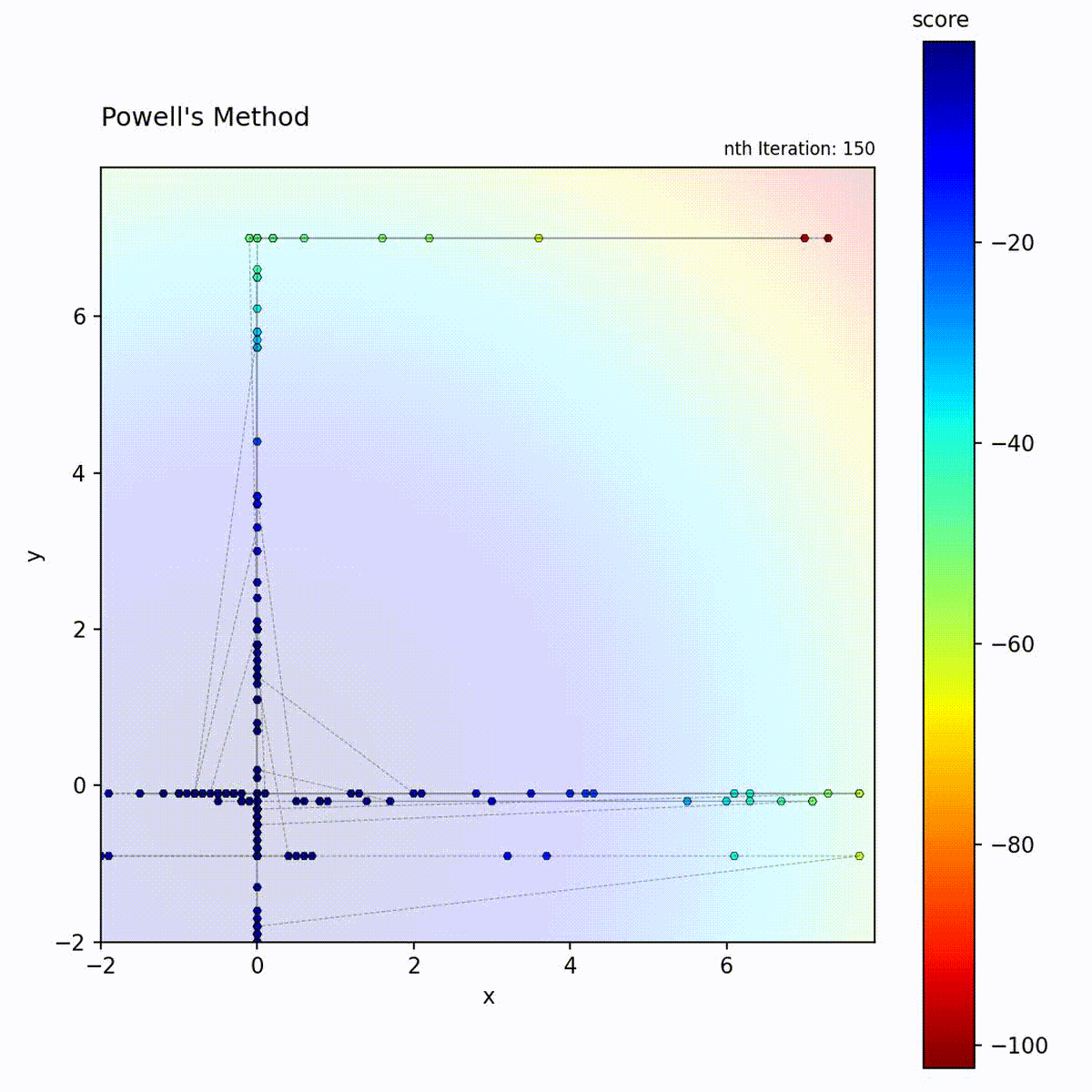
Convex function: Sequential axis-aligned optimization converges efficiently.
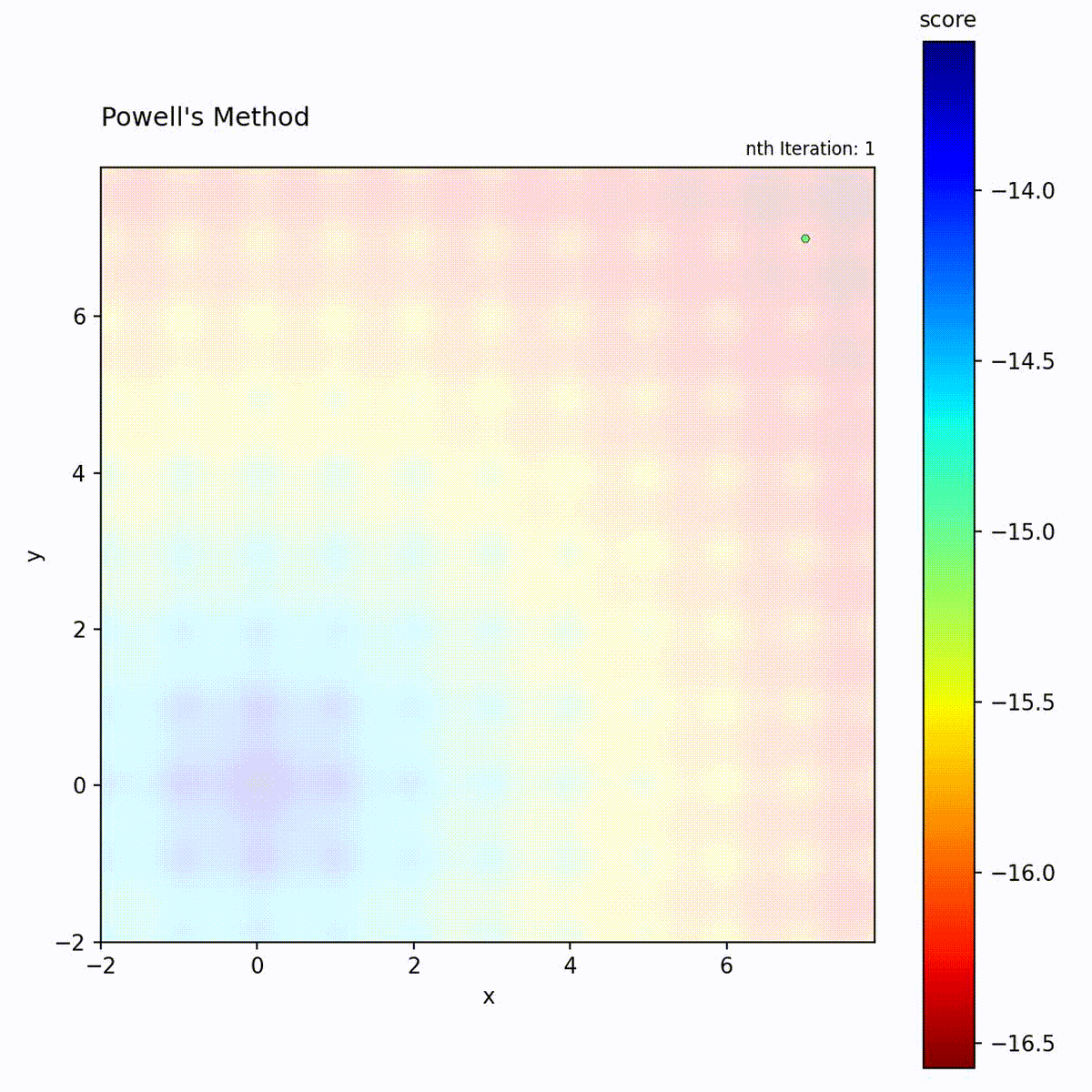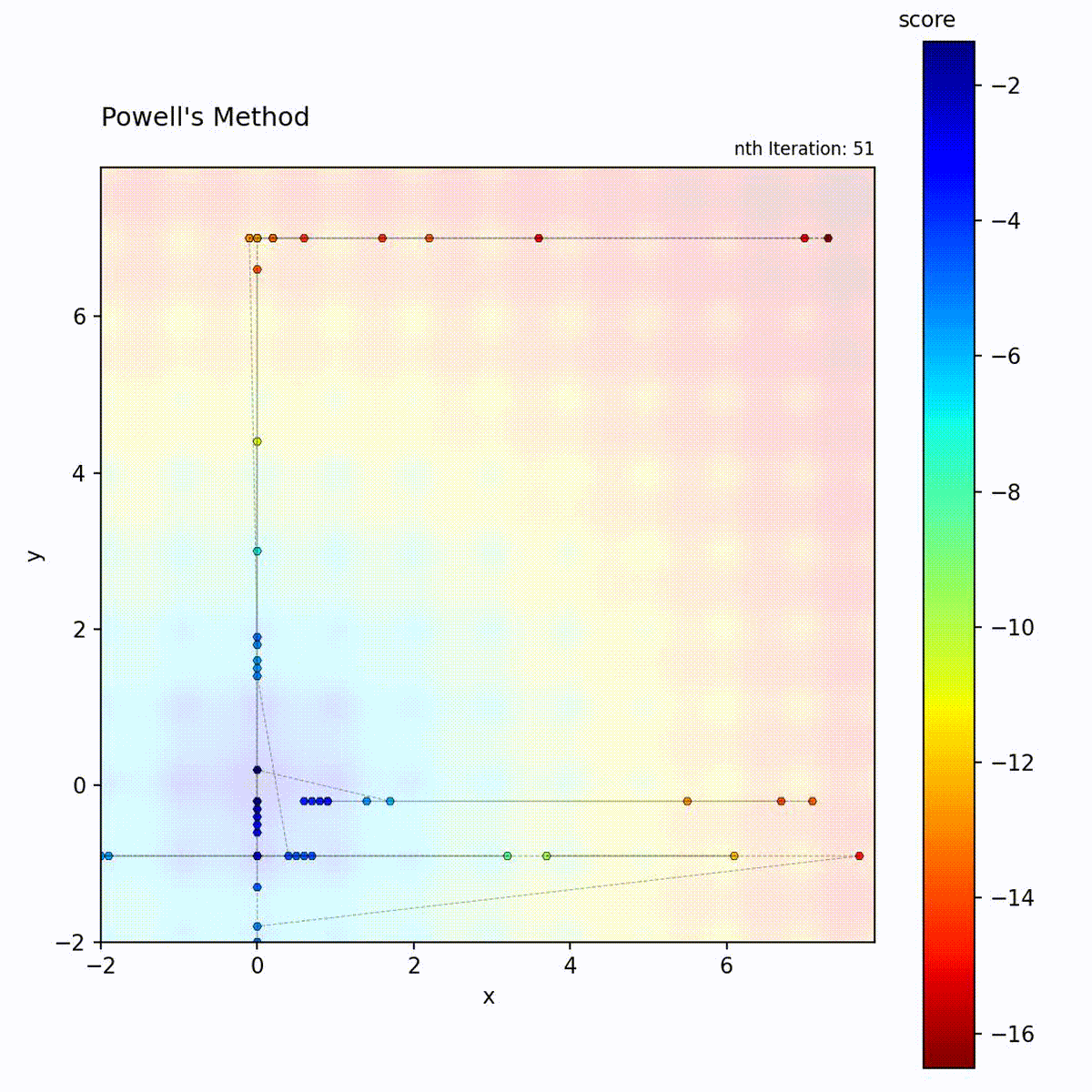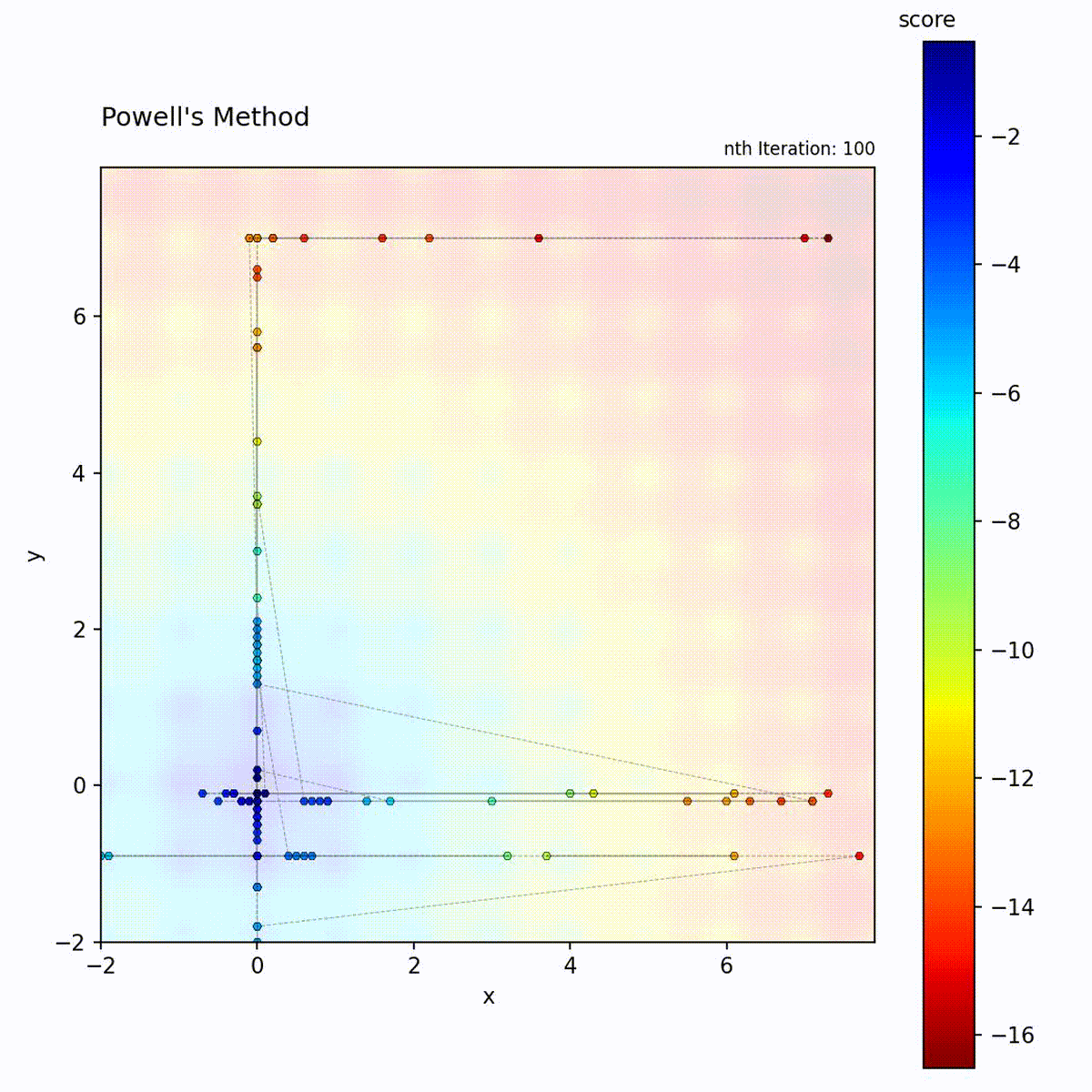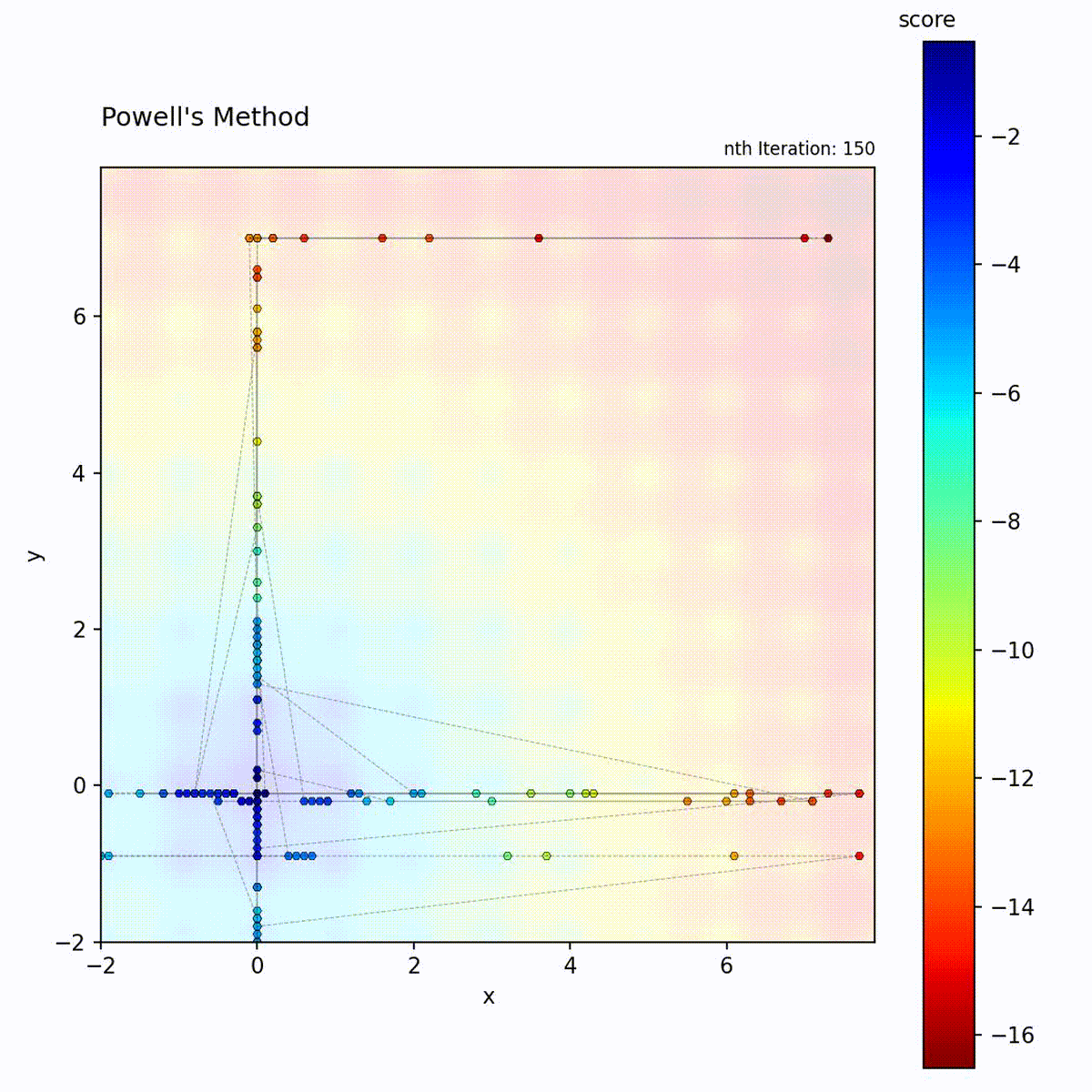
Multi-modal function: Axis-aligned search may miss diagonal optima.
This coordinate-descent approach performs well on separable functions where each
parameter’s optimal value is independent of the others (e.g., f = g(x) + h(y)).
On non-separable functions with strong parameter interactions, convergence degrades
because optimizing one axis at a time cannot follow diagonal paths through the
search space. Compared to Pattern Search, which probes all directions
simultaneously, Powell’s Method evaluates fewer points per cycle but requires
separability to be effective. It has no algorithm-specific hyperparameters. Choose
Powell’s Method when the objective is known or expected to be separable, and prefer
Pattern Search or Downhill Simplex for coupled objectives.
Algorithm
At each iteration:
Select a dimension to optimize
Perform 1D optimization along that dimension (keeping others fixed)
Move to the next dimension
Repeat through all dimensions
for dim in dimensions:
# Line search along dim, others fixed
best_val = line_search(pos, direction=dim)
pos[dim] = best_val
Note
Powell’s Method decomposes an n-dimensional problem into
n sequential 1D optimizations. This works well when dimensions are
independent (separable functions like f = g(x) + h(y)) but fails when
dimensions interact (f = (x + y)^2), because the optimal value of one
dimension depends on the other.
This sequential approach is efficient when dimensions are independent but may struggle with coupled parameters.
When to Use
Good for:
Separable objective functions (dimensions are independent)
Functions where 1D optimization is cheap
Low to moderate dimensional spaces
Not ideal for:
Strongly coupled parameters (e.g.,
score = (x + y)^2)Very high dimensions
Functions with complex interactions between parameters
Example
import numpy as np
from gradient_free_optimizers import PowellsMethod
# Separable function - works well with Powell's Method
def separable(para):
return -(para["x"]**2 + para["y"]**2 + para["z"]**2)
search_space = {
"x": np.linspace(-10, 10, 100),
"y": np.linspace(-10, 10, 100),
"z": np.linspace(-10, 10, 100),
}
opt = PowellsMethod(search_space)
opt.search(separable, n_iter=300)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Separable vs. Non-Separable Functions
# Separable: each dimension can be optimized independently
def separable(para):
return -(para["x"]**2 + para["y"]**2)
# Non-separable: dimensions are coupled
def coupled(para):
return -((para["x"] + para["y"])**2)
For non-separable functions, consider Pattern Search or Downhill Simplex instead.
Higher-Dimensional Separable Example
import numpy as np
from gradient_free_optimizers import PowellsMethod
# Each dimension is independent - ideal for Powell's Method
def sum_of_squares_4d(para):
return -(
para["x"]**2 + 2 * para["y"]**2
+ 3 * para["z"]**2 + 4 * para["w"]**2
)
search_space = {
"x": np.linspace(-10, 10, 200),
"y": np.linspace(-10, 10, 200),
"z": np.linspace(-10, 10, 200),
"w": np.linspace(-10, 10, 200),
}
opt = PowellsMethod(search_space)
opt.search(sum_of_squares_4d, n_iter=500)
print(f"Best: {opt.best_para}")
print(f"Score: {opt.best_score}")
Trade-offs
Exploration vs. exploitation: Purely exploitative along each axis. No mechanism for global exploration.
Computational overhead: Minimal. Each step is a 1D optimization.
Parameter sensitivity: No algorithm-specific parameters to tune. Performance depends entirely on whether the function is separable.